








Introduction
Hello, and welcome to part 2 of our series on porting Detroit: Become Human from PS4 to PC. In Part 1, Ronan Marchalot from Quantic Dream explained why they decided to use Vulkan® and talked about shader pipelines and descriptors. Here in part 2, Lou Kramer from AMD will discuss non-uniform resource indexing on PC and for AMD cards specifically.
Descriptor sets
The extension VK_EXT_descriptor_indexing
became part of core with Vulkan® 1.2. This extension enables applications to select among descriptor sets with dynamic (non-uniform) indexes in the shader. Non-uniform means that the index can have different values across the whole subgroup.
For example, on RDNA, the size of a subgroup is either 32 or 64. All threads in a subgroup, also called lanes, are executed on a single SIMD-unit in parallel. Uniform variables are stored in scalar registers, one single value for all lanes. Non-uniform variables are stored in vector registers, storing a value for each lane individually.
By default, the index for accessing a resource in an array is considered uniform. Let’s look at the following example:
// the descriptor set, an array of 13 resources (textures)
[[vk::binding(0)]] RWTexture2D imgDst[13] :register(u0);
// the threadgroup has 128 lanes so there are in total either 4 or 2 subgroups
// (of size 32 or respectively of size 64)
[numthreads(64,2,1)]
void main(uint3 LocalThreadId : SV_GroupThreadID)
{
// the index that will be used to access an element in the descriptor set
uint index = 0;
// load instruction for the texture at index 0
float4 value = imgDst[index].Load(LocalThreadId.xy);
// store instruction for the texture at index 1
imgDst[index + 1][LocalThreadId.xy] = value;
}The value of the variable index is uniform across all lanes in the single subgroups. In this simple example, it’s 0
and obvious that it’s uniform.
For the purpose of a case study, let’s have a look how a shader compiler handles this kind of code. Specifically, the shader compiler shipped with the Radeon driver 20.5.1 on a Radeon RX 5700 XT generates the following ISA:
Note: Don’t worry, you do not need to understand every single line! Also, every generated ISA presented in this post is based on the same driver and same GPU as stated above. This is subject to change when you use a different driver and GPU.
s_inst_prefetch 0x3
s_getpc_b64 s[0:1]
s_mov_b32 s0, s2
// here we load the descriptor for the texture we want to access:
// the descriptor of texture[0] is loaded to scalar registers s[4:11]
// the descriptors are always stored in scalar registers
// and thus, are uniform across all lanes
s_load_dwordx8 s[4:11], s[0:1], 0x0
s_waitcnt lgkmcnt(0)
// we load from descriptor stored at s[4:11] -> points to texture[0]
image_load v[2:5], v[0:1], s[4:11] dmask:0xf dim:SQ_RSRC_IMG_2D
v_nop
// we load the descriptor of texture[1] into s[0:7]
s_load_dwordx8 s[0:7], s[0:1], 0x20
s_waitcnt vmcnt(0) lgkmcnt(0)
// we write into texture[1]
image_store v[2:5], v[0:1], s[0:7] dmask:0xf dim:SQ_RSRC_IMG_2D unorm glc
s_endpgm
In the above example, index is assigned to a constant value, which is always uniform.
But what if we do not assign a constant value to index? Let’s look at the example below:
[[vk::binding(0)]] RWTexture2D imgDst[13] :register(u0);
[numthreads(64,2,1)]
void main(uint3 LocalThreadId : SV_GroupThreadID)
{
uint index = LocalThreadId.y;
float4 value = imgDst[index].Load(LocalThreadId.xy);
imgDst[index + 1][LocalThreadId.xy] = value;
}Remember, per specification, index must still be uniform – so it holds the same value for every lane in a single subgroup. Is this true in the example?
LocalThreadId.xy
can vary between the lanes. However, on AMD GPUs, the lane index pattern for compute shaders is row major. This means, a threadgroup has either four subgroups with the lane indexes [0,31][0]; [32,63][0]; [0,31][1]; [32,63][1]
or two subgroups with the lane indexes [0,63][0]; [0,63][1]
. Hence, LocalThreadId.y
is uniform across a subgroup.
Lane indexes in a subgroup of size 32:
[0, 31][0]
| [32,63][0]
|
[0, 31][1]
| [32,63][1]
|
Lane indexes in a subgroup of size 64:
[0, 63][0]
|
[0, 63][1]
|
Each cell is one subgroup, with indexes [x][y]
. Note, that for y
, only one value is possible per subgroup as y
is uniform across all lanes of a single subgroup.
As the spec requires the index to be uniform, the compiler can treat index as uniform without confirming this fact. The compiler is allowed to assume the code is conforming to specification. Therefore, the compiler can generate ISA based on the fact that index is uniform.
The ISA is as follows:
s_inst_prefetch 0x3
s_getpc_b64 s[0:1]
// only load the value of gl_LocalInvocationID.y of the first active lane
// as index is considered a uniform value, it must be equal across all lanes
// store it in a scalar register
v_readfirstlane_b32 s0, v1
s_mov_b32 s3, s1
s_lshl_b32 s0, s0, 5
// load the texture descriptor from texture[gl_LocalInvocationID.y-from-first-lane]
s_load_dwordx8 s[4:11], s[2:3], s0
s_add_u32 s0, s0, 32
s_waitcnt lgkmcnt(0)
image_load v[2:5], v[0:1], s[4:11] dmask:0xf dim:SQ_RSRC_IMG_2D
v_nop
s_load_dwordx8 s[0:7], s[2:3], s0
s_waitcnt vmcnt(0) lgkmcnt(0)
image_store v[2:5], v[0:1], s[0:7] dmask:0xf dim:SQ_RSRC_IMG_2D unorm glc
s_endpgm
Note the usage of readFirstLane
– the index for accessing the texture array is loaded as a uniform value. This is totally fine, as we know, that index is in fact uniform. But what happens when we change the threadgroup xy
?
[numthreads(16,8,1)]
Now, LocalThreadId.y
is non-uniform per subgroup – the lane indexes of the subgroup in the threadgroups are:
[0, 15][0, 1]
| [0, 15][2, 3]
| [0, 15][4, 5]
| [0, 15][6, 7]
|
The generated ISA is still the same as above though, it does not depend on the threadgroup size – and thus, the final output would be incorrect! To solve this issue, we must add the NonUniformResourceIndex
keyword (or in GLSL the nonuniformEXT
keyword).
When adding the NonUniformResourceIndex
keyword the code looks as follows:
[[vk::binding(0)]] RWTexture2D imgDst[13] :register(u0);
[numthreads(16,8,1)]
void main(uint3 LocalThreadId : SV_GroupThreadID)
{
uint index = LocalThreadId.y;
float4 value = imgDst[NonUniformResourceIndex(index)].Load(LocalThreadId.xy);
imgDst[NonUniformResourceIndex(index + 1)][LocalThreadId.xy] = value;
} The generated ISA is more complicated, as the compiler cannot assume a uniform value for index anymore and it’s also not an obvious case as in the very first example, where we assigned index to a constant value.
s_inst_prefetch 0x3
s_getpc_b64 s[0:1]
s_mov_b32 s0, s2
v_lshlrev_b32_e32 v2, 5, v1
s_mov_b32 s2, exec_lo
s_mov_b32 s3, exec_lo
s_nop 0
s_nop 0
_L2:
// we still have readfirstlane here, the descriptor is loaded in
// scalar registers. We can’t pick different descriptors
// in parallel, but must pick them one by one
v_readfirstlane_b32 s4, v2
// check if we picked the right descriptor for the lane
// if yes, load from the texture at the picked descriptor
v_cmp_eq_u32_e32 vcc_lo, s4, v2
s_and_saveexec_b32 s5, vcc_lo
// if not right descriptor, skip imageLoad
s_cbranch_execz _L0
BBF0_0:
s_load_dwordx8 s[8:15], s[0:1], s4
s_waitcnt vmcnt(0) lgkmcnt(0)
s_waitcnt_depctr 0xffe3
image_load v[3:6], v[0:1], s[8:15] dmask:0xf dim:SQ_RSRC_IMG_2D
s_andn2_b32 s3, s3, exec_lo
// if we picked right descriptor for the lane,
// jump to the imageStore part
s_cbranch_scc0 _L1
_L0:
// if it was the wrong descriptor, jump back to the beginning
// and pick the descriptor of the first remaining active lane
// loop goes on until no active lanes are remaining for the
// imageLoad instruction
v_nop
s_mov_b32 exec_lo, s5
s_and_b32 exec_lo, exec_lo, s3
s_branch _L2
_L1:
v_nop
s_mov_b32 exec_lo, s2
v_add_nc_u32_e32 v2, 32, v2
s_mov_b32 s2, exec_lo
s_nop 0
s_nop 0
s_nop 0
s_nop 0
_L5:
// do again a ‘waterfall’ loop as before, but now for the descriptors
// used for the imageStore instruction
v_readfirstlane_b32 s3, v2
v_cmp_eq_u32_e32 vcc_lo, s3, v2
s_and_saveexec_b32 s4, vcc_lo
s_cbranch_execz _L3
BBF0_1:
s_load_dwordx8 s[8:15], s[0:1], s3
s_waitcnt vmcnt(0) lgkmcnt(0)
s_waitcnt_depctr 0xffe3
image_store v[3:6], v[0:1], s[8:15] dmask:0xf dim:SQ_RSRC_IMG_2D unorm glc
s_andn2_b32 s2, s2, exec_lo
s_cbranch_scc0 _L4
_L3:
v_nop
s_mov_b32 exec_lo, s4
s_and_b32 exec_lo, exec_lo, s2
s_branch _L5
_L4:
s_endpgm What is happening here? The compiler makes sure to add the logic for iterating through all the lanes until every lane has the correct index. This is also called ‘waterfall’, if you ever stumble over that term 
For each unique index, we would go through one more loop iteration. In the case with [numthreads(16,8,1)]
we need two iterations to cover all cases. For example, for the first threadgroup one iteration for LocalThreadId.y == 0
, and the other iteration for LocalThreadId.y == 1
.
For the case with the thread group size of [numthreads(64,2,1)]
it’s in fact just one iteration.
Both cases produce the correct output with above generated ISA, but with [numthreads(64,2,1)]
, the logic for iterating through the different values of index is unnecessary because there is only one possible value for index per subgroup.
To remove the loop, the compiler must know in advance that there is only one unique value for index per subgroup. The complexity to do this depends on the specific case. Also, there are cases where the compiler is simply not able to determine if a value is uniform or non-uniform.
The take-away points until now are the following:
Add the non-uniform qualifier where it is needed, otherwise you could see corruptions or other bad things might happen. A missing
NonUniformResourceIndexkeyword for non-uniform indexes is violating the spec.Adding the non-uniform qualifier to all texture accesses can substantially degrade performance on some hardware.
Implicit derivatives
In fragment shaders, texture access that needs to determine the correct Level of Detail, or uses anisotropic filtering, relies on the calculation of implicit derivatives. The derivatives are computed based on the values across a 2×2 group of fragment shaders (a quad) for the current primitive.
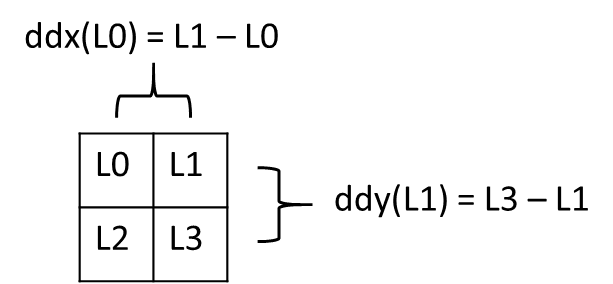


Porting Detroit: Become Human from PlayStation® 4 to PC – Part 1
Porting the PS4® game Detroit: Become Human to PC presented some interesting challenges. This first part of a joint collaboration from engineers at Quantic Dream and AMD discusses the decision to use Vulkan® and talks shader pipelines and descriptors.

Porting Detroit: Become Human from PlayStation® 4 to PC – Part 3
The final part of this joint series with Quantic Dream discusses shader scalarization, async compute, multithreaded render lists, memory management using our Vulkan Memory Allocator (VMA), and much more.





