



Compaction is a basic building block of many algorithms – for instance, filtering out invisible triangles as seen in Optimizing the Graphics Pipeline with Compute. The basic way to implement a compaction on GPUs relies on atomics: every lane which has an element that must be kept increments an atomic counter and writes into that slot. While this works, it’s inefficient as it requires lots of atomic operations – one par active lane. The general pattern looks similar to the following pseudo-code:
if (threadId == 0) {
sharedCounter = 0;
}
barrier ();
bool laneActive = predicate (item);
if (laneActive) {
int outputSlot = atomicAdd (sharedCounter, 1);
output [outputSlot] = item;
}
This computes an output slot for every item by incrementing a counter stored in Local Data Store (LDS) memory (called Thread Group Shared Memory in Direct3D® terminology). While this method works for any thread group size, it’s inefficient as we may end up with up to 64 atomic operations per wavefront.
With shader extensions, we provide access to a much better tool to get this job done: GCN provides a special op-code for compaction within a wavefront – mbcnt. mbcnt(v) computes the bit count of the provided value up to the current lane id. That is, for lane 0, it simply returns popcount (v & 0), for lane 1, it’s popcount (v & 1), for lane 2, popcount (v & 3), and so on. If you’re wondering what popcount does – it simply counts the number of set bits. The popcount result gives us the same result as the atomic operation above – a unique output slot within the wavefront we can write to. This leaves us with one more problem – we need to gather the laneActive variable which is per-thread across the whole wavefront.
We’ll need a short trip into the GCN execution model to understand how this works. In GCN, there’s a scalar unit and a vector unit. Any kind of comparison which is performed per-lane writes into a scalar register with one bit per lane. We can access this scalar register using ballot – in this case, we’re going to call mbcnt (ballot (laneActive)). The complete shader looks like this:
bool laneActive = predicate (item);
int outputSlot = mbcnt (ballot (laneActive));
if (laneActive) {
output [outputSlot] = item;
}
Much shorter than before, and also quite a bit faster. Let’s take a closer look how this works. In the image below, we can see the computation for one thread. The input data is green where items should be kept. The ballot output returns a mask which is 1 if the thread passed in true and 0 otherwise. This ballot mask is then AND’ed together during the mbcnt with a mask that has 1 for all bits less than the current thread index, and 0 otherwise. After the AND, mbcnt computes a popcount which yields the correct output slot.
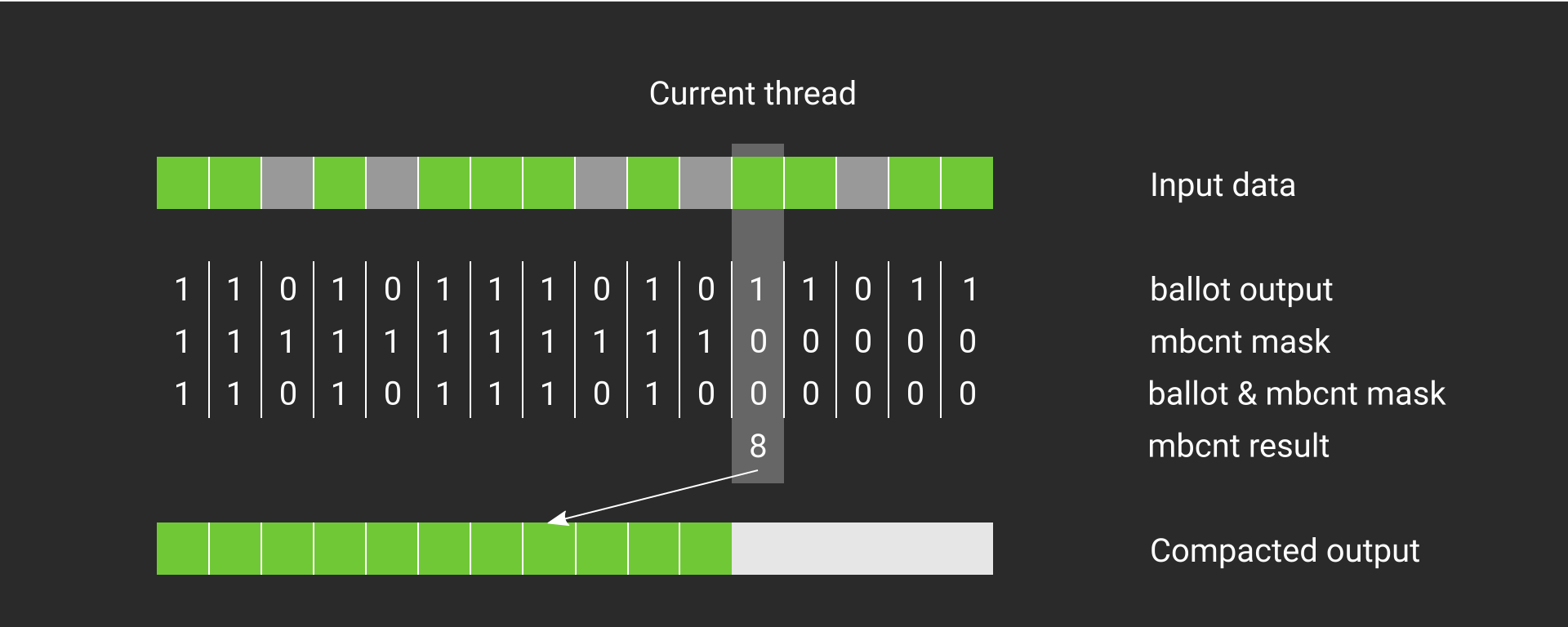
mbcnt. The currently active thread is highlighted. For this thread, mbcnt applied onto the output of ballot returns the output slot that should be used during compaction.Notice that this piece of code will be only equivalent if your dispatch size is 64. For other sizes, you’ll need an atomic per wavefront – which cuts down the number of atomics by 64 compared to the naive approach. The pattern you’d use looks like this:
if (wavefrontThreadId == 0) {
sharedCounter = 0;
}
barrier ();
bool laneActive = predicate (item);
int outputSlot = mbcnt (ballot (laneActive));
if (wavefrontThreadId == 0) {
sharedWavefrontOutputSlot = atomicAdd (sharedCounter,
popcount (ballot (laneActive)));
}
barrier ();
if (laneActive) {
output [sharedWavefrontOutputSlot + outputSlot] = item;
}
And finally, if you are going over the data with multiple thread groups, you’ll need a global atomic as well. In this case, the pattern looks as follows (assuming globalCounter has been cleared to zero before the dispatch starts):
if (wavefrontThreadId == 0) {
sharedCounter = 0;
}
barrier ();
bool laneActive = predicate (item);
int outputSlot = mbcnt (ballot (laneActive));
if (wavefrontThreadId == 0) {
sharedWavefrontOutputSlot = atomicAdd (sharedCounter,
popcount (ballot (laneActive)));
}
barrier ();
// This is a shared variable as well. readlane is not sufficient, as
// we need to communicate across all invocations
if (workgroupThreadId == 0) {
sharedSlot = atomicAdd (globalCounter, sharedCounter);
}
barrier ();
if (laneActive) {
output [sharedWavefrontOutputSlot + outputSlot + sharedSlot] = item;
}
The “big picture” can be seen below. Depending on the level you’re working on, you should use the right atomics. At the global level, where you need to synchronize between work groups, you have to use global memory atomics. At the work group level, where you need to synchronize between wavefronts, local atomics are sufficient. Finally, at the wavefront level, you should take advantage of the wavefront functions like mbcnt.
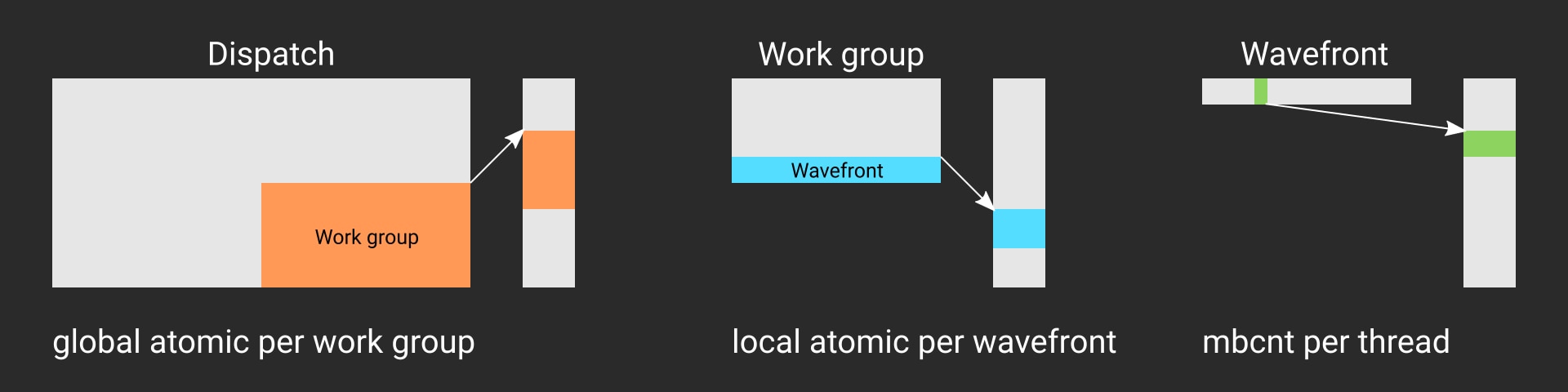
mbcnt is the faster function.If you want to try this out right now – we’ve got you covered and have a sample prepared for you!

Vulkan® mbcnt Sample
This sample shows how to use the AMD_shader_ballot extension and mbcnt to perform a fast reduction within a wavefront.







