Getting Started
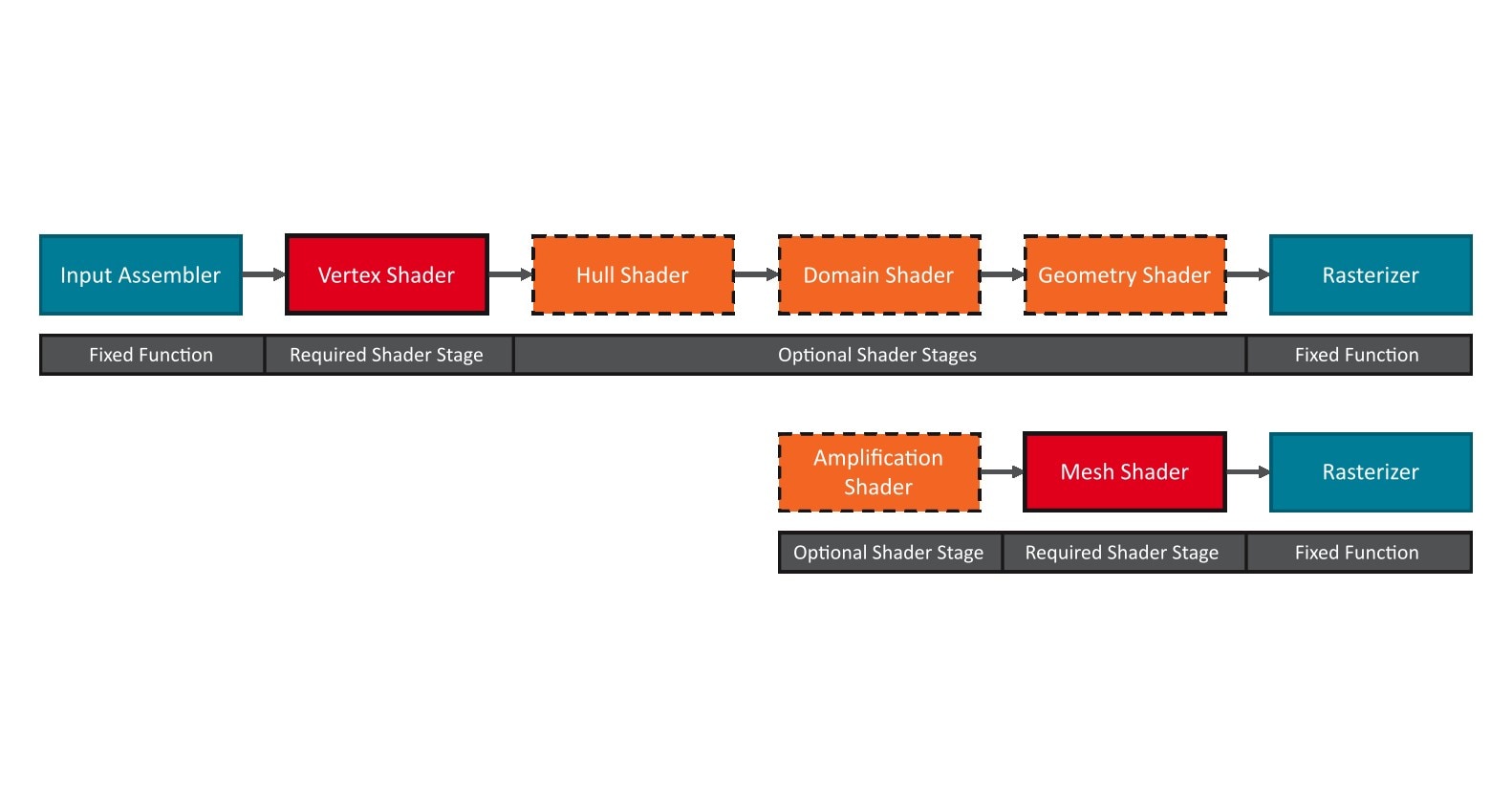
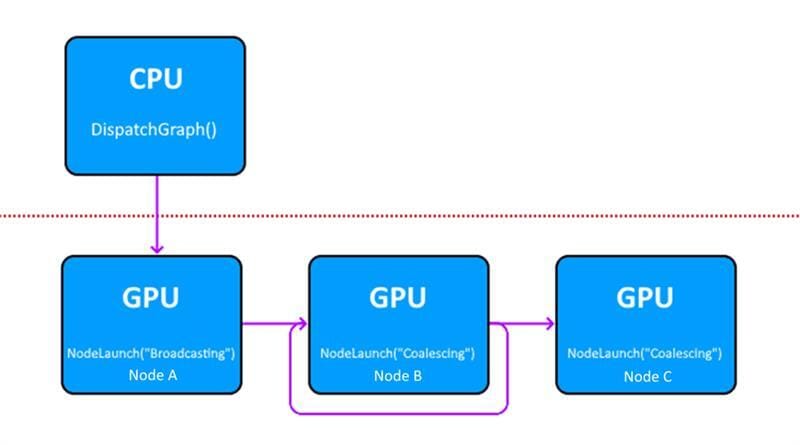
Find out what you need to get started with Work Graphs for DirectX 12, including the software required, configuration, compiling, and more.
Explore our continually-growing library of technical blogs, written by AMD engineers and guest game developers. Benefit from their valuable experience covering general development techniques, developing with AMD hardware, ray tracing, HPC, ML, Vulkan®, DirectX®, Unreal Engine®, and lots more.
Don’t forget – you can find blog posts related specifically to our tools, SDKs, and effects in our software blogs.
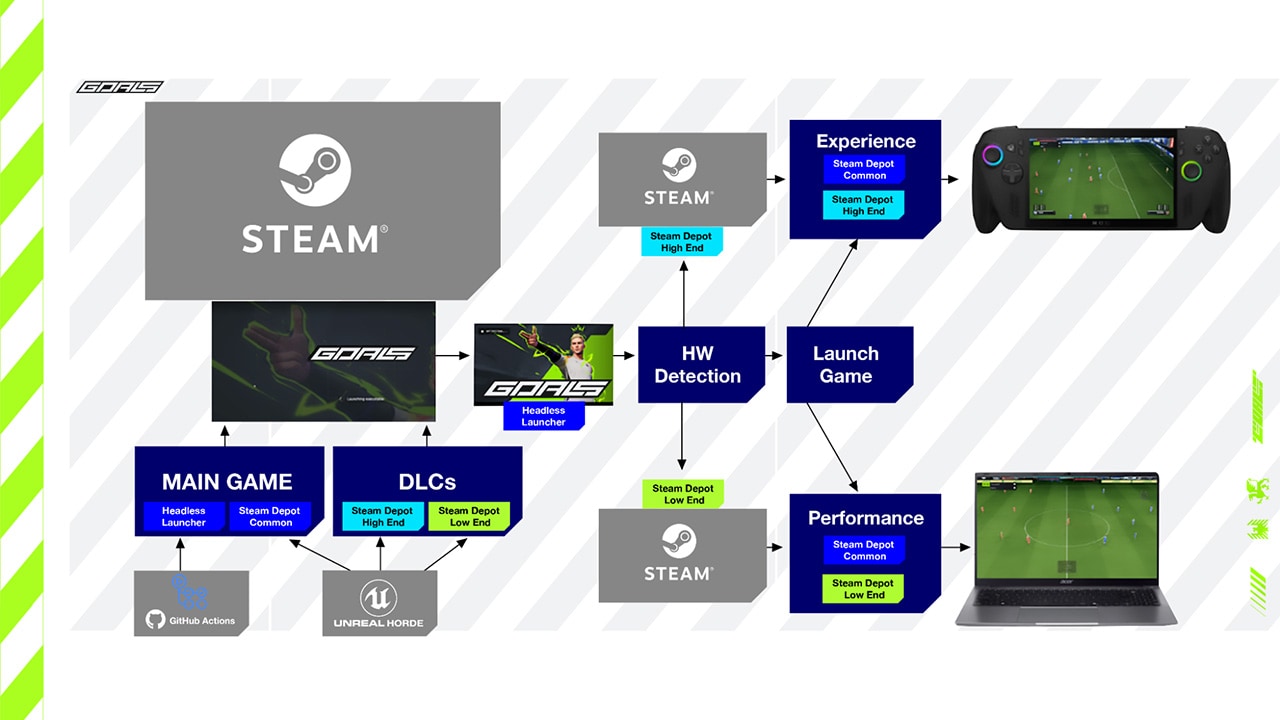 | How GOALS delivers sustained, competitive esports performance on handheld PCs - part 1The first part of a developer-first look at how GOALS leverages AMD Ryzen APUs and the ADLX SDK to implement a system that reduces power, fan noise and carbon footprint across legacy and handheld hardware while preserving competitive performance. |
 | How GOALS delivers sustained, competitive esports performance on handheld PCs - part 2The second part of how GOALS optimizes AMD Ryzen handheld PC gaming performance using AMD FSR Upscaling and Frame Generation, handcrafted device profiles, football-aware animation budgeting, and battery-aware scalability for sustained play. |
 | Driving the future: frictionless automotive HMI development with Epic Games & AMD Ryzen AI Embedded P100 seriesAt CES 2026 Epic Games and AMD unveiled the Unreal Engine 5 Next‑Gen HMI Experience powered by AMD Ryzen AI Embedded P100 Series, unifying instrument clusters, maps, and apps into a single high‑performance UE5 instance with gaming‑class graphics, and a streamlined developer workflow to deliver customizable, 60 FPS in‑cockpit experiences. |
 | HIP Threads: GPU power for teams without GPU expertsHIP Threads lets C++ teams eliminate CPU hotspots by running familiar multithreaded code on AMD GPUs, no kernel rewrites or GPU expertise required, delivering real speedups in days. |
 | Dyson Sphere Program - new multithreading dev log & full AMD Ryzen Threadripper PRO breakdownYouthcat Games overhauled the Dyson Sphere Program game's multithreading system, boosting performance by up to 88% through custom core binding, dynamic task allocation, and enhanced thread synchronization. |