| Ray tracing massive amounts of animated geometry using tetrahedral cagesAnimate compact tetrahedral cages and reuse static mini-BLASes to ray-trace hundreds of millions of triangles in real time, dramatically cutting per-frame update and memory costs for dense foliage, grass, and crowds. |
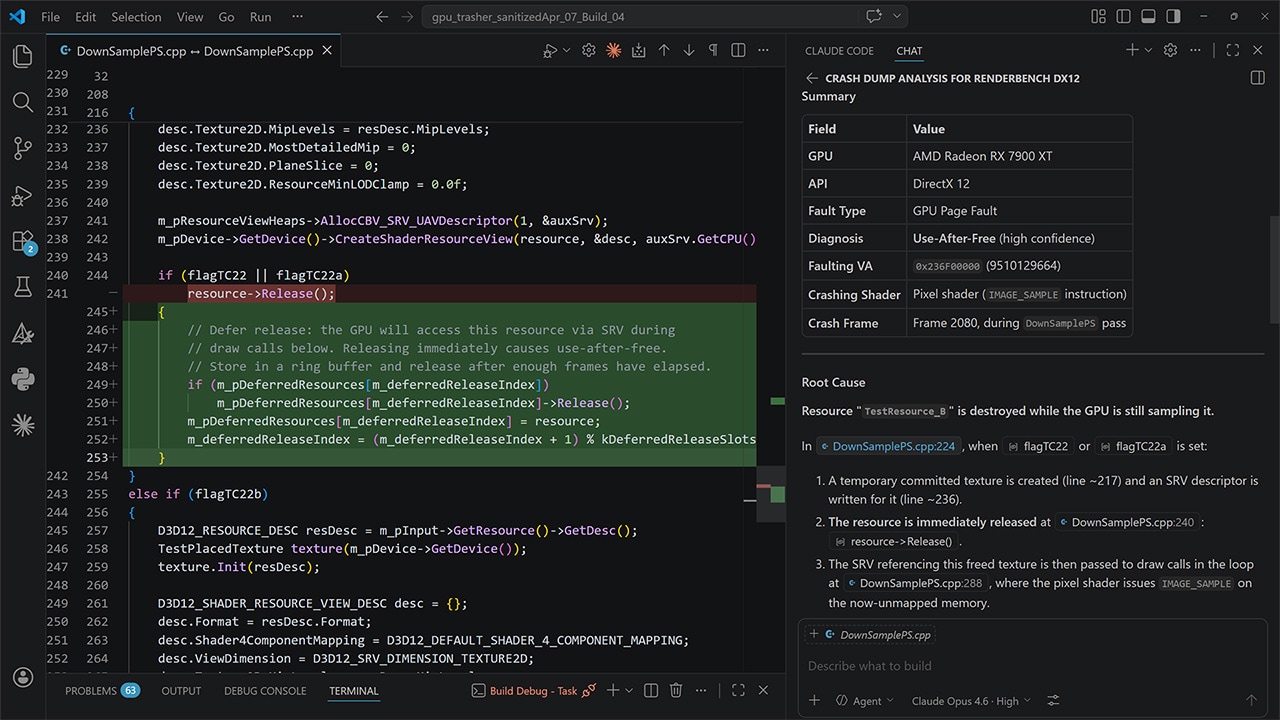 | Post-mortem GPU crash debugging with LLMsThe new AMD RGD MCP Server connects LLM agents to AMD's GPU crash analysis pipeline, turning a single prompt into root-cause analysis and source-code fix suggestions. |
 | AMD FSR Upscaling 4.1 RDNA 3 Support Now Available in FSR SDK 2.3 UpdateAMD FSR "Redstone" SDK 2.3 brings ML-powered FSR Upscaling 4.1.1 to AMD Radeon RX 7000 Series GPUs, along with Frame Generation 4.0.1 and Ray Regeneration 1.2 improvements for RDNA 4 GPUs. |
 | New AMD Radeon Developer Tool Suite update brings shader source code, Extended PIX Markers, and command-line captureThe new AMD Radeon Developer Tool Suite release delivers RGP 2.7 with shader source code viewing, instruction‑level divergence metrics, and Extended PIX Marker support, expanded hardware compatibility, and updates across RGD, RRA, RMV, RGA, and RDP. |
 | WMMA guide for AMD RDNA 4 architecture GPUs - part 3Learn how to implement fast in-register matrix transpose on AMD RDNA™ 4 architecture GPUs with a WMMA-based identity trick, delivering a lightweight, memory-free alternative proven in Llama.cpp. |
 | WMMA guide for AMD RDNA 4 architecture GPUs - part 2Achieve peak AMD RDNA™ 4 architecture memory bandwidth for low-precision GEMM by fusing WMMA to double the K dimension, enabling 128-bit loads for FP8/INT8, and matching hipBLAS results bit-for-bit. |
 | WMMA guide for AMD RDNA 4 architecture GPUs - part 1Practical guide to fusing GEMMs on AMD RDNA™ 4 architecture, covering WMMA layout, a transpose-by-swapping A/B technique, HIP sample code, and hipBLAS-verified results used in Llama.cpp. |
 | Announcing AMD Schola v2.1: state trees, scale, and a richer training stackAMD Schola v2.1 deepens Unreal Engine integration, adding StateTree support, Kubernetes-oriented distributed training, stronger Minari workflows, and much more to streamline training and inference at scale. |
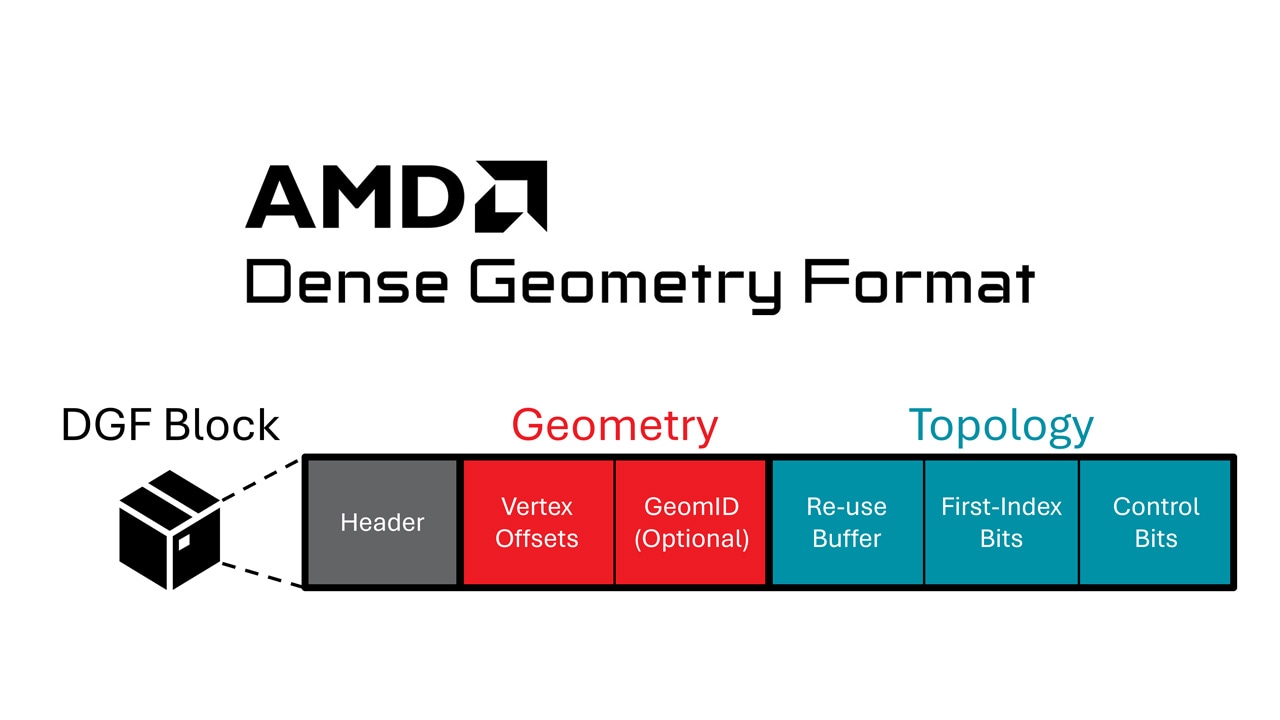
 | AMD DGF: An Open Geometry Compression StandardAMD is partnering with Samsung on a multivendor Vulkan extension for Dense Geometry Format (DGF) to help enable dramatically smaller geometry, reduced memory/latency for ray-traced real‑time 3D, and easier engine integration. |
 | Introducing AMD DGF SuperCompressionAMD DGF SuperCompression (DGFS) cuts DGF geometry file sizes while preserving exact block reconstruction and enabling fast decode to either DGF blocks or conventional meshlets for cross-device deployment. |