AMD FidelityFX™ Hybrid Shadows sample
This sample demonstrates how to combine ray traced shadows and rasterized shadow maps together to achieve high quality and performance.
Performance Guide
Optimizing a modern real-time renderer can be a somewhat daunting task. Explicit APIs hand you more control over how you craft your frame than ever before, allowing you to achieve higher frame rates, prettier pixels, and ultimately, better use of the hardware.
Our AMD RDNA™ Performance Guide, with updates for RDNA 3, will help guide you through the optimization process with a collection of tidbits, tips, and tricks which aim to support you in your performance quest.
Many of our performance suggestions on this page are available through Microsoft® PIX and Vulkan®‘s Best Practice validation layer.
| DirectX® 12 | Vulkan® |
|---|---|
| If you’re a DirectX® 12 developer, you’ll find many AMD-specific checks are already incorporated into the Microsoft® PIX performance tuning and debugging tool. | If you’re a Vulkan® developer, from version 1.2.189 of the SDK onwards, you’ll find AMD-specific checks incorporated into the Best Practice validation layer. |
Command buffers are the heart of the low-level graphics APIs. Most of the CPU time spent in DirectX®12 (DX12) and Vulkan® will be spent recording draws into the command buffers. One of the biggest optimizations is that an application can now multi-thread command buffer recording.
With the previous generation of APIs, the amount of multi-threading that could be done was severely limited to what the driver could muster up.
Low level APIs allow multi-threading of command buffer generation. Using this can get better CPU utilization than higher-level APIs.
The driver does not spawn extra threads for low level APIs. Applications are responsible for multi-threading.
Avoid having too many small command buffers.
Command allocators are not thread safe.
It is recommended to have a command allocator for each thread recording commands per frame.
The number of command allocators should be greater than (or equal to) the number of threads recording commands multiplied by the number of frames in flight.
Command allocators grow in line with the largest command buffer allocated from them.
Minimize the number of command buffer submissions to the GPU.
Each submit has a CPU and GPU cost associated with it.
Try to batch command buffers together into a single submission to reduce overhead.
Ideally, submissions would only happen when syncing queues or at the end of a frame.
Avoid using bundles and secondary command buffers.
They’re likely to hurt GPU performance (they only benefit CPU performance).
Just fill the command buffers every frame.
If they are used have at least 10 draws per bundle/secondary command buffer.
| DirectX® 12 | Vulkan® |
|---|---|
|
|
All the smaller state structures where combined into a single state known as a Pipeline State Object. This allows the driver to know everything up front so that it can compile the shaders into the correct assembly. This removes any stutters that could happen in the previous API generations when the driver had to recompile shaders at the time of the draw call due to a change in state. This also allows easier state optimizations since there is no longer a need to track multiple small states.
PSOs can take a long time to compile.
The driver will not spawn extra threads to compile.
Compiling PSOs is a great task for multi-threading.
Avoid compiling PSOs on threads with small stacks or in time sensitive code.
Avoid just in time compilation of PSOs.
Consider using an uber-shader first and then compile specializations later.
Compiling pipelines using the same shaders simultaneously may result in serialization by lock contention.
Use a pipeline cache to re-use PSOs across multiple runs.
Try to minimize the number of PSOs used.
Shader code does not need to be kept around after the PSO is created.
Minimize pipeline state changes when rendering.
The more similar the pipeline is to the previous, the lower the cost of the change.
Changing the bound PSO may roll the hardware context.
Sort draw calls by pipeline.
Group pipelines that use/don’t use the geometry shader stage or the tessellation stages together.
The driver does not do redundant state tracking.
| DirectX® 12 | Vulkan® |
|---|---|
|
|
Barriers are how dependencies between operations are conveyed to the API and driver. Barriers open up a whole new world of operations by allowing the application to decide if the GPU can overlap work. They are also an easy way to slow down the rendering by adding too many barriers or can cause corruptions from not having correct resource transitions. The validation layers can often help with identifying missing barriers.
Minimize the number of barriers used per frame.
Barriers can drain the GPU of work.
Don’t issue read to read barriers. Transition the resource into the correct state the first time.
Batch groups of barriers into a single call to reduce overhead of barriers.
Avoid GENERAL / COMMON layouts unless required.
Try to minimize the number of states combined.
| DirectX® 12 |
|---|
| When possible only set non pixel shader resource or pixel shader resource states instead of combining them. |
Explicitly managing GPU memory has been exposed in both Vulkan® and DirectX®12. While this does allow many new optimization opportunities, it can also be hard to write an efficient GPU memory manager. That’s why we created easy to use open source libraries for that purpose for both Vulkan® and DirectX®12.
Create large memory heaps and sub-allocate resources from the heap.
Recommended allocation size of heaps is 256MB.
Smaller sizes should be used for cards with less than 1 GB of VRAM
Try to keep your allocations static. Allocating and freeing memory is expensive.
Help reduce memory footprint by aliasing transient resources.
Make sure to issue the correct barriers and only use necessary flags during resource initialization.
Improper use of placed/sparse resources can cause a hang and/or visual corruption.
Make sure to fully initialize ( Clear, Discard, or Copy) placed resources to avoid hangs and/or corruptions.
Use QueryVideoMemoryInfo and VK_EXT_memory_budget to query for the current memory budget.
It is recommended to only use 80% of the total VRAM to reduce the probability of eviction.
Don’t call memory query functions per frame.
Instead use the RegisterVideoMemoryBudgetChangeNotificationEvent function to have the OS signal the app when the budget changes.
Select the correct memory type for the resources intended usage.
Tiled/Sparse resources:
We don’t recommend them based on their performance hit both on GPU and CPU.
Instead use sub allocations and the Copy/Transfer queue to defrag memory.
Never place high traffic resources in Tiled/Sparse (e.g. render targets, depth targets, UAVs/storage buffers, acceleration structures)
When user’s system has ReBAR enabled, entire VRAM is accessible for the CPU (Vulkan: DEVICE_LOCAL + HOST_VISIBLE memory type, DX12: GPU_UPLOAD heap type).
Use it for buffers that can be directly written by the CPU and read by the GPU, avoiding copy between two buffers.
CPU accesses go through PCIe®, but they perform well when good access pattern is used - the memory is only copied into using memcpy or written sequentially, never read.
| Related tool | |
|---|---|
Radeon™ Memory Visualizer (RMV) instruments every level of our Radeon™ driver stack, and is able to understand the full state of your application’s memory allocation at any point during your application’s life.
|  Radeon™ Memory Visualizer (RMV) is a tool to allow you to gain a deep understanding of how your application uses memory for graphics resources. |
| DirectX® 12 | Vulkan® |
|---|---|
|
|
A lot of hardware optimizations depend on a resource being used in a certain way. The driver uses the provided data at resource creation time to determine what optimizations can be enabled. Thus, it is crucial that resource creation is handled with care to profit from as many optimizations as possible.
Set only the required resource usage flags.
Avoid using STORAGE / UAV usage with render targets.
This prevents compressing color on older generations of AMD GPUs, prior to GCN 3.
Alias the same memory allocation with a separate resource if you are only interested in memory savings.
Use non-linear layouts when available.
Use 4x MSAA or less where possible.
Use buffer to image and image to buffer copies instead of image to image copies when uploading images.
If you can mark a resource as read only, always do so, as this helps the hardware enable compression for it.
Avoid shared access on render and depth targets.
Avoid using TYPELESS or MUTABLE formats on render targets, depth targets, and UAVs/storage buffers.
FLOAT, INT, NORM, etc).Mipmapped arrays of render targets will not get compression optimizations.
24-bit depth formats have the same cost as 32-bit formats on GCN and RDNA.
Use a 32-bit format on AMD to get higher precision for the same memory cost as 24-bit.
16-bit depth does not necessarily compress better than 32-bit depth.
Use reversed depth (near plane at 1.0) to improve the distribution of floating-point values.
Try to use the full range of the depth buffer.
Having all the values clumped up in a small part of the range can reduce depth test performance.
Improve depth distribution by having the near Z value be as high as possible.
Use depth partitioning for close geometry (e.g. player hands) to help improve this distribution further.
Split your vertex data into multiple streams.
Allocating position data in its own stream can improve depth only passes.
If there is an attribute that is not being used in all passes, consider moving it to a new stream.
Avoid setting vertex streams per draw call.
Updating the vertex streams can cost CPU time.
Use vertex and instance draw offsets to use data at an offset in the stream.
Vertex data can also be stored in SBOs/Structured buffers and fetched in a vertex shader instead of using vertex streams.
Avoid using primitive restart index when possible.
Reading from overly sparse resources can be bad for cache utilisation.
Try and write all color channels in a render target because partial writes will disable compression.
When bit-packing fields into a G-Buffer, put highly correlated bits in the Most Significant Bits (MSBs) and noisy data in the Least Significant Bits (LSBs).
Descriptors are used by shaders to address resources. It is up to the application to provide a description of where the resources will be laid out during PSO creation. This allows the application to optimize the layout of descriptors based on the knowledge of what resources will be accessed the most.
Try to minimize the size of root signatures/descriptor set layouts to avoid spilling user data to memory.
Try to stay below 13 DWORDs.
Place parameters that will change often or need low latency in the front. This will help minimize the possibility of those parameters spilling.
Minimize use of root descriptors and dynamic buffers.
Avoid setting the shader stage flags to ALL on descriptors. Use the minimal required flags.
Minimize the number of descriptor set updates.
Reference resources that belong together in the same set.
Consider using a bindless system to help reduce CPU overhead from binding descriptors.
Order the draws by root signature and pipeline layouts when using multiple versions of these.
The driver can embed static and immutable sampler into the shader, reducing memory loads.
Try to reuse samplers in the shader. This allows the shader compiler to reuse sampler descriptors when compared to binding multiple samplers that have the same value.
Only constants changing every draw should be in the root signature or push constants.
Avoid copying descriptors.
DESCRIPTOR_HEAP_FLAG_SHADER_VISIBLEPrefer using CopyDescriptorsSimple / vkUpdateDescriptorSet over CopyDescriptors / vkUpdateDescriptorSetWithTemplate.
| DirectX® 12 | Vulkan® |
|---|---|
|
|
One large new addition to the graphics programmers tool box is the ability to control the synchronization between GPU and CPU. No longer is synchronization hidden behind the API. Submission of command buffers should be kept to a minimum as submitting requires a call into kernel mode as well as some implicit barriers on the GPU.
Work submitted does not need semaphores/fences for synchronization on the same queue — use barriers in the command buffers.
Command buffers will be executed in order of submission.
Cross queue synchronization is done with fences or semaphores at submission boundaries.
Minimize the amount of queue synchronization that is used.
Semaphores and fences have overhead.
Each fence has a CPU and GPU cost with it.
Don’t idle the CPU during submission or present: the CPU can continue preparing command lists for the next frame.
When overlapping frame rendering with async compute, present from a different queue to reduce the chances of stalling.
| DirectX® 12 | Vulkan® |
|---|---|
|
|
AMD hardware has the ability to do a fast clear. It cannot be overstated how much faster these clears are when compared to filling the full target. Fast clears have a few requirements to get the most out of them.
Fast clears are designed to be ~100x faster than normal clears.
Fast clears require full image clears.
Render target fast clears need one of the following colors.
RGBA(0,0,0,0)
RGBA(0,0,0,1)
RGBA(1,1,1,0)
RGBA(1,1,1,1)
Depth target fast clears need 1.f or 0.f depth values (with stencil set to 0).
Depth target arrays must have all slices cleared at once to do a fast clear.
Use Discard / LOAD_OP_DONT_CARE to break dependencies when skipping a clear.
| Vulkan® |
|---|
|
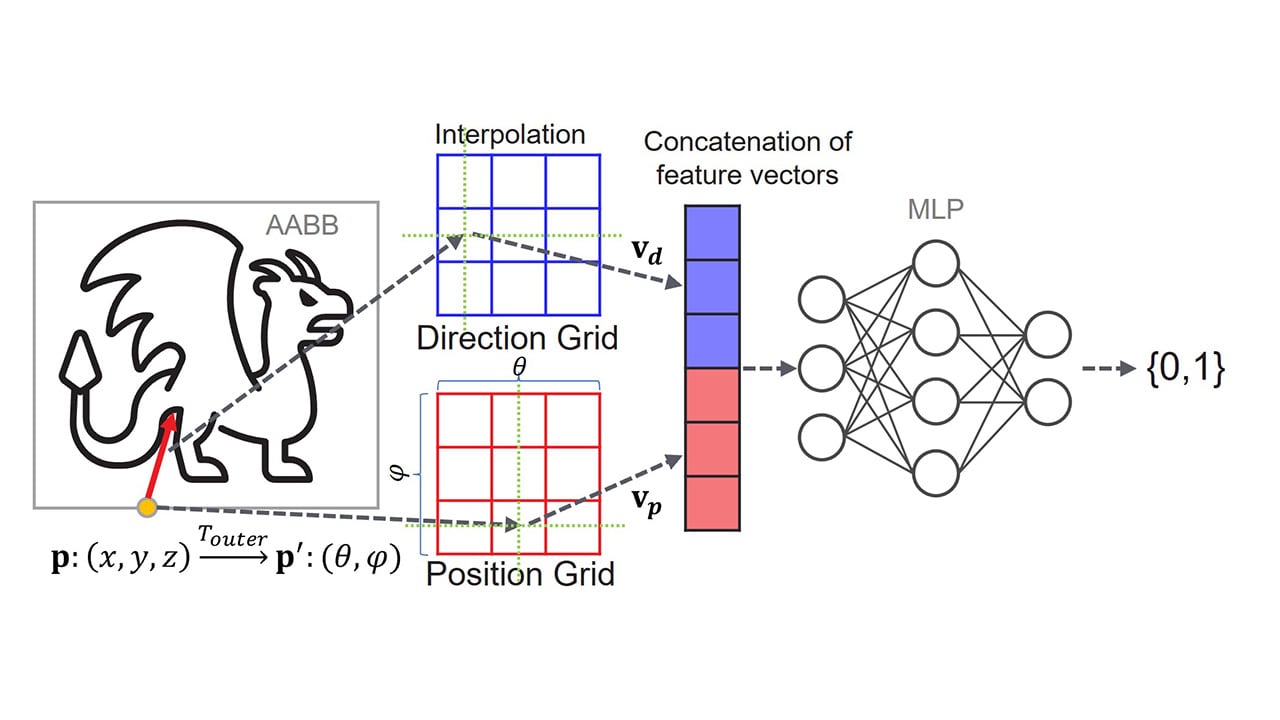
GCN and RDNA hardware have support for submitting compute shaders though an additional queue that will not be blocked from executing by the fixed function hardware. This allows filling the GPU with work while the graphics queue is bottlenecked on the frontend of the graphics pipeline.
Async compute queues can be used to issue compute commands to the GPU parallel to the graphics queue.
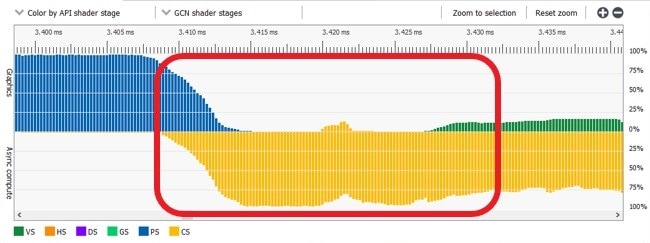
Async compute fills compute units as graphics waves drain.
Use async compute work to overlap frontend heavy graphics work.
Common overlapping opportunities include Z pre-pass, shadow rendering, and post-process.
The frame post-processing can be overlapped with the beginning of the next frames rendering.
Async compute performs poorly when executed in parallel with export bound shaders.
Smaller workgroups (64 threads) usually perform better than larger workgroups when run async.
Any graphics work submitted after a compute dispatch or vice-versa can overlap if there are no barriers.
Small dispatches work better as pipelined compute vs async compute.
A large dispatch followed by a large draw is another place where pipelined compute works well.
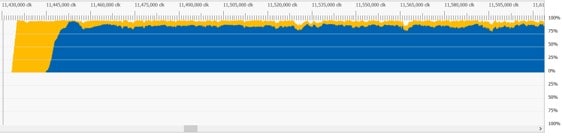
Pipelined compute overlaps with a pixel shader
In addition to having a compute queue, GCN and RDNA also have dedicated copy queues. These copy queues map to special DMA engines on the GPU that were designed for maximizing transfers across the PCIe bus. Vulkan and DX12 give direct access to this hardware though the copy/transfer queues.
Use the copy queue to move memory over PCIe.
This is marginally faster than the other queues.
It allows independent graphics and compute work to run without waiting.
The copy queue can also move memory around on the GPU and may be used to defrag memory asynchronously.
Use compute or graphics queues to copy when both:
The destination and source are on the GPU.
The result is needed immediately or the queue is otherwise idle.
Memory in UPLOAD and GPU_UPLOAD heap (DX12) / HOST_VISIBLE and non-HOST_CACHED type (Vulkan) is uncached and write-combined. Be careful when accessing it through a mapped pointer:
Only write to it using memcpy or sequentially number-by-number. Avoid random accesses.
Never read from it. Watch out for accidental reads, e.g. pMappedPtr[i] += v.
| DirectX® 12 |
|---|
Resources in UPLOAD memory are accessible to shaders.
|
ExecuteIndirect is a DirectX® 12 feature that allows generating work from the GPU without reading back to the CPU.
The fastest path in ExecuteIndirect is to avoid changing any root signature attributes.
On pre-RDNA hardware, any changes to the root signature will cause the driver to go down a slow path.
RDNA added an optimized path for root signature changes inside an ExecuteIndirect.
To get the best performance with root signature changes:
Avoid updating vertex buffer bindings though ExecuteIndirect.
Avoid updating any root signature values that may have spilled to memory.
Keep root signature updates contiguous when updating though ExecuteIndirect.
Always compact the argument buffer and provide a count buffer if any draws are culled out.
Avoid arc functions ( atan , acos , etc). They can generate code taking 100+ cycles.
Minimize use of transcendental functions ( sin , cos , sqrt , log , rcp ). These functions run at quarter rate.
RDNA can co-execute transcendentals at quarter rate.
Be careful with using tan as it will expand to 3 transcendentals: sin / cos .
Use approximations to help improve performance. FidelityFX has a library of fast approximations.
GCN and RDNA support cross-wave ops via AGS, shader model 6, or SPIR-V subgroup operations.
Shader intrinsics can be used to reduce VGPR (Vector General Purpose Register) pressure.
FP16 can be used to reduce VGPR allocation count.
VGPRs can be scalarized though the readFirstLane intrinsic.
When sampling a single channel, use Gather4 to improve texture fetch speed.
While not reducing bandwidth, Gather4 will reduce the amount of traffic to the texture units and improve cache hit rate.
Gather4 may reduce the number of VGPRs required.
GCN runs shader threads in groups of 64 known as wave64.
RDNA runs shader threads in groups of 32 known as wave32.
Unused threads in a wave get masked out when running the shader.
Make the workgroup size a multiple of 64 to obtain best performance across all GPU generations.
To help maximize bandwidth in compute shaders, write to images in coalesced 256-byte blocks per wave.
Rule of thumb is to have an 8×8 thread group write 8×8 blocks of pixels.
Using a swizzled layout of threads can improve bandwidth and cache hit rate.
ARmpRed8x8() , for this.Thread group shared memory maps to LDS (Local Data Share)
LDS memory is banked on RDNA and GCN.
It’s spread across 32 banks.
Each bank is 32 bits (1 DWORD).
Bank conflicts increase latency of instructions.
Prefer a struct of arrays or add padding to reduce access strides and bank conflicts.

Float4 array

Reading X (8 bank conflicts)

Array of floats

Reading X (2 bank conflicts)
Compute shaders can increase opportunities for optimizing using LDS or better thread utilization.
Use a compute shader for full-screen passes.
This can provide up to 2% improvement over a full screen quad, depending on hardware configuration.
Removes need for helper lanes created at triangle edge.
Will usually improve cache hit rate vs a full screen quad.
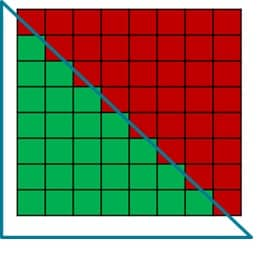
A triangle will not fill the whole wave with a 8x8 tile
Compute shaders can be faster in highly divergent workloads compared to pixel shaders on pre-RDNA 3 hardware, because pixel shaders can be blocked from exporting by other waves.
Culling primitives using a geometry shader or cull distances is expensive.
Cull primitives from the vertex shader by setting any vertex position to NaN.
Avoid discard in long running shaders when there are other paths.
discard.Minimize the total amount of data written by a pixel shader to save memory bandwidth.
Avoid using RGB32 formats.
Do not write feedback for every shaded pixel.
Use stochastic discard techniques to lower the cost of writes to feedback resources.
Vega added Rapid Packed Math (RPM) for double rate 16-bit float.
Use the flag -enable-16bit-types in DXC to get true 16-bit types.
Use Texture2D<float16_t4/int16_t4> to get 16-bit samples and loads.
Use VRS to reduce pixel shading when pixel shading bound.
Use of the following features can cause VRS fill rate to drop to 1×1:
Depth export.
Post-depth coverage.
Raster Ordered Access Views.
Minimize the number of times per frame the VRS shading rate image gets bound or unbound.
|  RGP gives you unprecedented, in-depth access to a GPU. Easily analyze graphics, async compute usage, event timing, pipeline stalls, barriers, bottlenecks, and other performance inefficiencies.  Radeon™ Raytracing Analyzer (RRA) is a tool which allows you to investigate the performance of your raytracing applications and highlight potential bottlenecks.  Improving raytracing performance with the Radeon™ Raytracing Analyzer (RRA) Optimizing the raytracing pipeline can be difficult. Discover how to spot and diagnose common RT pitfalls with RRA, and how to fix them! |
| DirectX® 12 |
|---|
|
While debugging is not optimization it is still worth mentioning a few tips for debugging that will come in handy when optimizing rendering.
The debug runtime/validation layer is your friend.
Titles must be warning free or risk breaking on some implementations or future hardware and drivers.
It might not catch all undefined behavior.
Buffer markers help track down TDRs.
Write the markers into a buffer created with external memory. Otherwise, the buffer may be lost with the device.
Don’t ship with a buffer marker per draw call. It can limit the amount of work in flight.
Use a marker per pass for shipping builds.
Debug markers will show up in tools like RenderDoc, PIX and RGP.
Implement an easy way to wait for the GPU to finish. It will help track down synchronization issues.
| DirectX® 12 |
|---|
|