AMD Radeon™ GPU Profiler
AMD RGP gives you unprecedented, in-depth access to a GPU. Easily analyze graphics, async compute usage, event timing, pipeline stalls, barriers, bottlenecks, and other performance inefficiencies.
Although it has only been a few months since the release of version 1.8 of Radeon™ GPU Profiler (RGP), we are happy to bring you the next release of our flagship graphics profiler.
This version introduces support for the newest GPUs in the Radeon™ family, the Radeon™ RX 6000 Series, which feature AMD RDNA™ 2 architecture. Many of the changes required to support this architecture were done “under the hood”, so most of the UI will look quite familiar.
DirectX® Raytracing is now a first-class citizen in RGP, and this is reflected in many parts of the user interface. Here are the major changes you might notice when visualizing profile data from an application that uses the DirectX® Raytracing API.
In the various RGP views that show events, you will see new event types related to Raytracing. These new events are DispatchRays , DispatchRays , ExecuteIndirect , and CmdDispatchBuildBVH() . The exact events you see will depend on how the application being profiled uses the DirectX® Raytracing API.
A quick note about the and variants of the DispatchRays events – these events both correspond to the DispatchRays API call, but the specific one used depends on the compilation mode chosen by the driver and compiler. The main difference between these two compilation modes has to do with how the individual shaders in the raytracing pipeline are compiled:
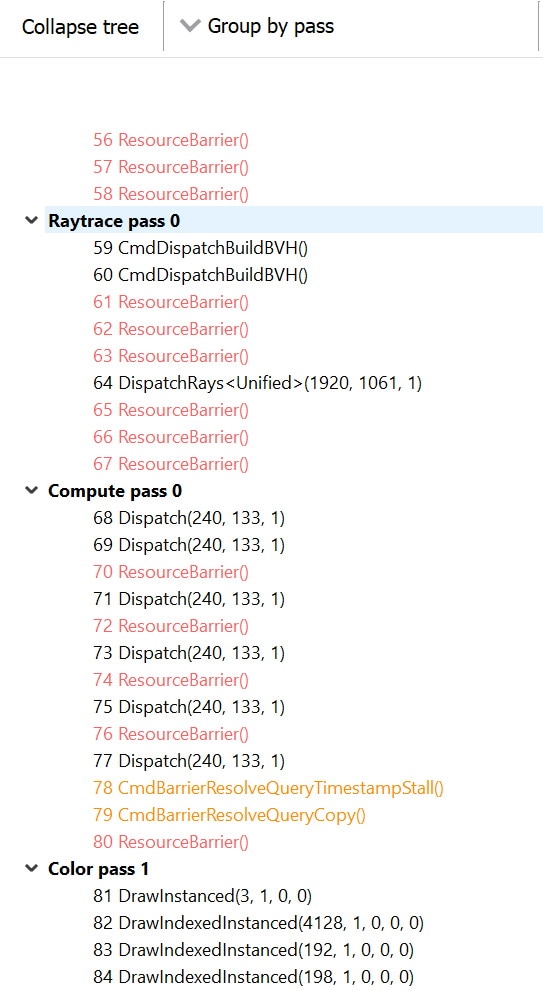
Here’s a screenshot of a few of these events in the Event tree view, which is part of both the Event timing and Pipeline state views in RGP:

In these same Event tree views, if you choose to “Group by pass”, the top level nodes in the treeview will now include Raytracing passes:
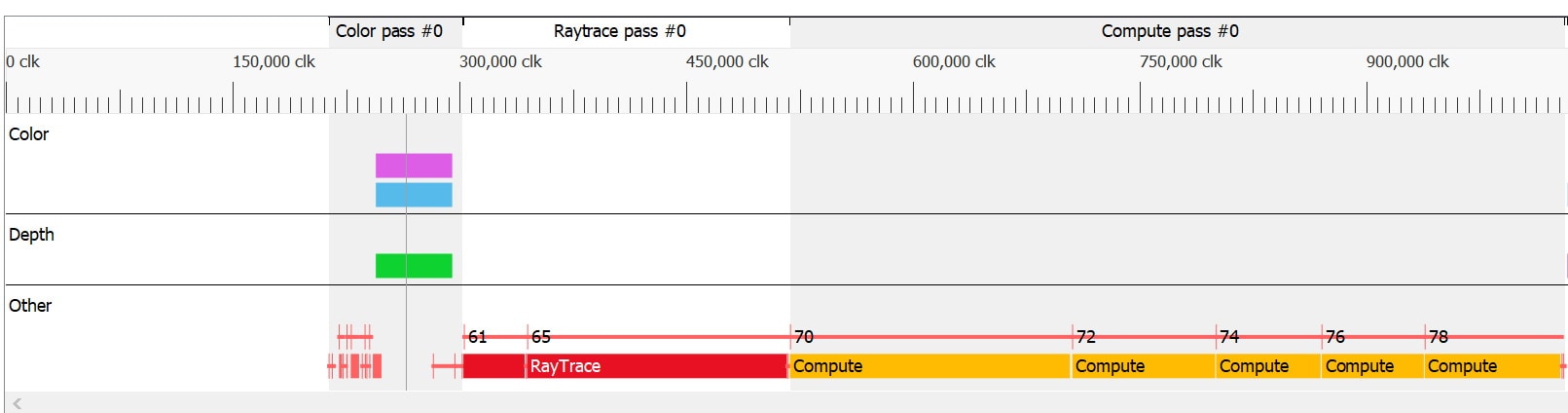
These passes also show up above the timeline in the Render/depth targets view. Raytracing events are also displayed in the Other row in the timeline:
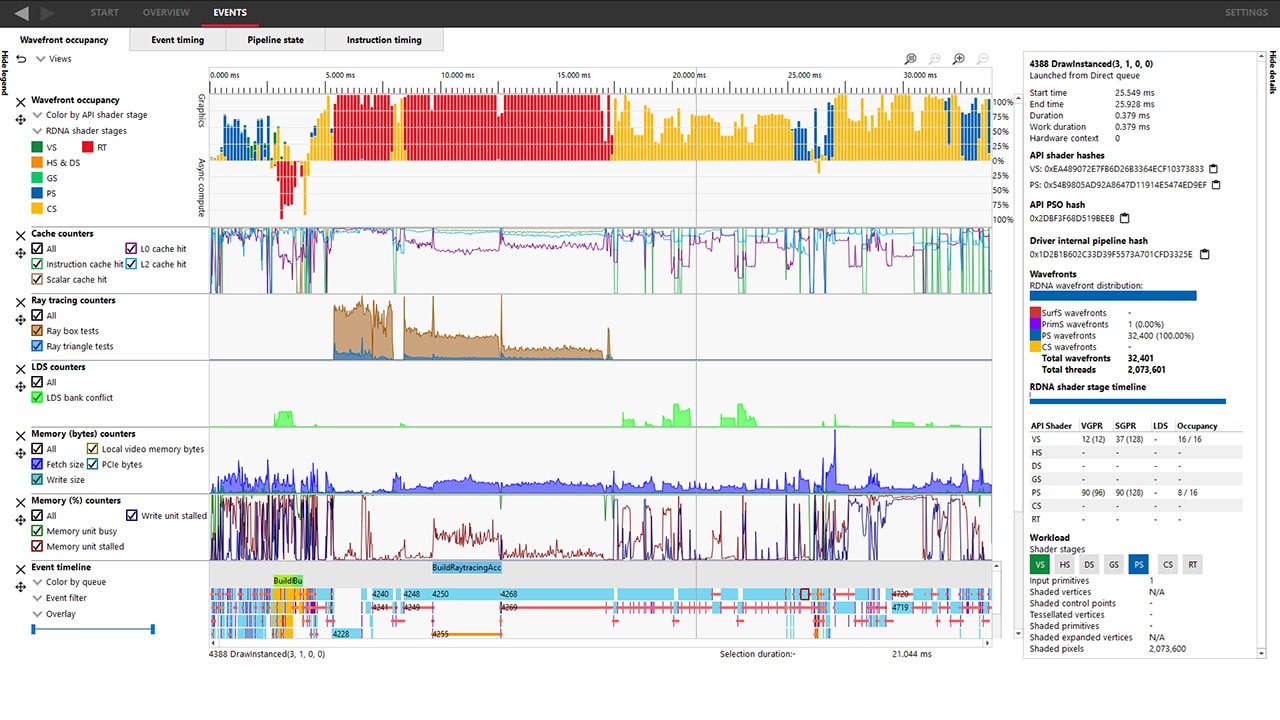
In the Wavefront Occupancy view, when using the default coloring mode (“Color by API shader stage”), waves that come from raytracing events will show up in red:
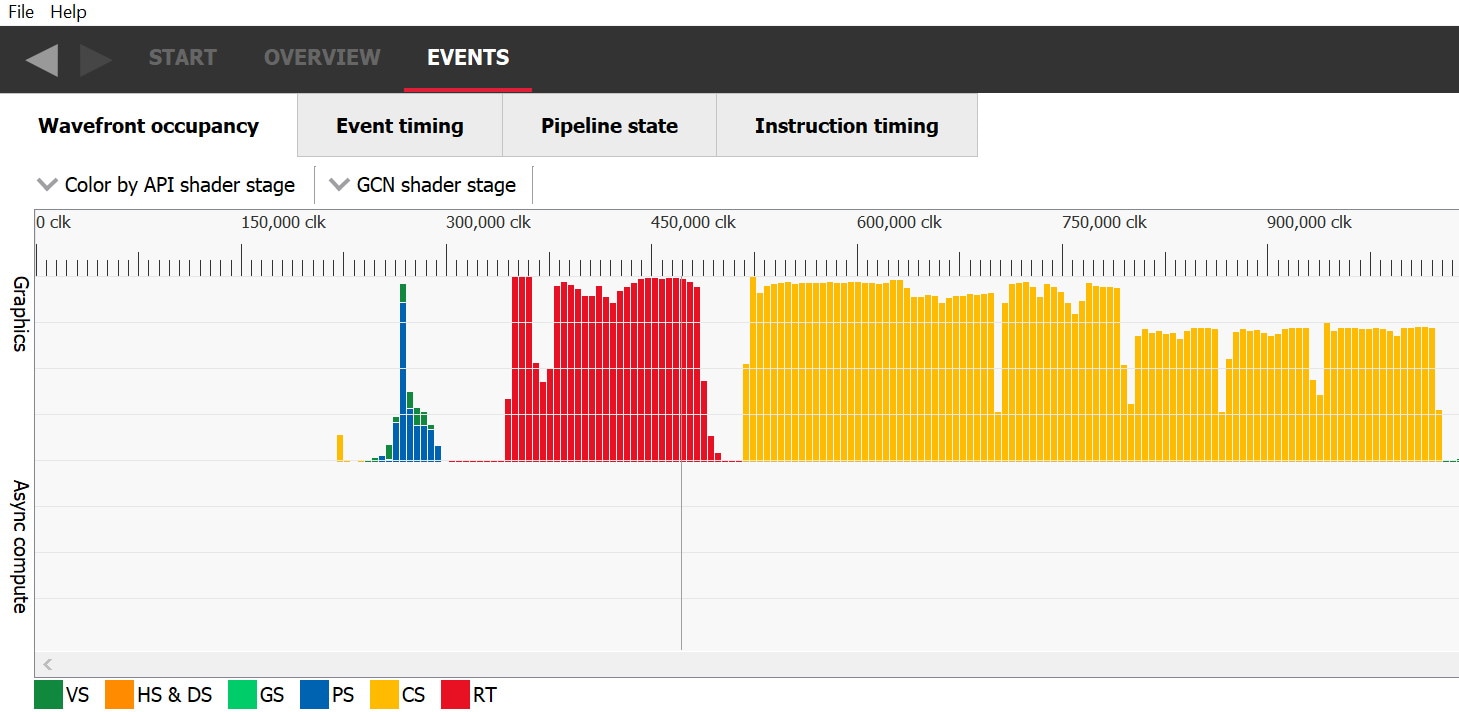
Similarly, when the view is set to “Group by pass”, the Raytrace passes mentioned earlier will also show up here.
When selecting a raytracing event in one of the Events panes, the Details pane shown on the right will display extra information.
In the below screenshot, you can see the API shader table now has a row to show the resource usage and the theoretical occupancy related to the Raytracing stage. The graphical stage UI has a new “RT” item (colored red) to help indicate that the selected event is a raytracing event.
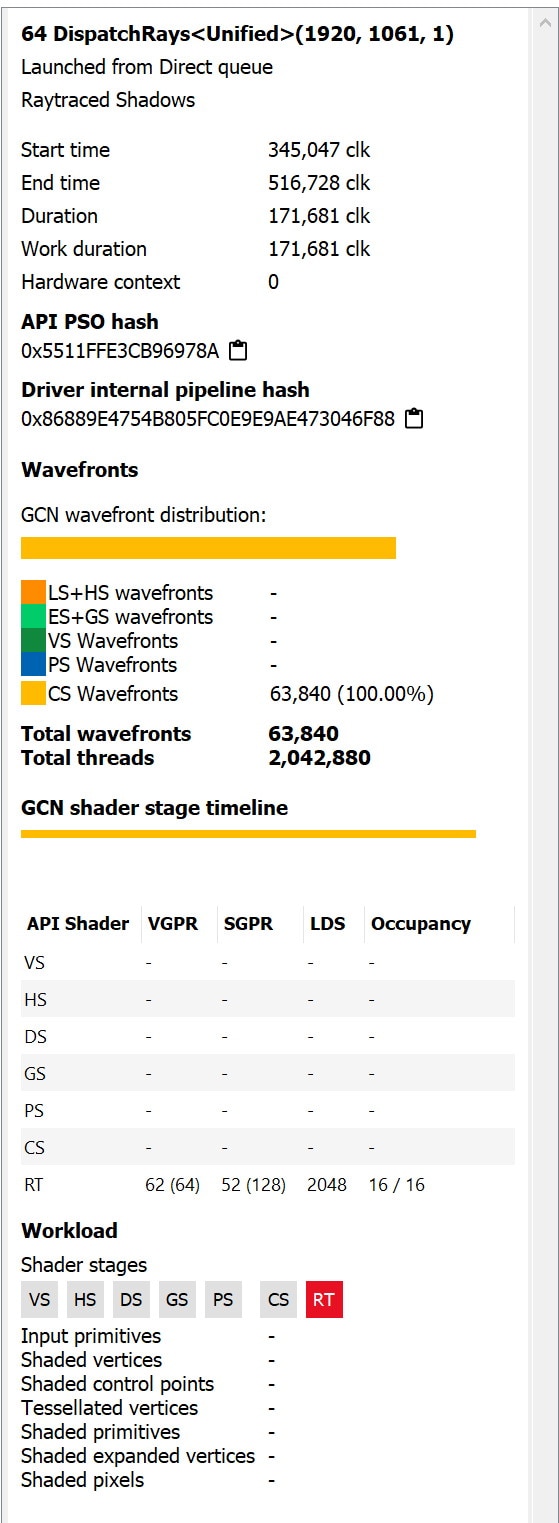
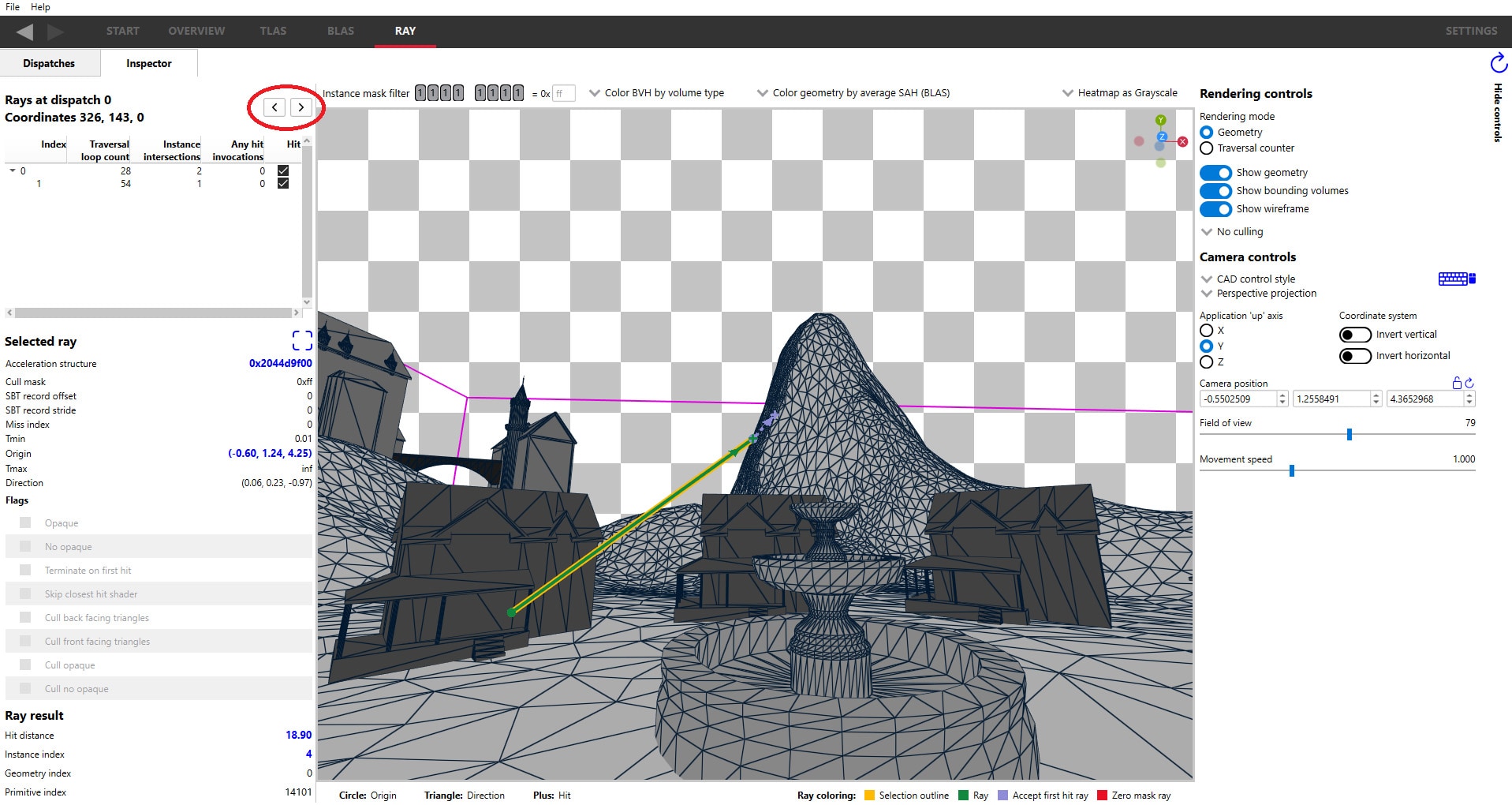
When selecting a DispatchRays event in the Pipeline State view, the UI is significantly different. There is a new Shader table tab. This tab contains an interactive visual representation of the raytracing pipeline, as well as a table listing all of the shader functions referenced by the selected event. The table gives information about each shader function.
See screenshot below:
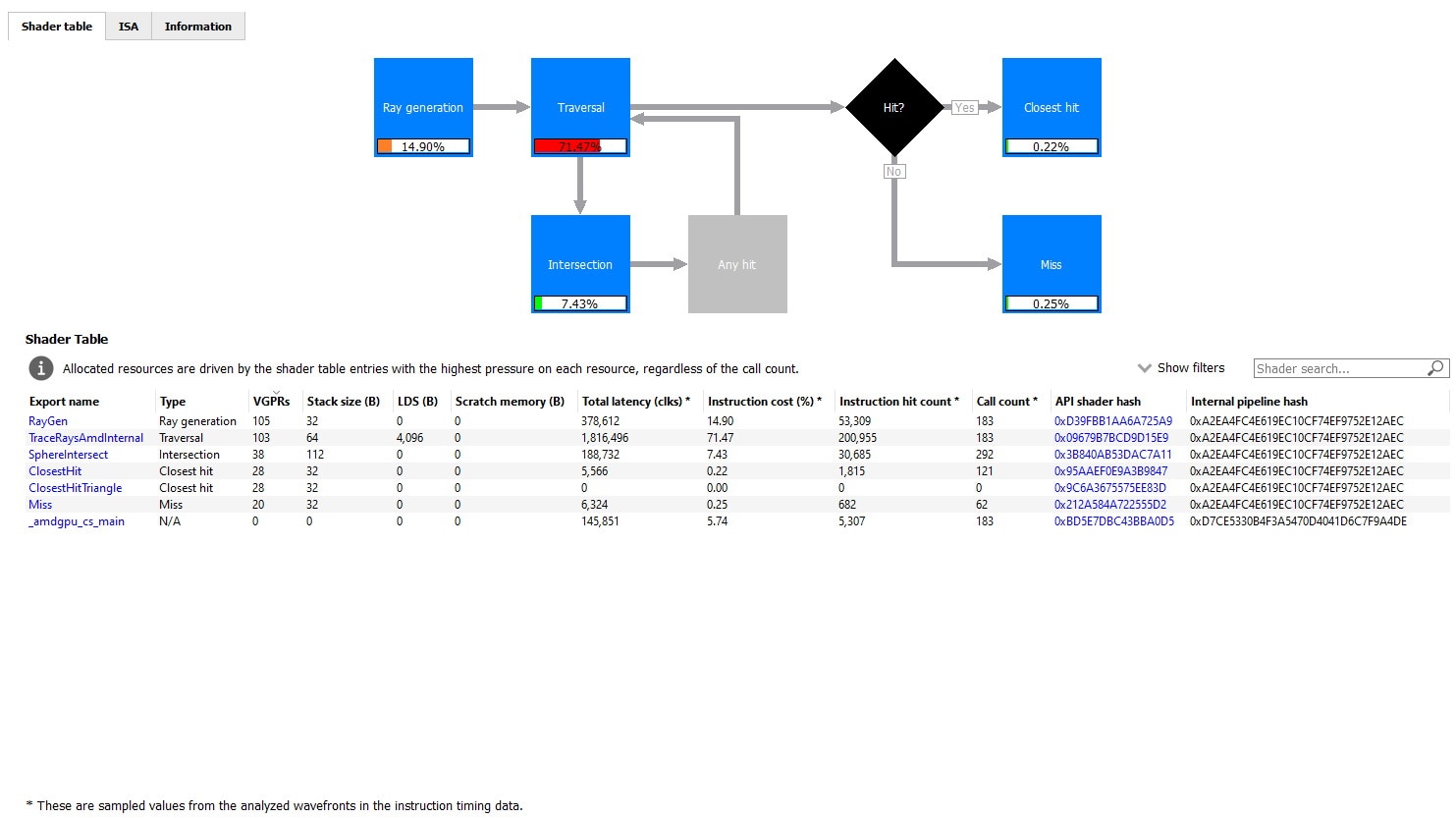
In this view, the raytracing flowchart indicates the relative cost of each stage in the raytracing pipeline (the red, orange and green percentage bars in each stage).
Any enabled stage in the flowchart can be clicked which will serve to filter the table below by that shader type. More than one stage can be selected by using ctrl+mouse-click to select more than one stage.
You can also filter the table manually using the Show Filters drop down. From the table, you can click on one of the hyperlinks to view that shader function in the ISA tab.
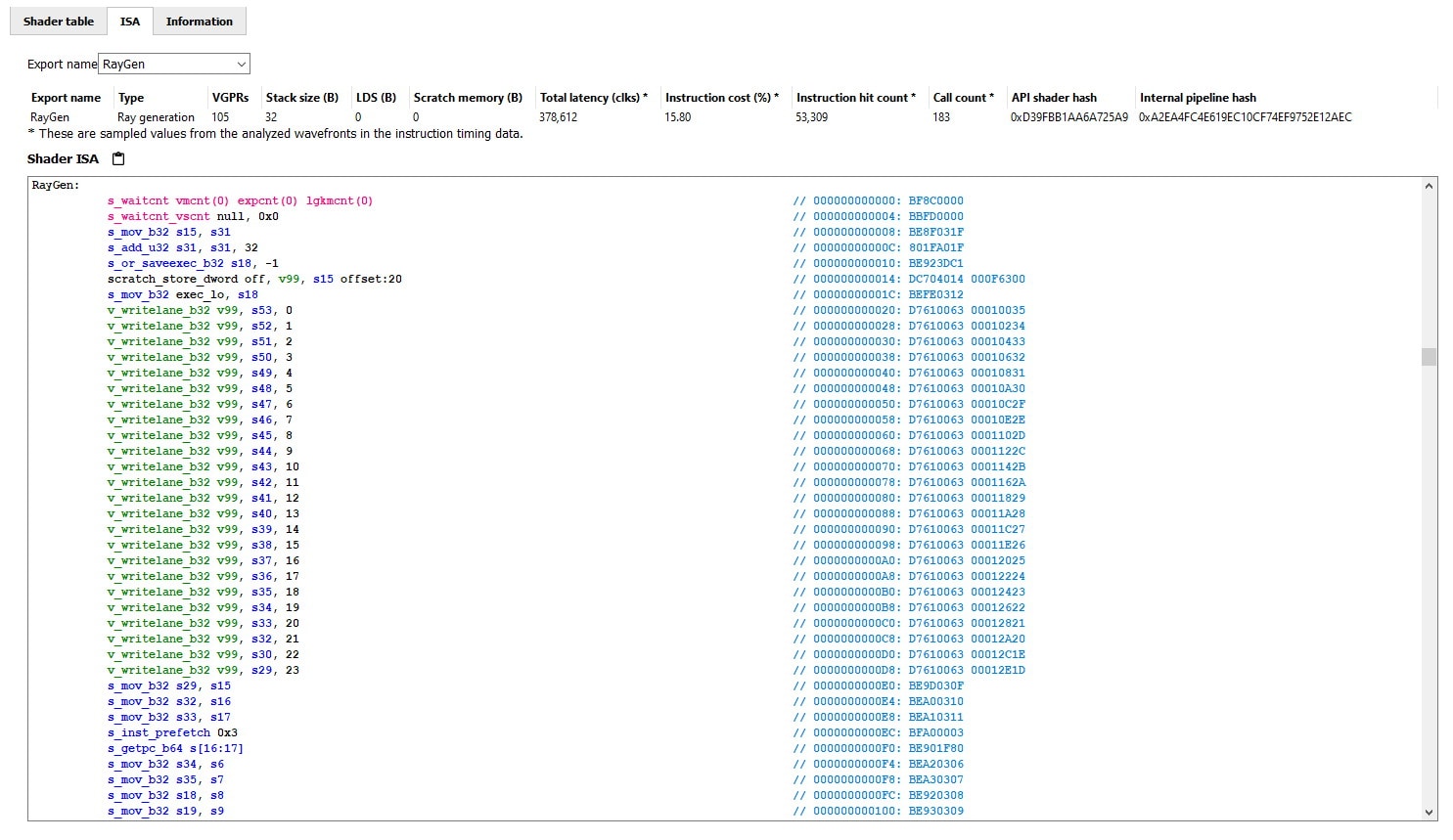
The ISA tab can also display the ISA from all indirect shaders. There is a UI element to give information about the currently-visible shader as well as a drop down selector which allows you to switch between shaders.
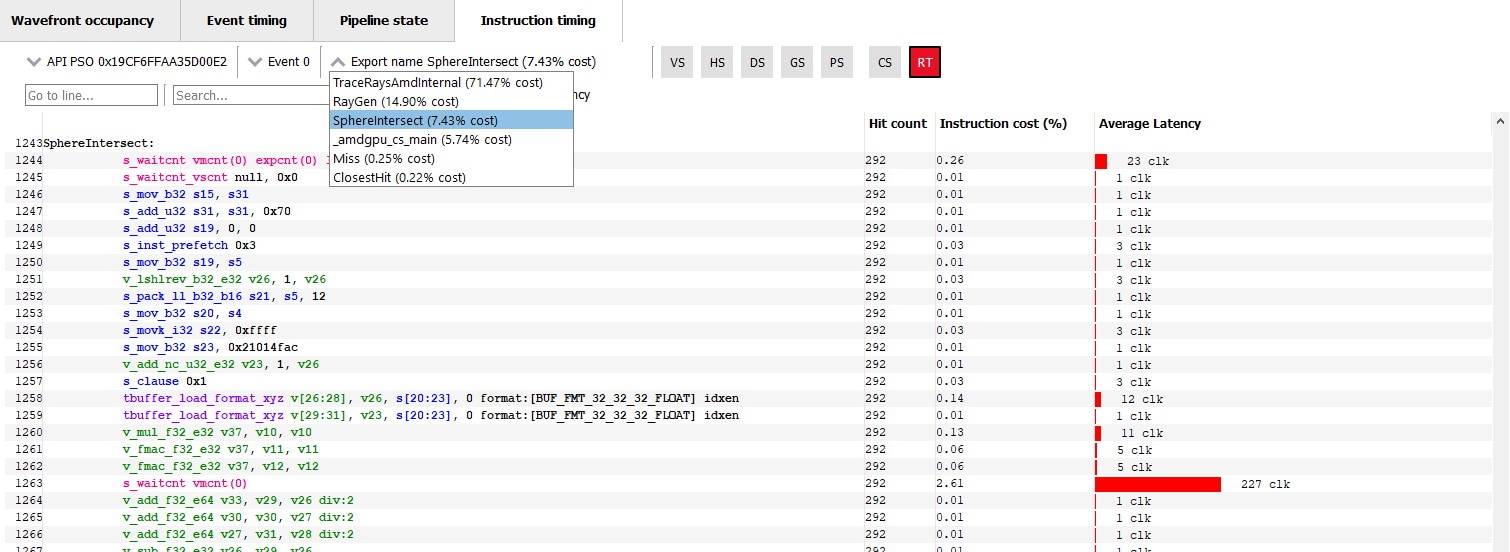
The Instruction timing view has also been updated to support the indirect shader functions.
Selecting a DispatchRays event in the Instruction timing view, the disassembled ISA includes code from all indirect shaders which have a non-zero hit count. There is an additional “Export name” drop down at the top of the view allowing you to navigate to the ISA of a particular shader. This drop down will contain a list of all indirect shaders, sorted by the relative cost of each shader.
In the below screenshot, the TraceRaysAmdInternal shader has the highest cost (71.47%). When you select an item from this drop down, the disassembled ISA code will scroll to show the beginning of the selected shader. This allows you to quickly see the Instruction timing data for any given indirect shader.
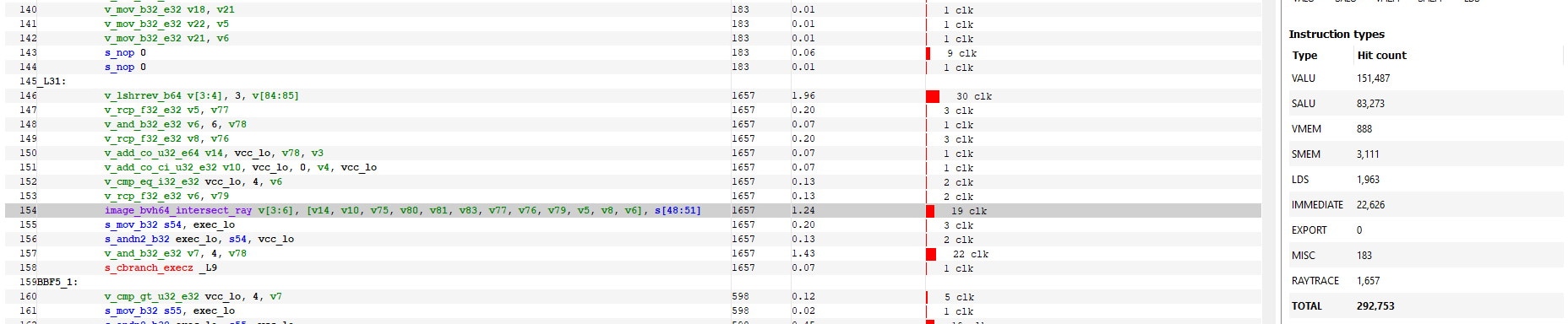
The Instruction Types table in the Details panel also includes a new row displaying the hit count for all raytrace instructions.
In the below screenshot, the selected event has a single image_bvh64_intersect_ray instruction that has a hit count of 1657. You can see this reported in the RAYTRACE row in the Details pane on the right.
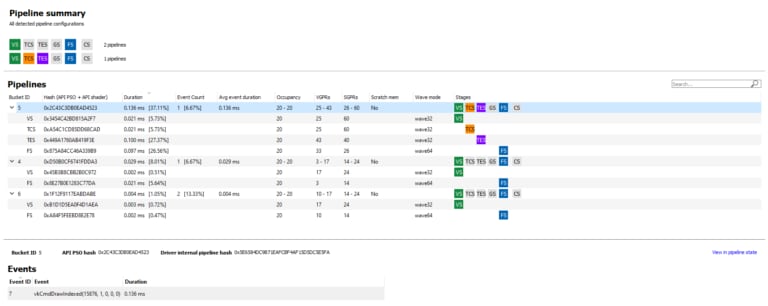
Finally, there have been smaller enhancements in the Most expensive events and Pipelines Overview panes to adapt to the new Raytracing features.
We have also improved upon the single-shader-engine full-frame Instruction Timing feature that was introduced in RGP 1.8. For this release, we’ve incorporated some driver changes into Radeon Developer Panel that reduce the overhead and amount of instruction timing data collected without compromising the data presented in RGP.
In addition, the data collection has been enhanced to better use GPU memory when gathering instruction timing data.
With these enhancements (which require a 20.45-based driver), it is less likely that the profile data will exceed the memory buffer allocated on the GPU to store data used by RGP.
As with all RGP releases, there have been plenty of bug fixes and other smaller enhancements. We invite you to head over the product page on gpuopen.com and download the latest version to check out all the goodness to be found.
And as always, we value feedback we receive from our users. If you have ideas for future enhancements, or have something you’d like to share with us, please visit the product page on GitHub and use the Issues list to share your feedback.