Radeon™ Rays
The lightweight accelerated ray intersection library for DirectX®12 and Vulkan®.
Hello! We assume, by default, that you have already read the Preface to the CPU Performance Optimization Guide, and that you have a general understanding of the basic concepts of CPU performance optimization. This chapter, as a part of the series, is a continuation of the CPU Performance Optimization Guide III, to help you better understand how to use assembly optimization code, and hopefully bring some help to your own project.
Keywords: assembly.
A challenge that may arise in project development is whether the high-level language compiler has generated the optimal instructions. If the compiler generates instructions that do not perform optimally, is there any other way to generate better instructions?
First of all, most modern CPUs contain several instruction sets, such as x86, x64, SSE, and AVX instruction sets. Here we choose the x64 instruction set, which is the most common. The goal is to write assembly code using only the x64 instruction set and see if it can run faster than the instructions generated by the compiler.
Then comes the compiler. Due to the popularity and ease of use of Microsoft® Windows® 10, Microsoft® Visual Studio® 2022 is selected as the development environment, and the version used is 17.9.2. The compiler version is 19.39.33521. The compiler type is x64 RelWithDebInfo. The operating system version is 10.0.19045.4046. The assembly compiler we use the MASM of Visual Studio.
Finally, the CPU needs to be identified because the architecture is constantly being updated. The latency of each instruction varies from CPU to CPU. The CPU used here is an AMD Ryzen™ 9 7900X3D.
Since there have been performance tests before, this time we will go directly to the analysis phase, focusing on the assembly code generated by the compiler.
First look at the compiler-generated assembly code for displaced TB040. For such a simple function, the compiler performs well with almost all the code running on registers, ensuring the lowest instruction latency and highest throughput. However, the assembly code still has some redundancies. It is mainly manifested in the excessive register assignment operations generated in the while loop to calculate the g.
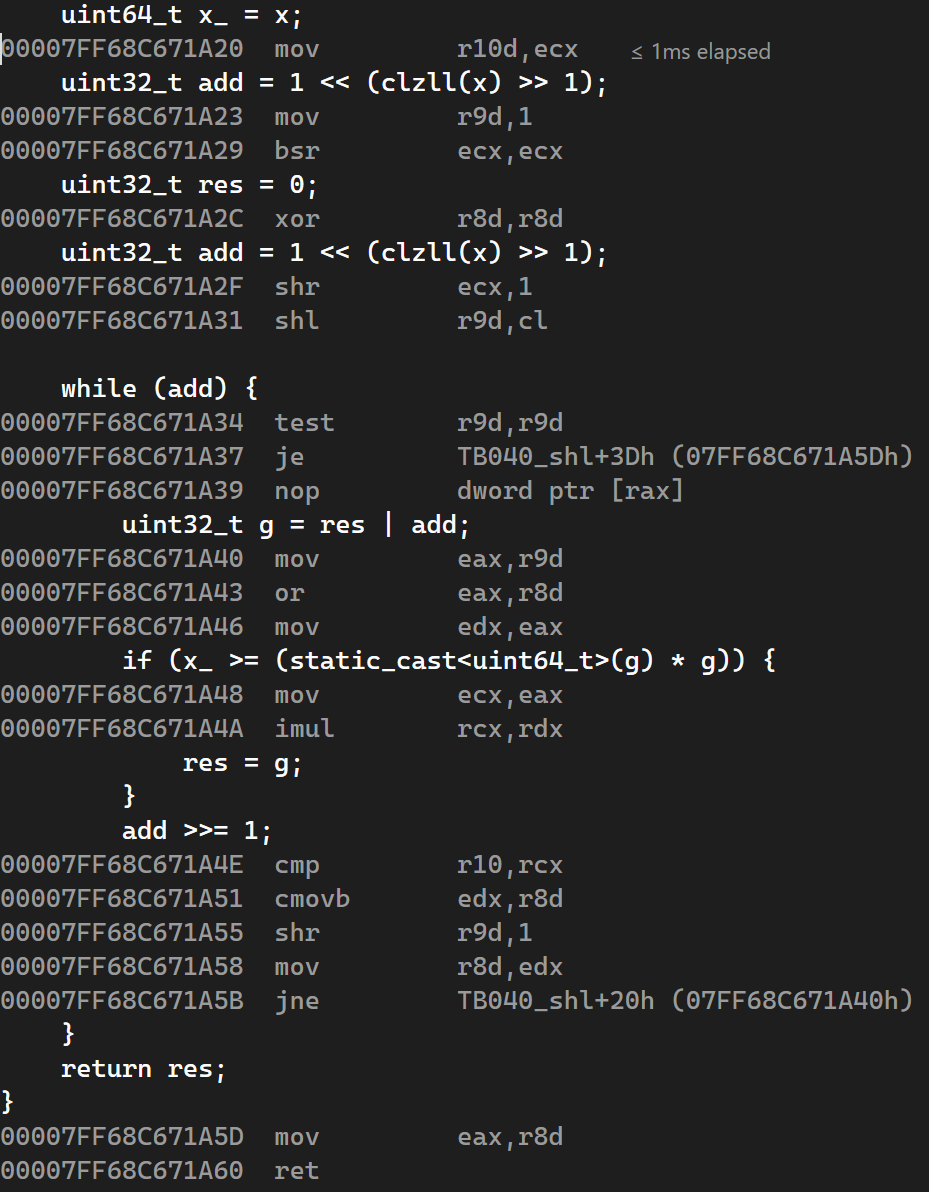
Figure 1: Displaced TB040 assembly code
For such simple C++ codes, the compiler’s performance is ideal enough. To get the compiler to produce better assembly code is very hard. The reason is that the compiler itself needs to give consideration to compatibility, and the generated assembly code needs to ensure good performance in all code logics. If a solution does not perform correctly in some logics, the compiler will choose an alternative solution with better average performance. In this case, writing the assembly manually is the best option if you want to discard some of the compatibility for optimal performance.
You need to meet the following requirements to write the assembly manually:
rax, rcx, rdx, and r8 - r11.rcx, rdx, r8, and r9 registers, as well as the stack, can be passed in as parameters to the function, and the rax can be returned as an integer value.Now that all the conditions have been met, the next step is to write the assembly code. The overall goal is to streamline the assembly instructions inside the while loop, using fewer registers to do the same job. At the same time, don’t forget to align the function and jump entry address to 16 bytes, so as to ensure that the CPU can access the address quickly.
1. _TEXT$21 segment para 'CODE'2.3. align 164. public TB040_shl_asm5. TB040_shl_asm proc frame6.7. ; r9d: add, r8d: res, r10d: x8.9. mov r10d,ecx10. mov r9d,111. bsr ecx,ecx12. xor r8d,r8d13. shr ecx,114. shl r9d,cl15. test r9d,r9d16. je TB040_shl_end17.18. align 1619. TB040_shl_loop:20. mov ecx,r9d21. or ecx,r8d22. mov eax,ecx23. imul rax,rcx24. cmp r10,rax25. cmovae r8d,ecx26. shr r9d,127. mov eax,r8d28. jne TB040_shl_loop29.30. align 1631. TB040_shl_end:32. ret33.34. .endprolog35.36. TB040_shl_asm endp37.38. _TEXT$21 ends39.40. endOnce the code is completed, we can start building the benchmark that meet the following criteria:
The goal this time is consistent with part III. Therefore, the data set is still all unsigned integer ranges that uint32_t can cover, and this data magnitude is enough to ensure the accuracy of performance data.
At the same time, the algorithm needs to be verified. Each integer will be compared with the result of std::sqrt to ensure the correctness of the algorithm itself.
The reference sample is the Displaced TB040 referred to in part III. The test function is the Displaced TB040 written using only assembly instructions. The new function is called Assembly TB040.
Finally, the performance test needs to be run a few more times to average the data to prevent hopping. It can be seen that Assembly TB040 is slightly faster than the Displaced TB040 by about 5%, which is quite a good result for such simple register-only operation code.
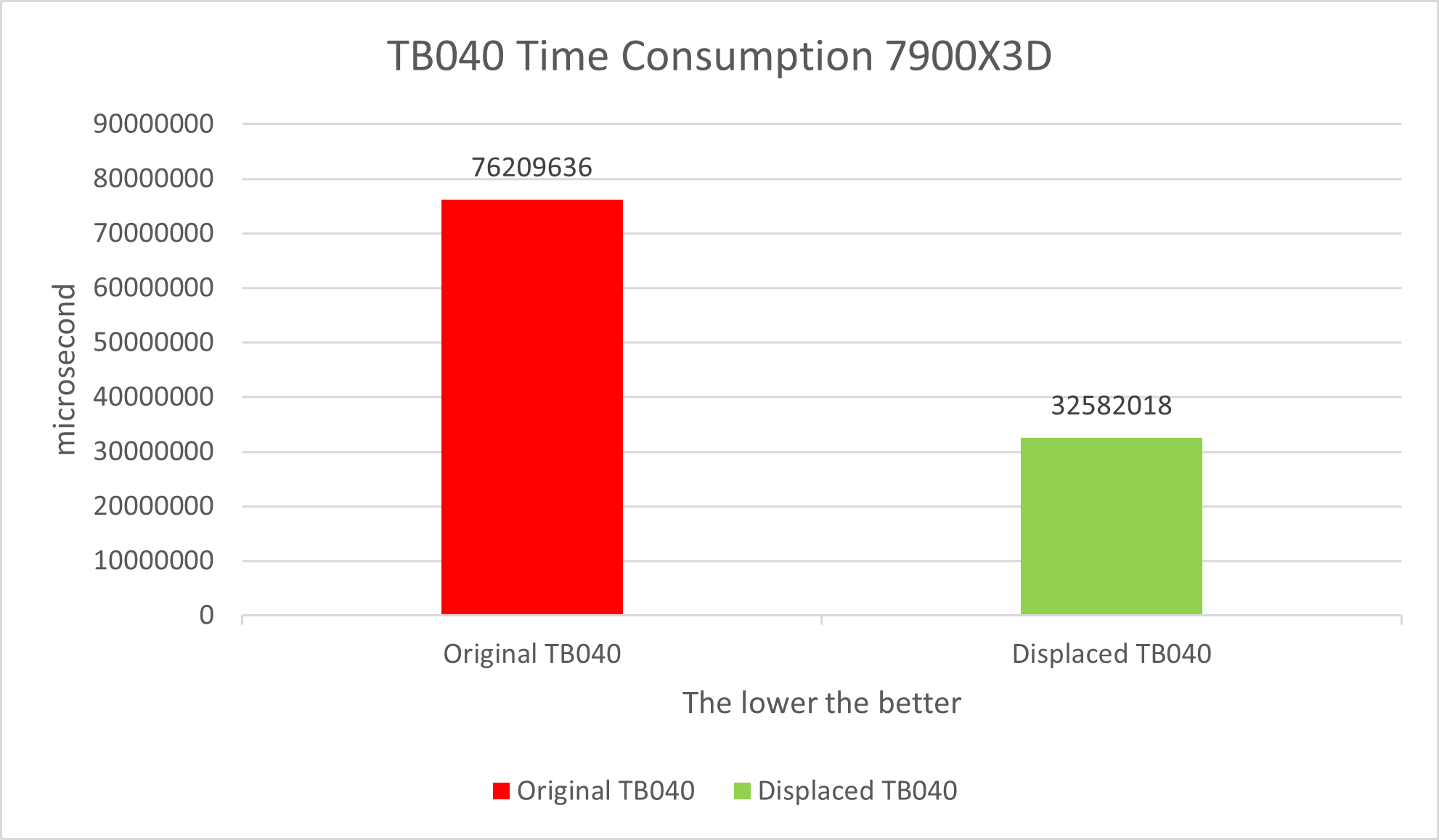 Table 1
Table 1
Although the numbers are good, take into account the difficulty and low compatibility of writing assembly code, you still need to balance performance gains against actual resource costs in developing projects.
Careful readers may find that at the beginning of the while loop, there is a jump instruction to determine whether add is 0 will not be triggered. The reason is that the implementation logic is flawed. The more accurate logic is do-while, which can be a little faster than while. Such minor errors are also easier to be spotted from an assembly perspective. However, do-while is slower than assembly that is optimized based on while. You can also try to optimize do-while logic using assembly instructions if you are interested.
This article introduces the possibility of writing assembly code to optimize the program with the Displaced TB040 as an example. So the readers can see why it is necessary to keep an assembly compiler, even when high-level language compilers are very well developed. If you are interested, you can refer to the source code of glibc or Visual C++. The underlying functions, such as memcpy and memset, are implemented separately on different CPU instruction sets using assembly instructions, so as to ensure optimal performance.
Now it is clear to the readers that optimization of assembly instructions can be divided into two directions:
You can choose your own solution based on actual needs. Noted, there are still two directions to choose from when using assembly directly:
The assembly compiler is adequate most of the time, but JIT is also ubiquitous in today’s basic software, such as virtual machines or simulators. Even some operators of deep learning frameworks are implemented by JIT. JIT has the potential to achieve the best performance on all hardware, but it takes time to generate JIT code, which requires a good balance between assembly code generation time and actual running time.
After reading this, readers should understand the various efforts made by different frameworks and systems to achieve performance. I sincerely hope that your programs can reach their optimal performance. Finally, I wish you all success in your work.