Radeon™ Rays
The lightweight accelerated ray intersection library for DirectX®12 and Vulkan®.
We assume, by default, that you have already read the Preface to the CPU Performance Optimization Guide, and that you have a general understanding of the basic concepts of CPU performance optimization. This part of the series will again introduce a problem encountered in an actual project to give you a deeper understanding of how a good algorithm affects the CPU, and bring some help to your own project hopefully. Keywords: CPU clock; instruction number; algorithm.
A challenge that may arise in project development is how to accomplish a specific function (e.g. simulate floating-point operations with integer instructions on a single-chip microcomputer with limited floating-point hardware functions) with a limited number of instructions. Or we simply want to reduce the number of instructions, in the hope of reducing the execution time, so as to obtain a higher throughput.
First of all, the latency of each instruction in the CPU is not the same. We choose the most common integer instruction this time, and the goal is to get the nearest square root of the integer using only the integer instruction.
Then comes the compiler. Due to the popularity and ease of use of Microsoft® Windows® 10, Microsoft® Visual Studio® 2022 is selected as the development environment, the version we use is 17.9.2. The compiler version is 19.39.33521. The compiler type is x64 RelWithDebInfo. The operating system version is 10.0.19045.4046.
Finally, the CPU needs to be identified because the architecture is constantly being updated. The latency of each instruction varies from CPU to CPU. And because of the strong dependence on hardware, the CPU determines the performance analyzer can be used. The CPU used here is an AMD 7900X3D, so the performance analyzer used here is AMD μProf, version 4.2.845.
Now we have set the stage, it’s time to build the benchmark. The benchmark needs to meet the following conditions:
As this goal is relatively simple this time, our data set is all the unsigned integer ranges that uint32_t can cover, which is of sufficient magnitude to ensure the accuracy of the performance data.
The algorithm needs to be verified. Each integer will be compared with the result of std::sqrt to ensure the correctness of the algorithm.
The test function is the focus of this blog. When it comes to the challenge of using only integer instructions to get the nearest square root of an integer, the simplest and fastest design I have ever seen is Microchip TB040. It makes use of the bit operation of integers, which makes the calculation amount of the algorithm tend to be linear. The following is a simple implementation. For exactly how it works, you can refer to the paper itself.
1. uint32_t TB040(uint32_t x) {2. uint64_t x_ = x;3. uint32_t res = 0;4. uint32_t add = 0x80000000;5.6. while (add) {7. uint32_t g = res | add;8. if (x_ >= (static_cast<uint64_t>(g) * g)) {9. res = g;10. }11. add >>= 1;12. }13. return res;14. }TB040 is quite good already, especially on the hardware-limited single-chip microcomputer. But it can still be improved. When the algorithm itself is already good enough, reducing its workload is a good direction to optimize. On hardware with good bit calculation support, the add variable in TB040 may not be initialized to a fixed value, but may be set according to the position of the most significant bit of x. Due to the nature of the square root, the initial position of add can be set to half the index of the most significant bit of x to reduce the amount of computation.
15. inline unsigned long clzll(uint32_t v) {16. unsigned long lz = 0;17. _BitScanReverse(&lz, v);18. return lz;19. }20.21. uint32_t add = 1 << (clzll(x) >> 1);Here we use the bsr instruction to fetch the most significant bit. Instructions such as lzcnt and std::bit_width() in C++20 have similar functionality, but we’ll leave it to the readers to explore.
The performance test needs to be run a few more times and average the data to prevent hopping. It is clear that the optimized TB040 runs faster than the original TB040. The data is as expected, because the displacement reduces the amount of computation by at least half, which allows the algorithm to achieve greater throughput.
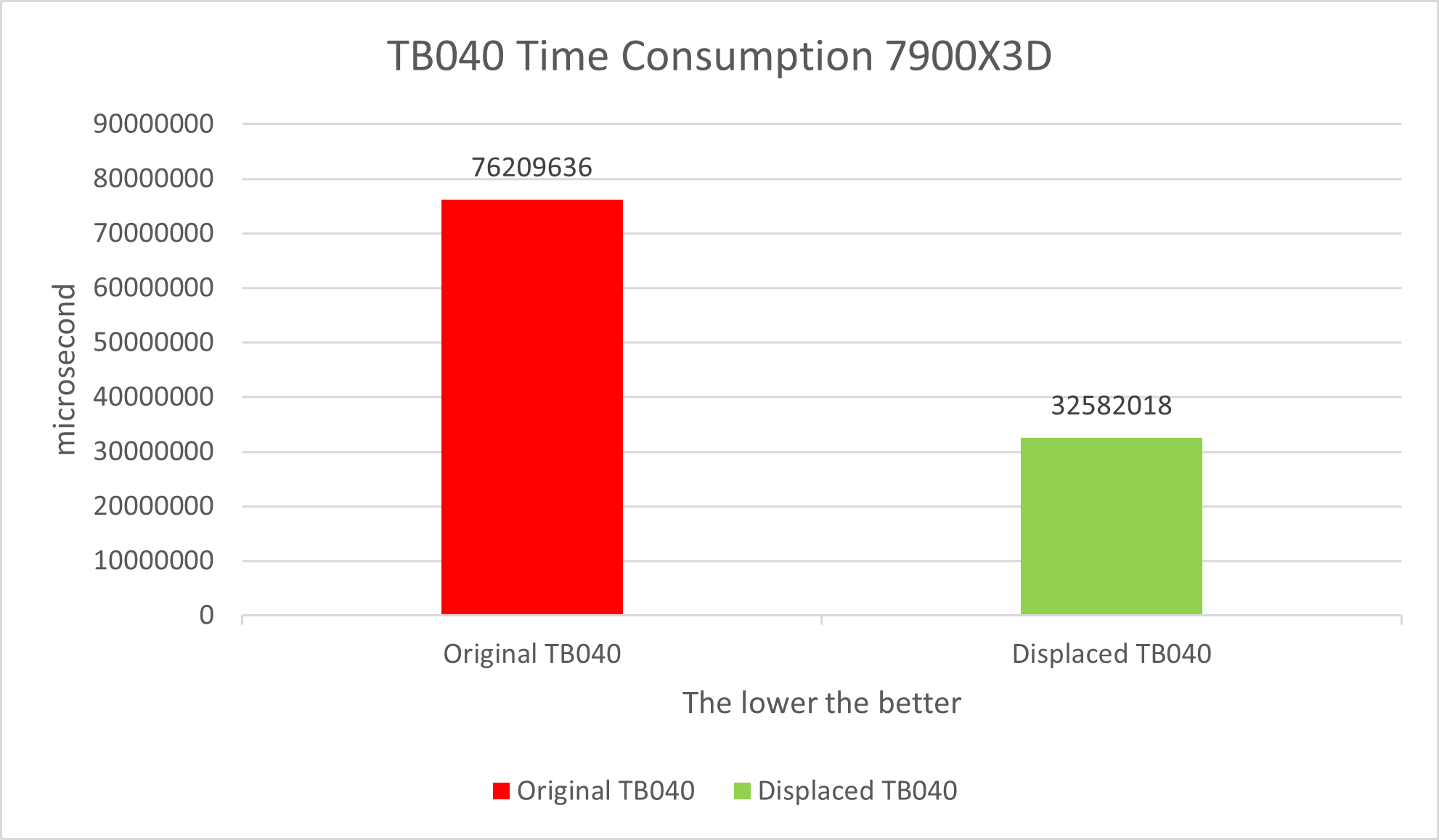
Table 1
The next phase is to analyze the performance, with a focus on the PMC within the Performance Analyzer.
Use the Performance Analyzer to analyze PMC, using Assess Performance (Extended) for the option set. After the run, switch to the ANALYZE page, and then switch to the IPC view to check the instructions and the PMCs. The CPU clock running is CYCLES_NOT_IN_HALT, and the number of instructions is RETIRED_INST. Dividing RETIRED_INST by CYCLES_NOT_IN_HALT gives us the IPC, which is the number of instructions run per unit of time. The higher the IPC, the better. Do it in reverse gives us the CPI, which is the CPU clock consumed by a single instruction. The lower the CPI, the better. These names may vary in different versions of the performance analyzer. It hinges on the corresponding hardware PMC in the PPR.
Let’s start with the data of the original TB040. IPC performs well with few problems. Let’s keep in mind the CPU clock and the number of instructions.
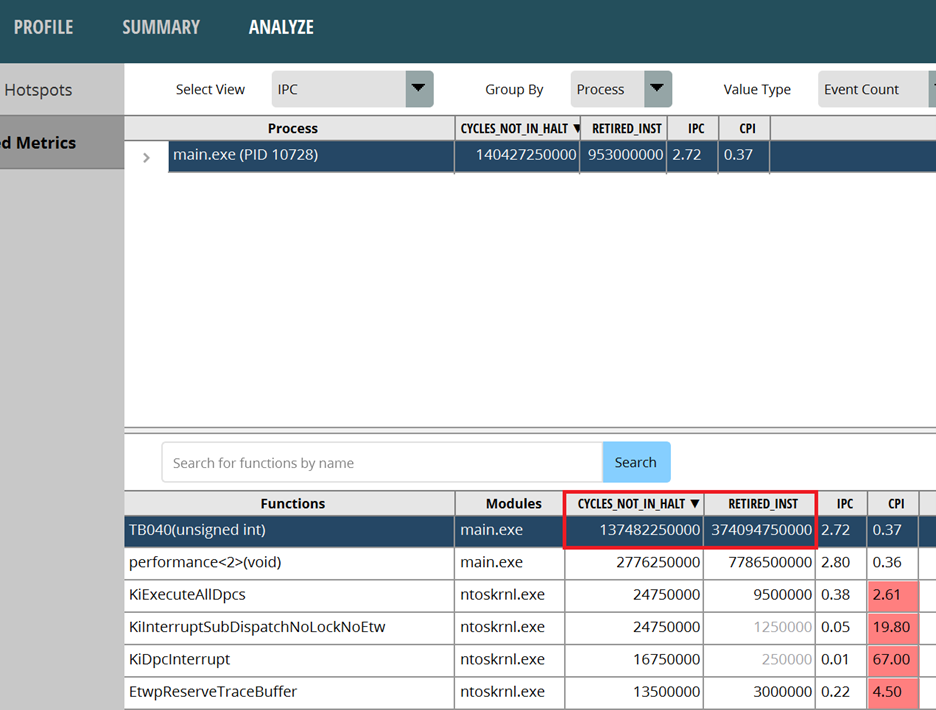
Figure 1: the original TB040
Let’s look at the data of the displaced TB040. IPC performs better, with less than half the CPU clock and about half the number of instructions compared to the original TB040. Obviously, if we want to optimize an algorithm that is already pleasing enough, a feasible way is to minimize the number of instructions and the CPU clock.
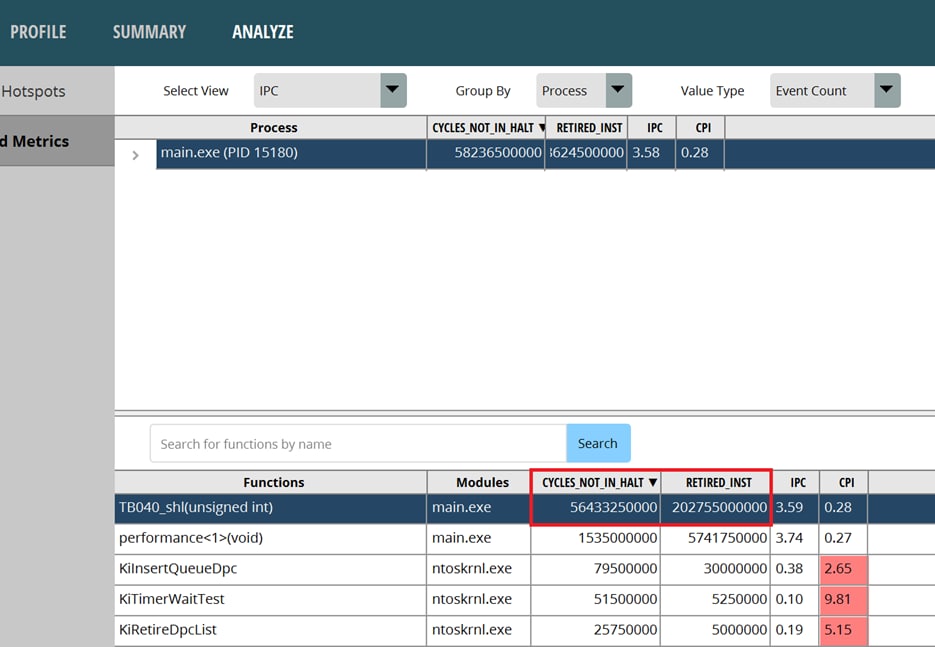
Figure 2: the displaced TB404
Taking TB040 as a simple example, this blog introduces how to analyze the PMC and provides a solution to optimize the number of instructions. However, optimizing the number of instructions is a complex topic. The example presented in this blog is just one of the more common ones.
TB040 has other implementations, of course. But the underlying mechanisms are mostly similar. You may refer to GeeksforGeeks or JensGrabner’s implementation mentioned in foobaz to do your own performance analysis. You can also try extending TB040 to support uint64_t and see what other pain points there are.
Now, we have completed a whole process of analyzing the number of CPU instructions. The huge differences in the number of CPU instructions and the clock cycle caused by different amounts of computation can be found. It’s also a part of the software optimization effort to ensure that your program can perform its functions with as few CPU instructions and clock cycles as possible.
Finally, I wish you all success in your work.