
AMD Capsaicin Framework
Capsaicin is a Direct3D12 framework for real-time graphics research which implements the GI-1.0 technique and a reference path-tracer.
Recent advances in generative techniques [1] exhibit the ability to generate images with visually appealing content and illumination. Strong priors in generative models, learned from a large-scale datasets, have enabled the breakthrough, ushering a new era in neural rendering. While there has been some research focusing on realistic and controllable lighting effects with diffusion-based models, they still lack the capability to produce specific lighting effects. Particularly, generating multi-bounce, high-frequency lighting effects like caustics remain untackled in diffusion-based image generation.
Diffusion-based models [2] have demonstrated the capability of generating photorealistic images in various domains. Nevertheless, some research addresses the limitation of the current diffusion model-based image generation for shadows and reflections, while introducing conditioned diffusion models to model the lighting with single bounce shading and mirror reflection as a depth conditioned image inpainting task.
We leverage diffusion-based techniques to generate an indirect illumination of a particular lighting effect. Specifically, our technique enables a diffusion model to generate cardioid-shaped reflective caustics as a conditional image generation task.
We use a latent-space diffusion model as our baseline architecture and set multi-image conditioning and light embeddings. We use geometric and material information like albedo, normal, roughness, and metallic as conditioning images, augmenting them with illumination information like direct illumination and radiance cues. These conditioning images are encoded into latent space using a pre-trained Variational Autoencoder (VAE) encoder. Light position encoded by Positional Encoding and light direction encoded by Spherical Harmonics form an additional input to the diffusion UNet. Figure 1 presents our framework with a conditional diffusion model for generating caustics effect.
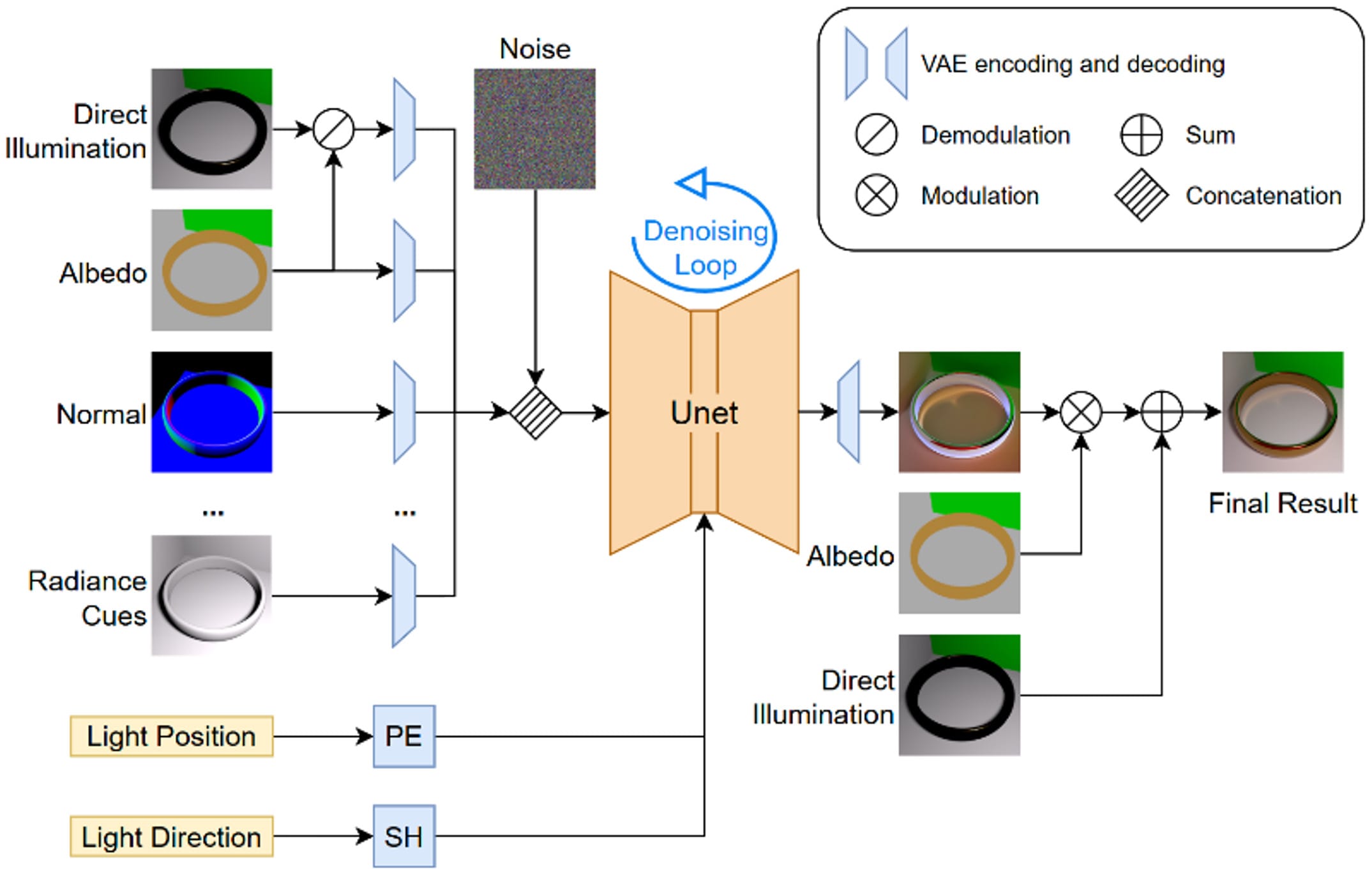
Figure 1. Framework with a conditional diffusion model.
We fine-tune a latent-space diffusion model using our caustics dataset and demonstrate our approach generates visually plausible cardioid-shaped caustics. The conditioning information that includes geometric, material and illumination data, as well as light property, is easily obtained from existing rendering pipeline.
Figure 2 shows our results for validation data (Top) and test data (Bottom). The indirect illumination (Figure 2 (b)) is generated from our fine-tuned diffusion model and composited to the direct illumination (Figure 2 (a)), which is one of our conditioning images, to present a final result (Figure 2 (c)).

Figure 2. Our results. (a) Direct illumination, (b) Indirect illumination in our result, (c) (a)+(b) our result, (d) Reference global illumination.
Figure 3. (Left) Our result. (Right) Reference global illumination.
Our work paves a way to interesting research for generative diffusion-based models to be capable of specific indirect illumination effect generation. Further details can be found in our paper [3] presented at Eurographics 2025 – Short paper.







