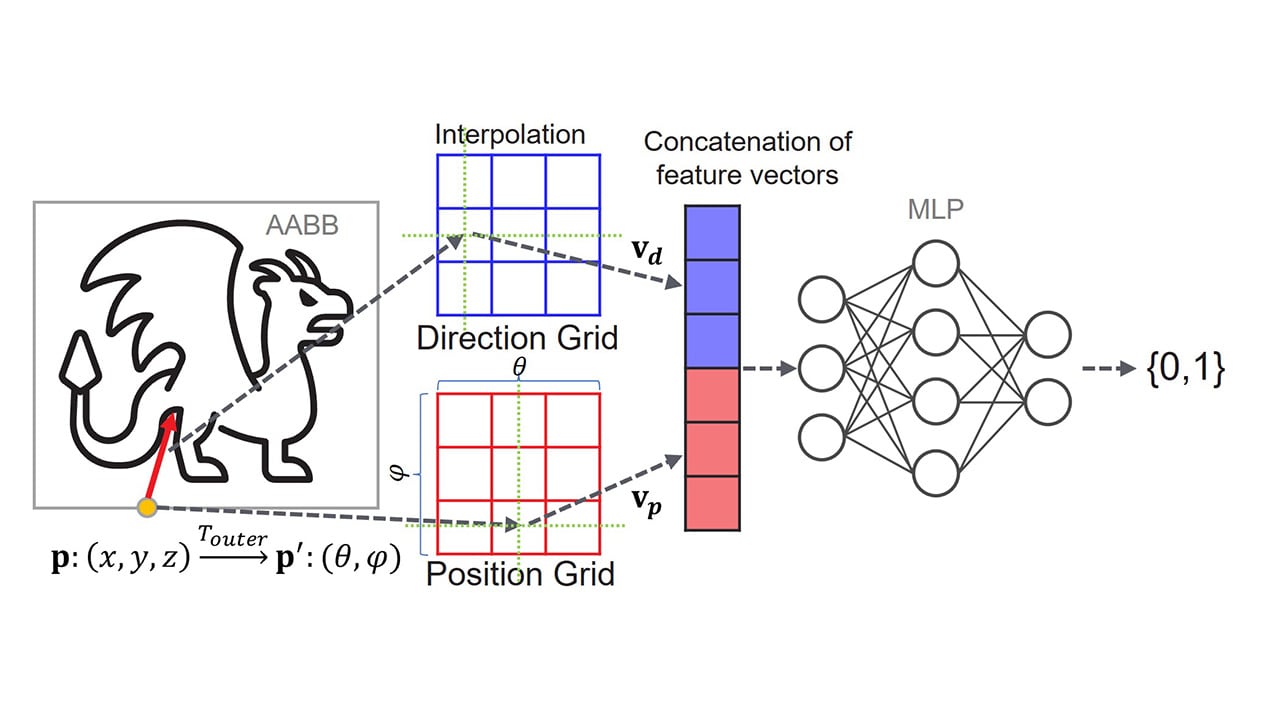
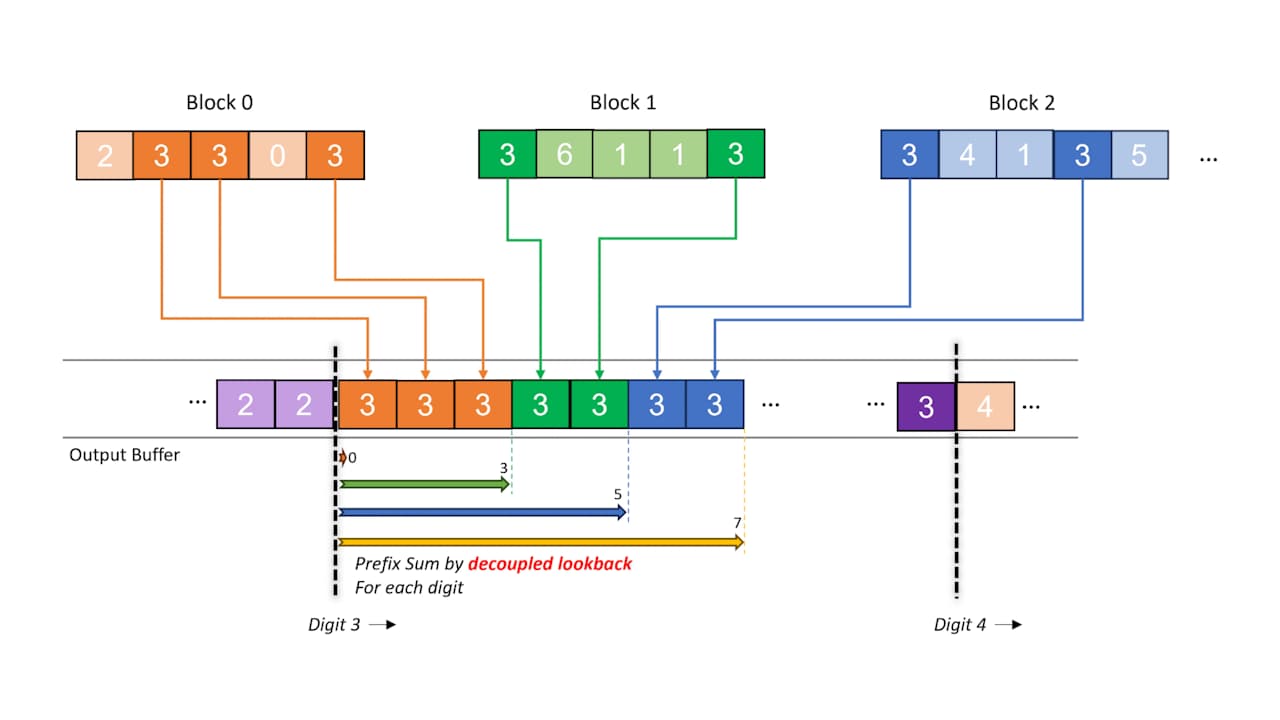
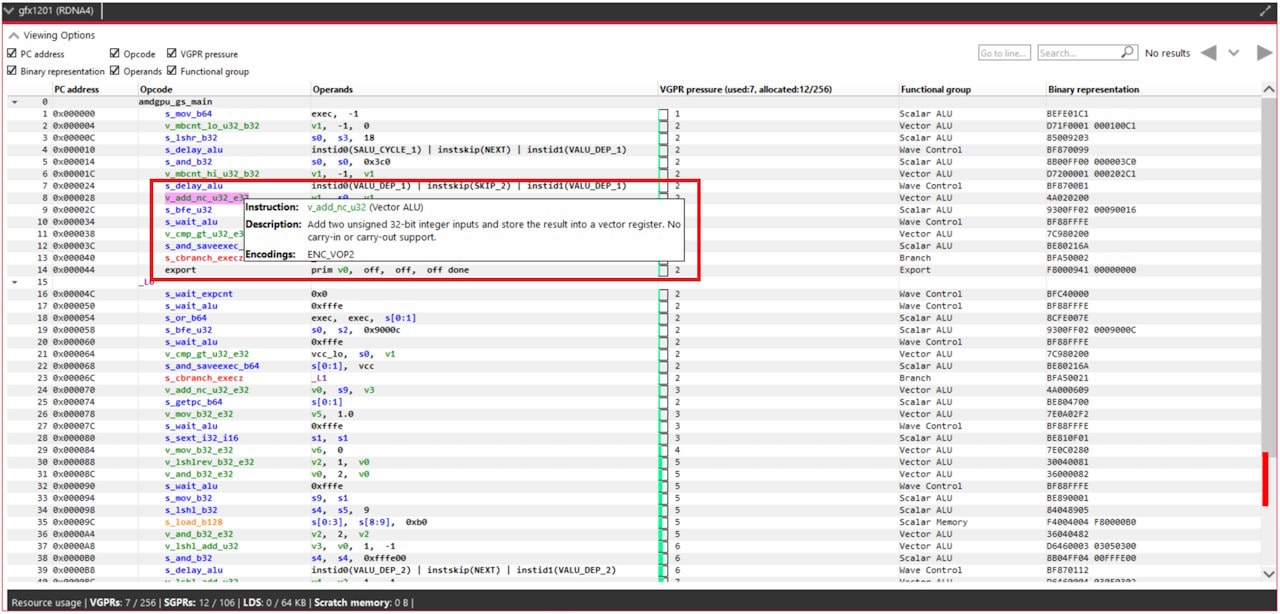
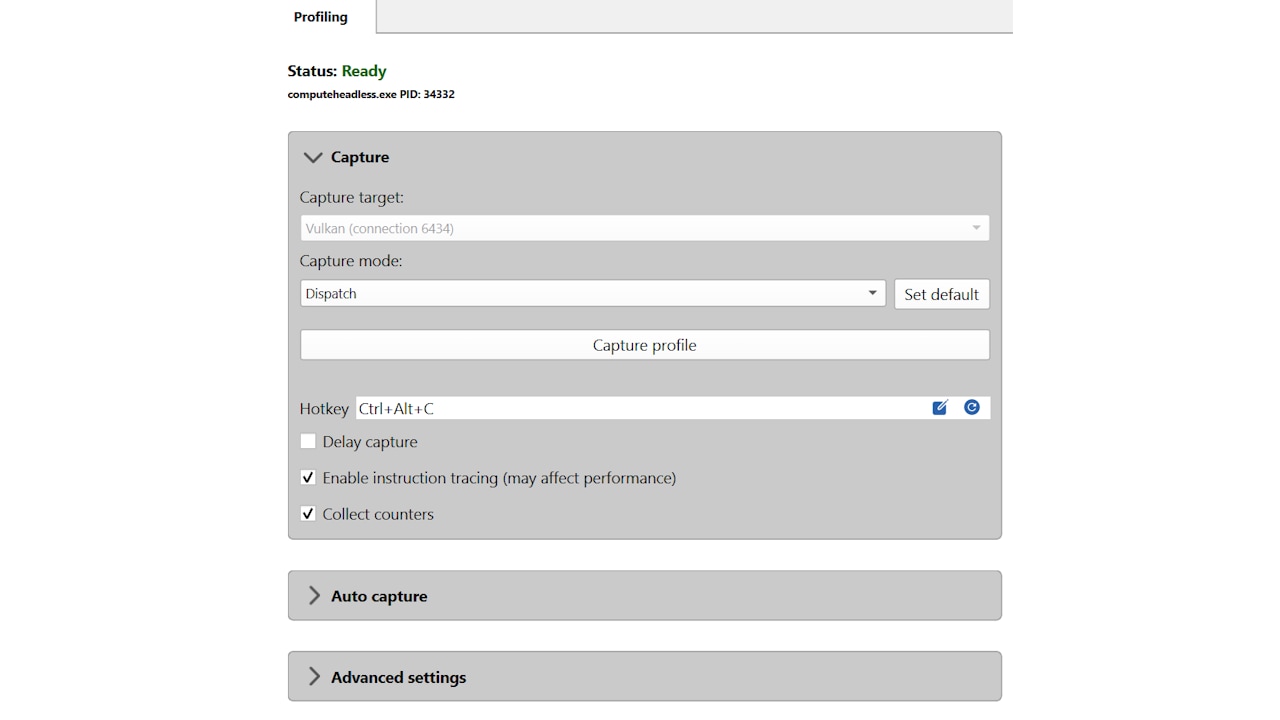
Integrate AMD FidelityFX™ Super Resolution 3.1.4 today
AMD FidelityFX Super Resolution 3 (AMD FSR 3) technology combines temporal upscaling and frame generation to deliver massive framerate boosts in supported games.
FSR 3.1.4 includes a signed, easily swappable DLL - making upgrades simpler than ever. Integrate FSR 3 with minimal friction, and benefit from improved upscaling quality, reduced ghosting, and more.
+ Get the source code today!