Radeon™ Rays
The lightweight accelerated ray intersection library for DirectX®12 and Vulkan®.
Here at Enscape we would like to share some insights as to how we designed a renderer that produces path traced real time global illumination and can also converge to offline rendered image quality.
Enscape is a plugin for architectural design software like Autodesk® Revit®, SketchUp or Rhino. It enables architects to get a high quality real-time rendering from within the planning stage – without exporting or importing. Changes in the underlying BIM (Building Information Modeling) data, like a modification of the floor plan or the activation of a so called “design option” is reflected immediately.

Since CAD data is not specially prepared for real time rendering, global illumination is of high importance. Even for undetailed geometry without a lot of lights, it enables the viewer to grasp the underlying ideas and scales.
Ideally, we want a GI solution that can be scaled across different hardware capabilities and can even produce photorealistic, crisp images at offline quality – if given a bit more time.
Since we want to change the time of day instantaneously and want very little loading times, light map baking is not an option.
Additionally, glass is a design element of high importance – which means, we need sharp and correct reflections. Therefore, solutions like Light Propagation Volumes are not suitable. Even Voxel Cone Tracing struggles with pixel sharp off-screen reflections.
For the previous version of our renderer, we used an automated cubemap placement algorithm. It placed cubemaps at positions where the average lengths or random rays that were cast from the cubemap were locally maximized. This was done at runtime and the cubemaps were updated when the lighting (or scene) had changed in their radius of influence. Combined with screen-space diffuse rays, it gave plausible results, but the amount of cubemaps had to be enormous to cover medium frequency GI phenomenas.
The core algorithm of classic Whitted-Style path tracing is brute force in nature, so we need to optimize here. We faced the following problems after naively implementing it:
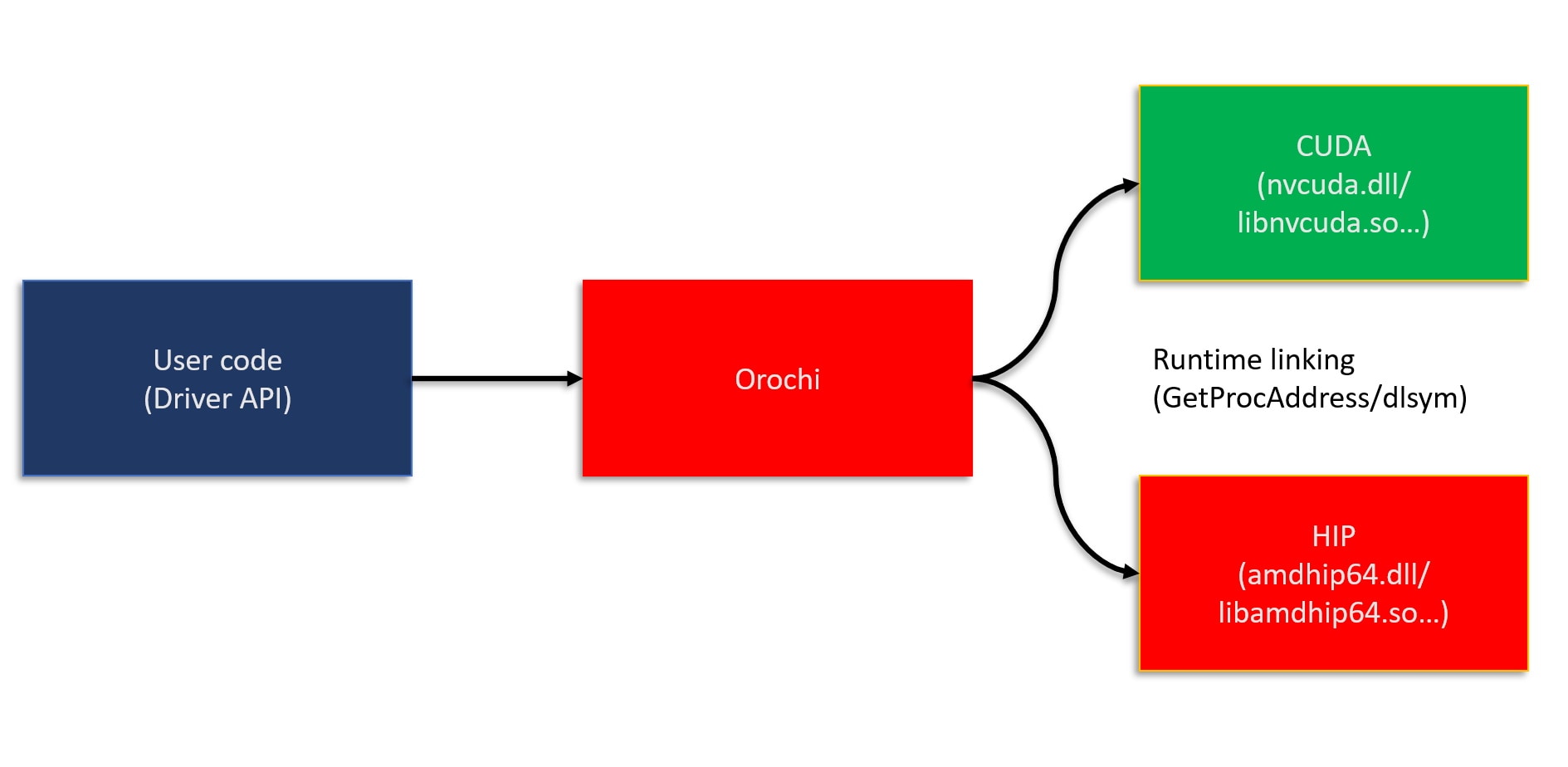
We use Radeon Rays (formerly AMD FireRays) for the BVH construction and traversal. We vary between different tracing kernels across different hardware setups to achieve the best possible performance. We ported the stackless traversal algorithm to run on OpenGL® 4.2 hardware, so that the kernel runs in a plain fragment or vertex shader without the need for Compute Shader or OpenCL™.

We completely avoid casting primary rays by using our G Buffer as a starting point.
We then accumulate ray samples across multiple frames to solve each fragment’s BRDF. A mapping function defines a distinctive ray direction for a group of four fragments (half resolution). We use a global low-discrepancy seed per frame and a local random value which comes from a noise texture. Using any plain pseudo-random sampling must be avoided, since it will lead to visible artifacts.

First, we try to cast the diffuse rays in screen space. If we’re able to detect a hit in the last frame’s irradiance buffer, we even get a local multi bounce reflection for free. If a screen space intersection wasn’t found, we path trace the ray in our BVH (Fig 1). This optimization alone saves 30% of the first bounce of secondary rays, depending on the scene.
For specular, we basically do the same and vary the number of local samples based on the materials roughness and metallic-value.
In order to get coherent data access, we bundle our rays into separate workgroups (or in terms of the OpenGL 4.2 implementation: different draw calls).
We bundle 12 world space direction segments into separate buckets, based on their generated ray direction. The usage of a tiled noise lookup texture during ray creation ensures that those buckets are roughly equally sized.
Tracing the directions separately both in screen space and for path tracing improves cache coherency.
Building the BVH for a complete architectural scene will fail very quickly under real-time constraints and hardware limitations. Therefore, we only store a fraction of the scene at a time. We determine what objects to include into the BVH based on their estimated visual importance weighted against their BVH cost (Fig 2).
float objectScore = lightingRelevance \* visibleVolume / polycount;while(sumOfObjects > BVH\_COMPLEXITY\_THRESHOLD)deleteObject(getWeakestScoreObject);This BVH update is done on the CPU and continuously uploaded to the GPU. The update is divided into smaller chunks to avoid lags during memory transfer.
Mesh preprocessing is usually necessary because high polygon objects occur pretty frequently and can slow down the BVH traversal. It’s important to only “shrink” objects during simplification to avoid self-occlusion.
Special objects like leaves are converted into procedurals, which are compactly stored in the BVH. In terms of vegetation, the self-occlusion is not too noticeable, but the overall shape and density has to be maintained to look plausible in reflections.

For every ray intersection in our BVH, we calculate incoming sun light using a shadow map lookup. For artificial lights or emissive surfaces (which can be thousands per scene), lighting calculation during traversal is not feasible. Therefore, we bake the direct light (except the sunlight) into the BVH on a per vertex basis. We re-tessellate the geometry anyway, so it’s easy to enlarge the tessellation density at points where we expect direct light detail.
This gives us the advantage of reduced memory fetches for direct lights and also allows to change the sunlight with no special precomputation or update time, other than the usual sun shadow maps.
For the material’s reflective component, we sample at half resolution and use previous sampling results to combine them to a high-resolution image. The filtering is done BRDF aware, to keep the smearing and blurring artifacts at a minimum. For high quality outputs, we even create a refinement queue based on unexpected variance in a 3×3 pixel quad to get full, high resolution image quality.
We support order independent transparency and want to use the path traced reflections on those surfaces as well. The challenge is the unpredictable layer depth and the required performance budget. We therefore render every layer in a deferred shading style and run our specular tracing in upsampled half resolution. We do not store a separate history buffer for each layer, so we have to accept a little blur to hide the missing history which would be required for a proper temporal upsampling to reach a higher quality.
We use several temporal accumulation buffers to keep the neighborhood clamp window as small as possible. The new results are first combined with the accumulation buffer (Fig 3) before filtering to avoid smearing. Before filtering, we compute the expected radius in a local neighborhood to keep the amount of texture reads at a minimum.

The critical point, besides overall rendering performance, is a content agnostic ray traversal cost. The screen space ray traversal performance is not dependent on the scene complexity and can be scaled in terms of sample count and march length. In most cases in architecture, the number of polygons in the BVH correlate with the traversal cost. Keeping the BVH complexity constant is therefore key. We measure the tracing and overall rendering performance at run time and adjust the allowed BVH complexity. We even adjust the image resolution to keep a steady frame rate. Multi bounce diffuse lighting however is currently only enabled on our Ultra profile.
We continuously improve our real-time path tracer and intend to publish more details about it in the future. If you want to join us at our office in Karlsruhe (Germany), send an email to jobs@enscape3d.com.