Introduction
Monte Carlo ray tracing is a cornerstone of physically based rendering, simulating the complex transport of light in 3D environments to achieve photorealistic imagery. Central to this process is ray casting which determines and computes intersections between rays and scene geometry. Due to the computational cost of these intersection tests, spatial acceleration structures such as bounding volume hierarchies (BVHs) are widely employed to reduce the number of candidate primitives a ray must test against.
Despite decades of research and optimization, BVH-based ray tracing still poses challenges on modern hardware, particularly on Single-Instruction Multiple-Thread (SIMT) architectures like GPUs. BVH traversal is inherently irregular: it involves divergent control flow and unpredictable memory access patterns. These characteristics make it difficult to fully utilize the parallel processing power of GPUs, which excel at executing uniform, data-parallel workloads. As a result, even with the addition of specialized ray tracing hardware, such as RT cores, the cost of BVH traversal remains a bottleneck in high-fidelity rendering workloads.
In contrast, neural networks, especially fully connected networks, offer a regular and predictable computational pattern, typically dominated by dense matrix multiplications. These operations map well to GPU hardware, making neural network inference highly efficient on SIMT platforms. This contrast between the irregularity of BVH traversal and the regularity of neural network computation raises an intriguing question: Can we replace the BVH traversal in ray casting with a neural network to better exploit the GPU’s architecture?
This idea is beginning to gain traction as researchers explore alternative spatial acceleration strategies that leverage learned models. In this post, we dive into the motivation behind this approach, examine the challenges and opportunities it presents, and explore how our invention, Neural Intersection Function, might reshape the future of real-time and offline ray tracing.
Introducing the Neural Intersection Function (NIF)
The Neural Intersection Function (NIF) represents a significant departure from traditional BVH-based ray tracing. Proposed by AMD in 2023 [1], NIF integrates a neural network directly into the ray tracing pipeline, aiming to replace the irregular BVH traversal with a more GPU-friendly, regular computation.
Architecture and novelty
At the heart of NIF lies a multilayer perceptron (MLP) designed to evaluate the visibility of secondary rays. Unlike BVH traversal, which involves divergent memory access and branching—patterns that hinder GPU performance, NIF’s MLP operates through dense matrix multiplications, ensuring predictable memory access and efficient parallel execution on GPUs.
The architecture comprises of two main components: Outer Network and Inner Network. These two networks handle rays originating outside or inside the object’s AABB, respectively. Both networks utilize grid encoding to represent spatial features, determining visibility by processing ray-AABB intersection information, and use it as indices to retrieve the features stored in the grid.
With its architecture, the NIF enables efficient computation and seamless integration into the ray tracing pipeline. Notably, it represents the first approach by AMD to incorporate a neural network within a BVH-based ray tracing framework. By targeting the most irregular and performance-critical component, namely the bottom-level BVH traversal, NIF offers a unified and accelerated solution for ray casting.
Through the use of grid encoding and MLPs, NIF replaces the most divergent aspects of BVH traversal with dense matrix multiplications. These are regular, predictable operations that map efficiently onto modern GPU hardware, leveraging specialized units such as AMD Matrix Cores, NVIDIA Tensor Cores, and Wave Matrix Multiply-Accumulate (WMMA) instructions for significant performance gains.
The experimental results demonstrate that NIF can reduce secondary ray casting time for direct illumination by up to 35% compared to traditional BVH-based implementations, all while maintaining image quality.
Figure 1 illustrates the architecture of the Outer network of NIF.
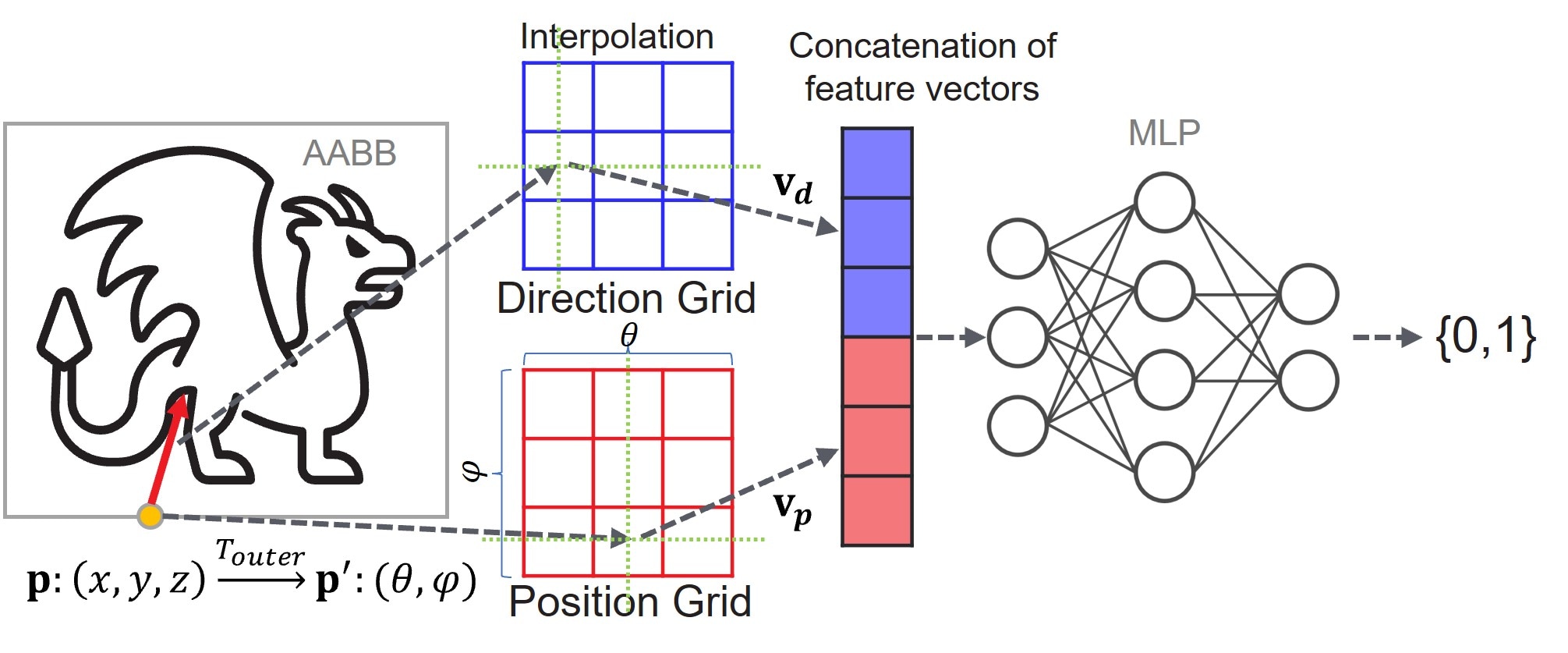 Figure 1: The outer network of NIF. Starting from the left of the figure, the original 3D position is converted into a 2D spherical coordinate by the transformation function. After that, the 2D spherical coordinate is used to retrieve the corresponding feature vector from the grid. The final content of the feature vector is bi-linearly interpolated by considering the neighbor indices. Direction is handled by the same logic. Finally, the feature vectors are concatenated to form the input for MLP. During the backpropagation, those trainable feature vectors are also updated. The inner network adopts a similar architecture with an additional feature vector derived from the distance.
Figure 1: The outer network of NIF. Starting from the left of the figure, the original 3D position is converted into a 2D spherical coordinate by the transformation function. After that, the 2D spherical coordinate is used to retrieve the corresponding feature vector from the grid. The final content of the feature vector is bi-linearly interpolated by considering the neighbor indices. Direction is handled by the same logic. Finally, the feature vectors are concatenated to form the input for MLP. During the backpropagation, those trainable feature vectors are also updated. The inner network adopts a similar architecture with an additional feature vector derived from the distance.
Limitations
Despite its innovative design, NIF comes with several notable limitations. First, it relies on online training that is specific to the current viewpoint in a scene. While this allows NIF to adapt to dynamic environments through continual retraining, it also introduces latency and computational overhead. More critically, NIF still depends on traditional BVHs during the training phase to generate ground truth data, meaning it cannot fully eliminate the BVH structure from the rendering pipeline.
In addition, the original NIF is currently restricted to shadow rays, limiting its applicability across the full range of ray types used in rendering. From a memory standpoint, even though the neural networks are compact and compressed, they still impose a non-trivial memory overhead, particularly problematic for memory-constrained systems.
Enhancing NIF: The Locally-Subdivided Neural Intersection Function (LSNIF)
To overcome the limitations of the original NIF, we further proposed the Locally-Subdivided Neural Intersection Function (LSNIF) which introduces a more scalable and generalizable approach to neural ray-geometry intersection. Its key innovation lies in moving from per-scene, viewpoint-dependent models to per-object models that can be trained offline and reused across different scenes.
Architecture and design improvements
Unlike NIF, which requires online training tied to specific camera viewpoints and lighting, LSNIF adopts a viewpoint-agnostic design. Each object in a scene is independently trained using uniformly sampled rays, without dependence on lighting conditions or camera positions. This decouples model training from scene configuration and enables precomputation. The resulting models, comprising voxelized geometry, sparse hash grid encodings, and a compact MLP, can be stored on disks or hard drives and reused in real-time applications, eliminating the need for BVH traversal during rendering.
Moreover, LSNIF significantly expands functionality. It supports not just shadow rays, but also primary and other secondary rays, as well as those used in deeper stages of path tracing. The network predicts a range of geometric and material properties at ray intersection points, including visibility, surface normals, hit positions, albedo, and material indices. This broader scope makes LSNIF applicable to a wide variety of rendering tasks beyond shadow computation.
Figure 2 demonstrates the architecture of LSNIF.
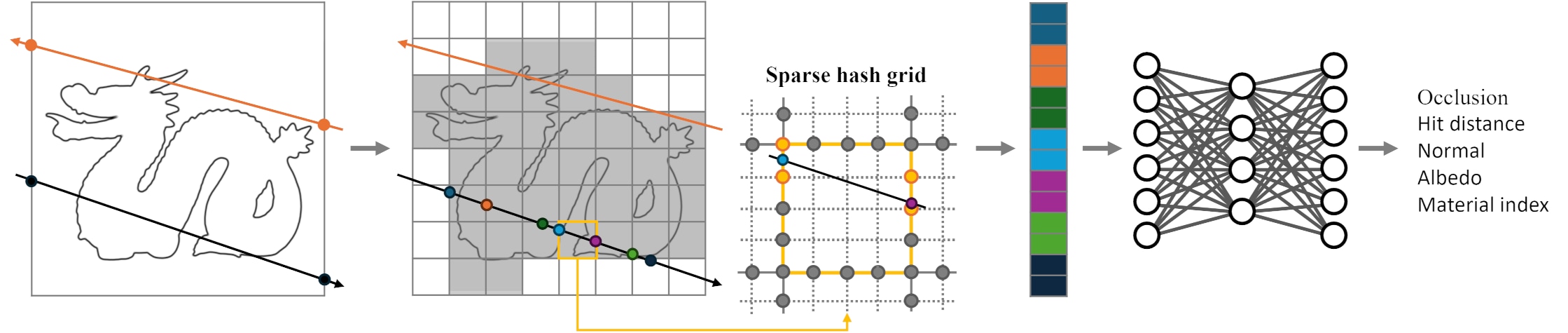 Figure 2: The illustration of LSNIF methodology. First, the intersection points of a ray with the object’s AABB are computed. These points are then used to perform DDA against the voxels, followed by the calculation of hit points on the surfaces of these voxels. The hit points are processed using 3D sparse hash grid encoding, with interpolated feature vectors concatenated into a large vector. This vector is then fed into the MLP which outputs the intersection information of the ray with the geometry.
Figure 2: The illustration of LSNIF methodology. First, the intersection points of a ray with the object’s AABB are computed. These points are then used to perform DDA against the voxels, followed by the calculation of hit points on the surfaces of these voxels. The hit points are processed using 3D sparse hash grid encoding, with interpolated feature vectors concatenated into a large vector. This vector is then fed into the MLP which outputs the intersection information of the ray with the geometry.
Solving ray aliasing with local voxelization
A major challenge in learning ray intersections is ray aliasing, where similar ray directions from different origins may converge on the same point, which confuses the network. NIF partially addressed this by feeding in hit points and directions instead of origins, but this was still limited to static viewpoints.
LSNIF introduces a more robust solution by voxelizing each object’s surface geometry into a low-resolution grid in local object space. When a ray intersects an object’s bounding volume, it is further intersected with the voxels using a digital differential analyzer (DDA) algorithm. The resulting points that are situated near the object surface serve as distinct, informative inputs to the neural network. This method increases input diversity, improves learning, and reduces ray aliasing without requiring densely sampled ray origins or directions.
Importantly, only surface polygons are voxelized, and each voxel stores a simple binary occupancy flag, making the approach memory-efficient and compatible with arbitrary geometry.
Sparse hash grid encoding for efficient memory use
To encode the voxel-ray intersection points, LSNIF uses a sparse multi-resolution hash grid tailored to the voxel boundaries. Unlike traditional dense grids that store feature vectors across the entire 3D domain, the sparse grid stores values only where needed – on voxel boundaries. This design reduces memory consumption and improves inference speed by eliminating unnecessary memory access.
In practical terms, this reduces grid query complexity. For example, in 3D space, a dense grid may require eight vertex lookups per query, while the sparse grid requires only four. A hash table maps grid coordinates to memory addresses, enabling fast and flexible access to the encoded features.
Unified and efficient neural inference
Each object in LSNIF is assigned to a single, lightweight MLP that takes the concatenated feature vectors from the sparse hash grid as input. This MLP is trained to simultaneously predict multiple properties, such as visibility, hit distance, surface normal, albedo, and material ID, allowing for rich surface reconstruction and material representation in a single inference pass.
This unified prediction model is not only more memory-efficient than using separate networks for each property but also accelerates inference during rendering. Furthermore, supporting multiple material indices per object enables more realistic and complex visual outcomes, which is crucial for modern rendering pipelines.
Results and final remarks
To demonstrate the effectiveness of LSNIF, we present a series of rendered images comparing its results to traditional BVH-based ray tracing approaches. The figure below showcases both visual quality and numerical error metrics:

 First row: rendered images using LSNIF. Second row: rendered images without LSNIF, alongside their FLIP error visualizations. The rest are close-up comparisons between LSNIF and reference images.
First row: rendered images using LSNIF. Second row: rendered images without LSNIF, alongside their FLIP error visualizations. The rest are close-up comparisons between LSNIF and reference images.
As shown, LSNIF delivers high-fidelity results that closely match reference images, even at challenging edges and shadowed regions. The differences are often visually negligible, and the FLIP error maps confirm that LSNIF preserves perceptual quality.
In addition to static scenes, we evaluated LSNIF under dynamic conditions where both lighting and object transformations vary over time. The animation sequence below demonstrates that LSNIF remains stable and accurate as scene parameters evolve—highlighting its robustness and suitability for real-time and interactive applications.

By pretraining per-object networks and removing costly bottom-level BVH traversal, LSNIF provides a scalable, efficient, and high-quality alternative for ray-geometry intersection. Its ability to generalize across ray types and operate without scene-specific retraining positions it as a promising direction for the future of neural rendering.
Integrating LSNIF into a ray tracing pipeline
While the results shown earlier were rendered using custom GPU-accelerated software, LSNIF is not limited to bespoke solutions. It can also be integrated into conventional, industry-standard rendering pipelines. To demonstrate this, we developed a prototype renderer based on the Microsoft DirectX® Raytracing (DXR) API, the standard for hardware-accelerated ray tracing in modern graphics applications.
In our implementation, LSNIF is realized as a custom intersection shader. During ray traversal, instead of intersecting against traditional geometric primitives like triangles, the shader executes a neural inference step to determine if and where a ray intersects the implicit surface defined by LSNIF. This approach enables the use of LSNIF not just for primary visibility, but also for secondary rays—reflections, shadows, and global illumination.
Figure 3 showcases images rendered entirely with this DXR-based renderer. The scene contains instanced LSNIF-represented Stanford Bunny models, with no traditional geometry buffers — no BVH structures, no vertex or index buffers. All spatial queries are handled by the LSNIF through inference.
 Figure 3: LSNIF objects rendered using the DirectX® Raytracing API and Image-Based Lighting (IBL). The shader invokes inference whenever there is a hit between a ray and the AABB of an LSNIF object. It supports both transformations of objects as well as camera movements.
Figure 3: LSNIF objects rendered using the DirectX® Raytracing API and Image-Based Lighting (IBL). The shader invokes inference whenever there is a hit between a ray and the AABB of an LSNIF object. It supports both transformations of objects as well as camera movements.
In summary, this demonstration highlights that LSNIF is not just a research tool. It is a viable representation that can be integrated into real-time or offline rendering pipelines. Future improvements in GPU programming models could make neural implicit surfaces a first-class citizen in production rendering systems.
We are going to present LSNIF at the upcoming I3D 2025 conference [2]. Further details can be found in the paper we are going to publish soon.
References
- Neural Intersection Function, Shin Fujieda, Chih-Chen Kao, Takahiro Harada, High-Performance Graphics – Symposium Papers, 43-53 (2023)
- LSNIF: Locally-Subdivided Neural Intersection Function, Shin Fujieda, Chih-Chen Kao, Takahiro Harada, ACM SIGGRAPH Symposium on Interactive 3D Graphics and Games (2025)
DirectX is a registered trademark of Microsoft Corporation in the US and other jurisdictions.