



Since 2016, HIP has been generally available as a cross-platform alternative to CUDA as a GPGPU programming language. At compile-time, HIP uses AMD’s implementation when compiling on an AMD platform, whereas it would translate HIP calls to CUDA calls with next to no overhead if compiling on a NVIDIA® platform. While this allows you to use a single API that compiles for both AMD and NVIDIA GPUs, it does so only at compile-time.
Compiling HIP for both NVIDIA and AMD GPUs would either necessitate maintaining a separate backend for CUDA and HIP for a single binary, or compiling two separate binaries on NVIDIA and AMD platforms respectively. This isn’t always ideal and can be be cumbersome to maintain.
Henceforth, we refer to HIP as AMD’s platform and CUDA as NVIDIA’s platform.
Orochi is a library that loads HIP and CUDA® driver APIs dynamically at runtime. By switching the CUDA/HIP calls in your app to Orochi calls, you can compile a single executable that will run on both AMD and NVIDIA GPUs. This streamlines the deployment of your GPU accelerated applications and makes it easy to provide cross-platform support with a single API, thus eliminating the overhead of maintaining separate backends for each platform. We chose the name Orochi as it’s named after the legendary eight-headed Japanese dragon, which goes well with the purpose of our library – to allow a single library with multiple backends at runtime.
How it works
Orochi works by dynamically linking with the corresponding HIP/CUDA shared libraries at runtime. It looks for the shared library in your PATH and then loads the required symbols from it. If you use HIP on an AMD GPU, it will load the library installed with the AMD drivers on Windows®, or with your ROCm™ installation on Linux. Likewise, it will load the corresponding CUDA libraries for a NVIDIA GPU. Currently, both Windows and Linux are supported, with the potential for adding more backend GPU platforms in the future.
To use the library, simply include Orochi.h
and Orochi.cpp
in your project then call oroInitialize()
to load the symbols based on your API choice of either CUDA or HIP.
After this, simply replace all of your ” hip
..” calls and CUDA driver ” cu
..” or CUDA runtime ” cuda
…” calls with ” oro
…” calls. For example, hipInit()
and cuInit()
calls can be replaced with oroInit()
.
See below for a high-level illustration of how this works:
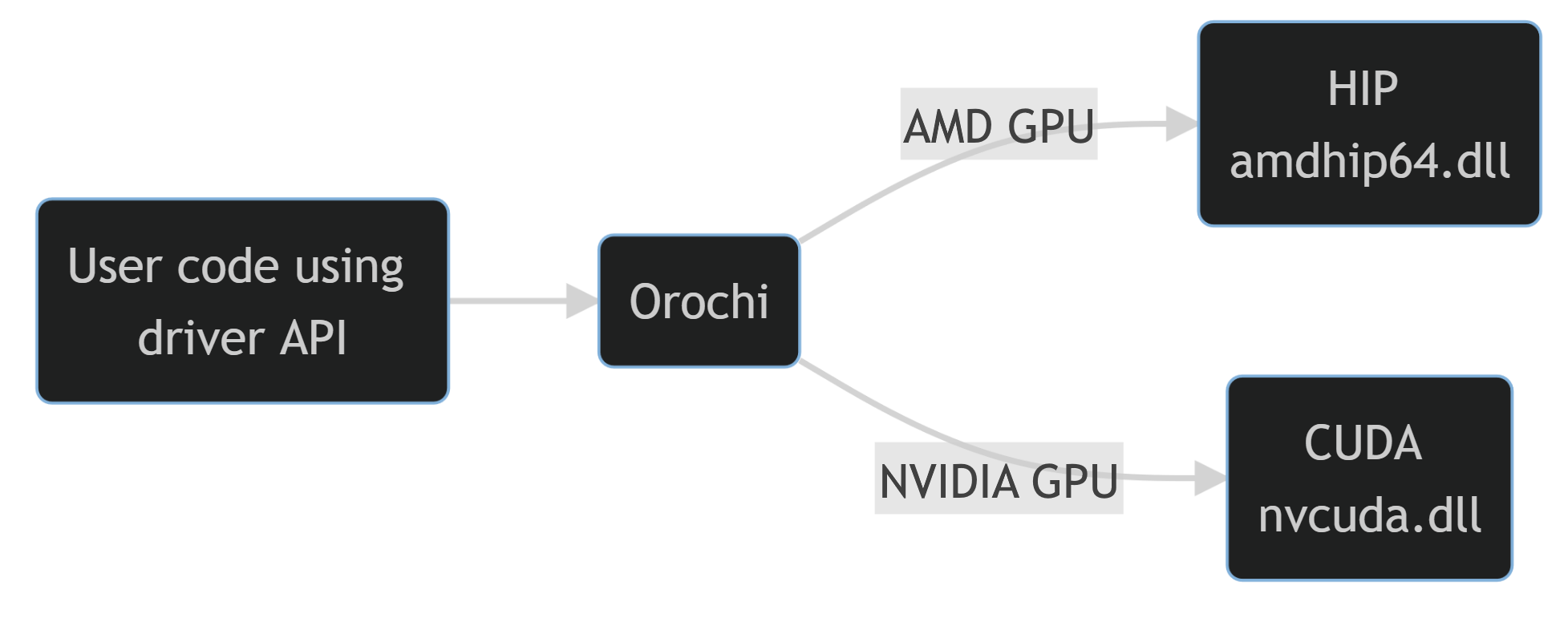
As you can see, the user code that calls Orochi functions such as oroInit()
will in turn call the corresponding CUDA ( cuInit
) or HIP ( hipInit
) function based on the backend provided to Orochi at runtime.
How to use Orochi APIs
Orochi APIs have the prefix: oro. If you are familiar with CUDA or HIP driver APIs, you will get used to these APIs very easily.
For example, suppose we have the following HIP code for device and context creation:
#include <hip/hip_runtime.h>
hipInit( 0 );
hipDevice device;
hipDeviceGet( &device, 0 );
hipCtx ctx;
hipCtxCreate( &ctx, 0, device );
The same code can be rewritten using Orochi as:
#include <Orochi/Orochi.h>
oroInitialize( ORO_API_HIP, 0 );
oroInit( 0 );
oroDevice device;
oroDeviceGet( &device, 0 );
oroCtx ctx;
oroCtxCreate( &ctx, 0, device );
This second example will run on both CUDA and HIP at runtime!
For a more detailed example, check out this sample application.
Building sample applications
A set of sample applications are included with Orochi in its GitHub repo.
To build these sample applications, run the following command:
./tools/premake5/win/premake5.exe vs2019
This will generate a .sln
file containing all three projects. The Test sample application provides an example of the minimum code required.
All of these sample application run on HIP by default, but if you want to run on CUDA, simply add the argument cuda when running the application.
Download Orochi today!
So what are you waiting for? Take a look at Orochi today!
Related content

Orochi
Orochi is a library which loads HIP and CUDA® APIs dynamically, allowing the user to switch APIs at runtime.

Primitive variables, flexible ramp node, beta support for HIP in Radeon™ ProRender SDK 2.02.11
The latest release of the ProRender SDK introduces support for primitive variables, enhanced Cryptomatte AOVs, AMD’s HIP API, and much more.
NVIDIA and CUDA are registered trademarks of NVIDIA Corporation.

Takahiro Harada
Takahiro Harada is a researcher and the architect of a GPU global illumination renderer called Radeon ProRender at AMD. Links to third party sites are provided for convenience and unless explicitly stated, AMD is not responsible for the contents of such linked sites and no endorsement is implied.

Aaryaman Vasishta
Aaryaman Vasishta is a researcher and software engineer at AMD. His research interests include real-time ray tracing, real-time neural rendering and GPGPU.







