TressFX
The TressFX library is AMD’s hair/fur rendering and simulation technology. TressFX is designed to use the GPU to simulate and render high-quality, realistic hair and fur.

This week marks the last in the series of our regular Warhammer Wednesday blog posts. We’d like to extent our thanks to Creative Assembly’s Lead Graphics Programmer Tamas Rabel for talking the time to spill the beans on the Total War: Warhammer engine. We hope you’ve enjoyed the series, so without further delay over to Tamas for the last instalment.
Crossfire and SLI are around for a while now. Most titles nowadays are using alternate frame rendering when it comes to multi-GPU rendering. AFR is relatively simple to implement and it just means while GPU 1 is rendering on frame N, GPU 2 is rendering frame N+1, effectively doubling framerate.
The biggest issue you would run into is the lack of control over the resources shared between GPUs. The drivers initially try to use a handful of different heuristics to figure out when to copy resources between cards. To stay on the safe side, drivers can often end up copying more resources than necessary, but this then gets more and more refined as the driver teams add game-specific patches to the drivers. AMD has their own extensions to get some more control over resource sharing, but that means adding vendor specific code, which is more maintenance. Usually what you want as a developer is to just manage all the inter-GPU communication yourself. This means copying the resource you want, the way you to and at the time you want to do it. For us that is at loading and initialization time. The other big rule for MGPU is that you don’t want to have any inter-frame dependencies. Inter-frame dependency means that the two (or more GPUs) can’t work in parallel anymore. This is because one of the GPUs will have to wait until the other GPU finishes rendering the resources which the other GPU is dependent on.

Luckily, we were already quite close to these goals due to the DirectX11 MGPU work we’ve already done during Rome 2 and Attila. There is no temporal filtering in Warhammer, which is mostly because MGPU was always an important scenario for us. The only part of the pipeline which had inter-frame dependency was particle simulation. We do all the particle simulation on the GPU. We don’t read any of the particle data back to the CPU, but that means that we have to keep the contents of the particle buffers between frames. There is just no way cutting this dependency, which left us puzzled at first when we started thinking about this problem. We moved all our simulation to the GPU during the development of Attila. One of the main features of Attila is that you can burn and raze everything. It has a magnitude more fire effects and particles than Rome 2 and that was the only way to unlock that amount of particles. With no way going back to CPU we started investigating other options.
One could be to copy the resources between the GPUs as soon as possible. Although the simulation step was at the beginning of the frame, the potential latency of the copy would have been unacceptable. Also, DirectX®11 just doesn’t have enough control over resources transform for this solution. Another option would be to partition our frames somewhat differently to AFR. This would have been a great undertaking. Months of potential R&D, fundamental changes to the pipeline and potentially still not enough control on DirectX®11.
So the only feasible options seemed to be generating the required data on both GPUs simultaneously. We decided to introduce an (N-1) frame latency in the particle simulation, where N = #GPUs. Then we submit N frames worth of simulation data to each GPU. So this is what we simulate over time:
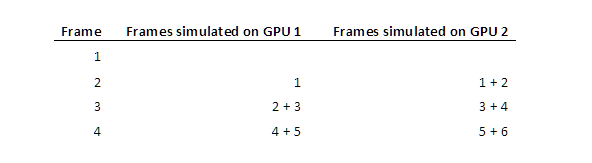
Using this setup, we managed to separate the two GPUs completely, but still keep the simulation data in sync. It does come with the additional cost of simulating two frames and the added one frame latency, but it’s still much better than having inter-frame dependency.
This is the rendering pipeline we shipped Warhammer with:
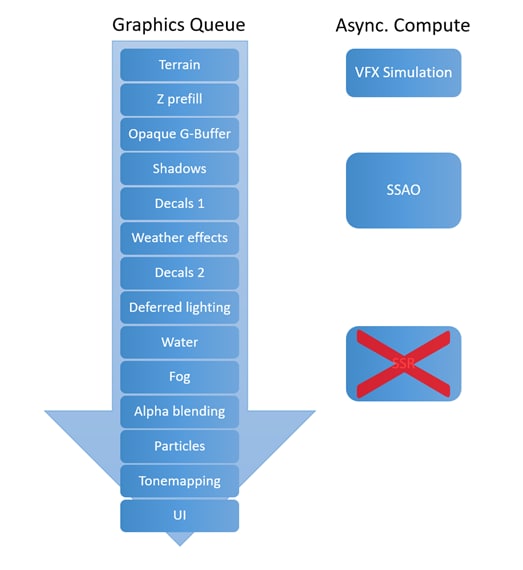
Warhammer Rendering Pipeline
This concludes our series about Total War: Warhammer. If you have any questions, please feel free to comment or get in touch with Tamas on Twitter.