
Porting Detroit Become Human from PlayStation® 4 to PC – Part 2
Part 2 of this joint post between Quantic Dream and AMD looks at non-uniform resource indexing on PC and for AMD cards specifically.

This is a three part series, written jointly by Ronan Marchalot, 3D engine director, and 3D engine senior developers Nicolas Vizerie and Jonathan Siret from Quantic Dream, along with Lou Kramer, who is a developer technology engineer from AMD.
The information contained in the blog represents the view of AMD or of the third-party authors as of the posting date. The blog post contains the author’s own opinions and may not represent AMD’s positions, strategies, or opinions. AMD and/or the third-party authors have no obligation to update any forward-looking content. GD-84
Hello everyone,
This blog series discusses the port of the game Detroit: Become Human from PlayStation® 4 to PC. It was released in three parts, and all three parts are now available with links at the end of Part 1.
Detroit: Become Human was released on PlayStation® 4 in May 2018. We started to work on the PC version in July 2018 and it was released in December 2019. It is an adventure game with three playable characters and many different story lines. It has very strong visuals and most of the technology has been developed internally.
The 3D engine has some nice features:

Detroit: Become Human
The 3D engine of the game was designed specifically for the PlayStation® 4 from the beginning, and we had no idea that we would eventually support other platforms. Consequently, the PC version was a great challenge for us.
We had already an OpenGL® version of our engine that we were using in our tools.
We didn’t feel comfortable releasing the game in OpenGL®:
Due to our extensive usage of bindless resources, it was not feasible to port the game to DirectX®11. There are not enough resource slots, and it would have been very difficult to reach a decent performance if we had to reorganize our shaders to use fewer resources.
The choice was between DirectX®12 and Vulkan®, which both provide a very similar feature set. Vulkan® will enable support for Linux and mobile phones later, and DirectX®12 will enable support for the Microsoft® Xbox. We know that we’ll have to support both APIs in the end, but for the port it was wiser to focus on only one API.
Vulkan® still supports Windows® 7 and Windows® 8. As we wanted to provide Detroit: Become Human to as many players as possible, this was a very strong argument over DirectX®12. However, the port took one year, and this argument is gone as Windows® 10 is now widely used!
OpenGL® and older versions of DirectX® provide a very simple model to drive GPUs. These APIs are easy to understand and are very suitable for learning purposes. They rely on the driver to do a lot of work which is hidden from the developer. Consequently, it can be very hard to optimize a full-featured 3D engine.
On the opposite side, the PlayStation® 4 API is very light and very close to the hardware.
Vulkan® is somewhere in the middle. There is still an abstraction because it runs on different GPUs, but we have much more control. For instance, we are responsible for handling memory or implementing a shader cache. As the driver has less work to do, we have more work to do! However, coming from the PlayStation®, we were more comfortable with controlling everything.
The CPU of the PlayStation® 4 is an AMD Jaguar with 8 cores. It is obviously slower than some recently-released PC hardware; but the PlayStation® 4 has some major advantages, such as very fast access to the hardware. We find the PlayStation® 4 graphics API to be much more efficient than all PC APIs. It is very direct and has very low overhead. This means we can push a lot of draw calls per frame. We knew that the high number of draw calls could be an issue with low-end PCs.
One other big advantage is that all the shaders can be compiled off-line on PlayStation® 4, meaning the loading of shaders is nearly instantaneous. On PC, the driver needs to compile shaders at load time: this cannot be an off-line process because of the wide configurations of GPUs and drivers that need to be supported.
During the development of Detroit: Become Human on PlayStation® 4, artists could design unique shader trees for all materials. This resulted in an insane number of vertex and pixel shaders, so we knew from the beginning of the port that this will be a huge problem.
As we knew with our OpenGL® engine, the compilation of shaders can take a long time on PC. During the production of the game, we generated a shader cache targeting the GPU model of our workstations. It was taking a whole night to generate a complete shader cache for Detroit: Become Human! This shader cache was provided to everyone each morning. But it didn’t prevent the game from stuttering because the driver still needed to convert that code into native GPU shader assembly.
Vulkan® turned out to be much better than OpenGL® to tackle this issue.
Firstly, Vulkan® doesn’t directly use a high-level shading language such as HLSL, but a standard intermediate shader language called SPIR-V. SPIR-V makes shader compilation faster and easier to optimize for the driver shader compiler. In fact, it is similar in terms of performance to the OpenGL® shader cache system.
In Vulkan®, the shaders must be associated to form a VkPipeline . A VkPipeline can be made with a vertex and a pixel shader for instance. It also contains some render state information (depth tests, stencil, blending, and so on), and the render target’s formats. This information is important for the driver to ensure it has everything it needs to compile shaders in the most efficient way possible.
In OpenGL®, the shader compilation does not know the context of shader usage. The driver still needs to wait for a draw call to generate the GPU binary, and that’s why the first draw call with a new shader can take a long time to execute on the CPU.
With Vulkan®, VkPipeline provides the context of usage, so the driver has all the information needed to generate a GPU binary, and the first draw call has no overhead. We can also update a VkPipelineCache when creating a VkPipeline .
Initially, we tried to create the VkPipelines the first time we needed them. This caused stuttering much like the OpenGL® driver strategy. The VkPipelineCache is then up-to-date, and the stuttering will be gone for the next draw call.
Then we anticipated the creation of the VkPipelines during loading, but it was so slow when the VkPipelineCache was not up-to-date that our background loading strategy was compromised.
In the end, we decided to generate all the VkPipeline during the first launch of the game. This completely eradicated the stuttering issue, but we were now facing a new problem: the generation of the VkPipelineCache was taking a very long time.
Detroit: Become Human has around 99,500 VkPipelines ! The game is using a forward rendering approach, so material shaders contain all the lighting code. Consequently, each shader can take a long time to compile.
We found a few ideas to optimize this process:
VkPipeline creation.Finally, a big optimization was suggested by Jeff Bolz from NVIDIA and has been very effective in our case.
A lot of VkPipelines are very similar. For instance, some VkPipelines can share the same vertex and pixel shaders, differing only by some render states such as stencil parameters. In this case, the driver can consider internally that it is the same pipeline. But if we create them at the same time, one of the threads will just wait until the other one finishes the task. By nature, our process was sending all the similar VkPipelines at the same time. As a solution, we just re-sorted VkPipelines . The “clones” were put at the end, and their creation ended up much faster.
Performance of the VkPipelines creation is very variable. In particular it depends greatly on the number of hardware threads available. With an AMD Ryzen™ Threadripper™ with 64 hardware threads, it can take only two minutes. But on a low-end PC, it can unfortunately be more than 20 minutes.
The last case is still too long for us. Unfortunately, the only way to improve this time further is to decrease the number of shaders. It requires that we change the way we create materials to share them as much as possible. It was not feasible on Detroit: Become Human because artists would have to rework all the materials. We plan to do proper material instancing in our next game, but it is too late for Detroit: Become Human.
To optimize the speed of draw calls on PC, we use descriptor indexing with the extension VK_EXT_descriptor_indexing . The principle is simple: we can create a descriptor set containing all the buffers and textures used in the frame. Then we can access the buffers and textures with indices. The main advantage is that all resources are bound only once per frame even if they are used by many draw calls. This is very similar to bindless resources in OpenGL®.
We create arrays of resources for all the types of resources we use:
We have just a main buffer which changes between draw calls (implemented as a ring buffer), and which contains a descriptor index referencing the right material buffer and the right matrices. Each material buffer contains indices of used textures.
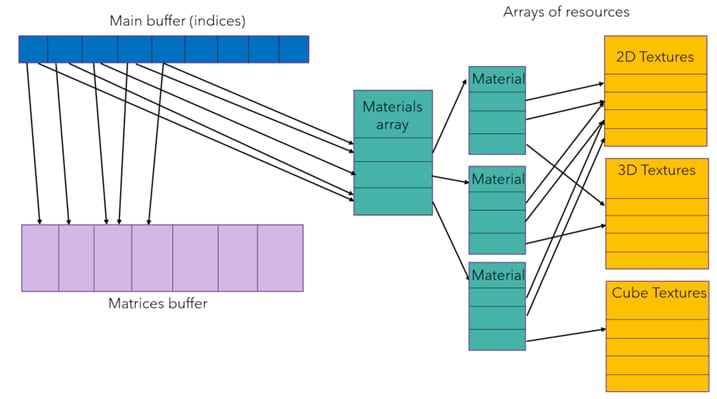
With this strategy, we can have a low number of descriptor sets shared by all our draw calls which contains all the information needed to draw the frame.
Even with a low number, the update of descriptor sets was still a bottleneck. Updating a descriptor set can be very expensive if it contains many resources. In Detroit: Become Human, we can have more than 4,000 textures in a frame for instance.
We implemented incremental updates of descriptor sets, by tracking which resources become visible for a given frame, and which resources exit visibility. This also limits the size of the descriptor arrays, as they only need to have the capacity to handle visible resources at a given time. The tracking of visibility is lightweight as we do not use an expensive intersection algorithm with O(n.log(n)) . Rather we use two lists, one for the current frame and one for the previous frame. Moving still-visible resources from one list to the other and examining the remaining resources in the first list helps to identify which resource enters and leaves the frustum.
The resulting deltas of this computation are kept for four frames – we use triple buffering, and computation of motion vectors of skinned objects requires one more frame to be available. A descriptor set should remain immutable for at least four frames before it becomes available again, because the GPU may still be using it. As a result, we apply the deltas by bundles of four frames.
In the end, this optimization reduced the descriptor set update time by one or two orders of magnitude.
The use of descriptor indexing allows us batching many primitives in one draw call with vkCmdDrawIndexedIndirect . We use gl_InstanceID to access the right indices in the main buffer. Primitives can be batched if they share the same descriptor set, the same shader pipeline, and the same vertex buffer. This is very efficient especially during depth and shadow passes. The total number of draw calls is reduced by 60%.
This concludes Part 1 of our series. Why not continue reading?
In Part 2 Lou Kramer, developer technology engineer at AMD, discusses non-uniform resource indexing on PC and on AMD cards specifically.
In Part 3, you’ll find Ronan Marchalot discussing shader scalarization, Nicolas Vizerie discussing multithreaded render lists, pipeline barrier handling, and async compute shaders, and Jonathan Siret discussing memory management.






















