Porting Detroit Become Human from PlayStation® 4 to PC – Part 3
Originally posted:
Last updated:
Lou Kramer
Ronan Marchalot
Nicolas Vizerie
Jonathan Siret
Part 3 written by Ronan Marchalot, Nicolas Vizerie, and Jonathan Siret.
This is a three part series, written jointly by Ronan Marchalot, 3D engine director, and 3D engine senior developers Nicolas Vizerie and Jonathan Siret from Quantic Dream, along with Lou Kramer, who is a developer technology engineer for AMD.
The information contained in the blog represents the view of AMD or of the third-party authors as of the posting date. The blog post contains the author’s own opinions and may not represent AMD’s positions, strategies, or opinions. AMD and/or the third-party authors have no obligation to update any forward-looking content. GD-84
Introduction
Hello, and welcome to Part 3 of our series on porting Detroit: Become Human from PS4 to PC. In Part 1, Ronan Marchalot from Quantic Dream explained why they decided to use Vulkan® and talked about shader pipelines and descriptors. In Part 2, Lou Kramer from AMD discussed non-uniform resource indexing on PC and on AMD cards specifically.
Here in Part 3 Ronan Marchalot discusses shader scalarization, Nicolas Vizerie discusses multithreaded render lists, pipeline barrier handling, and async compute shaders, and Jonathan Siret discusses memory management.
Shader scalarization
As we saw in the previous chapter, the use of descriptor indexing everywhere can lead to very poor shader performance if we use too many non-uniform registers.
This is not a Vulkan® specific issue, and we had already implemented these optimizations in the PlayStation® 4 version. But it is worth mentioning a few tips here. Most vector register instructions come from the input of the vertex shader or from the input of the pixel shader. In our shaders, we forced scalarization in two important parts of our shaders.
Scalarization of gl_InstanceID
There used to be a paragraph about gl_InstanceID scalarization here. However, it turns out this optimization was not strictly spec compliant so we’ve decided to remove it altogether.
Basically, all lights are stored in cluster cells, and each pixel shader must find the cluster index before performing lighting. A naive implementation is not very performant because neighbor pixels can access different lights. Consequently, the shader uses a lot of vector registers and has very poor performance.
// Compute lighting with the uLightIndexWarpMax light
}
}
The code is not very complicated. It can seem counter-intuitive that it improves performance because we add a branch, but the whole shader is much faster due do the decrease of vector register usage.
Multithreaded render lists
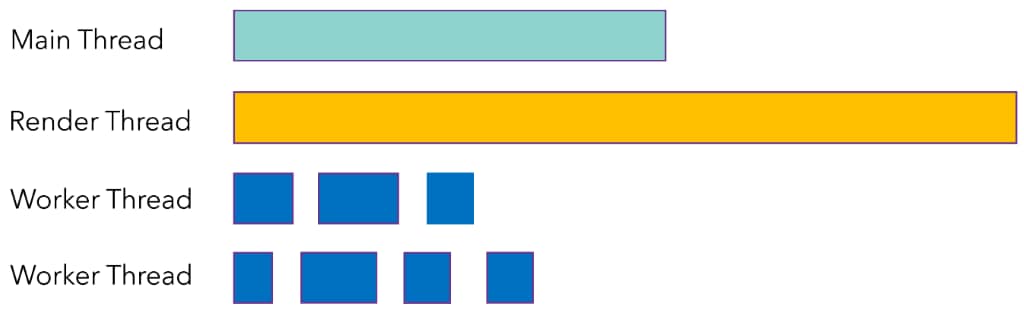
On PlayStation® 4, the draw calls are so fast that we use only one thread for them. This is our render thread. We have also a main thread and a few worker threads which perform various jobs.
On PC, draw calls are much slower, and we usually wait for the render thread to complete. All the other tasks (animation, visibility, physics) are faster, so we have a lot of CPU cores which are not busy. Consequently, the threads are not well balanced. The render thread is clearly the bottleneck of the engine.
It was very natural to think about moving work from the render thread to the worker threads to optimize the framerate. With Vulkan®, we can fill multiple command buffers in different threads. We decided to use our job system to parallelize the work of the render thread.
Quantic Dream’s engine uses what we call render lists to display objects. A render list regroups draw calls that share the same render target.
We have different render lists:
Depth pass.
Main pass.
Skin shader pass.
Refraction masks.
Transparent object.
Shadows.
and so on.
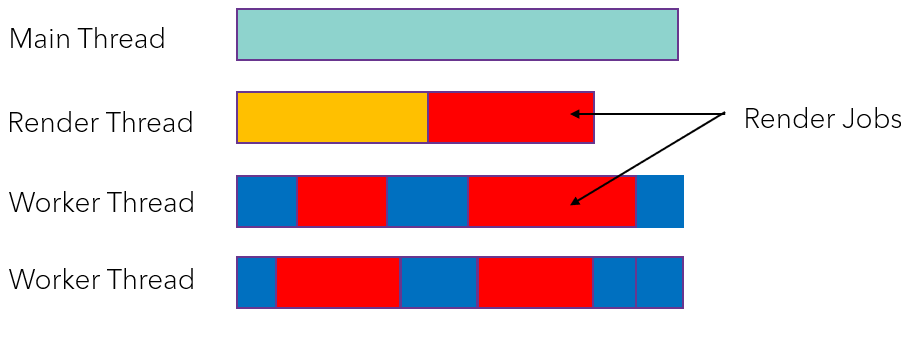
Each render list is handled by one or more jobs, depending on the number of draw calls.
Each job will create a secondary command buffer. In those there are no pipeline barriers, no viewport settings, and no render target settings. They only update and bind descriptors, vertex and index buffers, and issue drawing commands.
While these command buffers may be recorded in any order, they are always re-ordered to keep the same ordering as the single-threaded pass, before calling vkCmdExecuteCommands . This is especially important for transparent objects, whose sorting needs to be deterministic. We also created one command buffer pool per thread of our thread pool, which is best for performance and simplifies code. This is because there is no concurrent access for a given command buffer pool when a new command buffer is needed. Moreover, we recycle them when possible.
We used a feature that allows us to bind a descriptor set before it has been completely specified, using VK_DESCRIPTOR_BINDING_UPDATE_AFTER_BIND_BIT_EXT . When a new descriptor is allocated or updated incrementally, it becomes available for binding to other render threads immediately, instead of having to wait for it to be updated. Indeed, this can be blocking for a “long” time when a resource array must be updated entirely, or almost entirely during camera switches. The thread that first acquired it has the responsibility to populate it. This proved useful to reduce spikes, which was a major challenge during the port, because there are so many places where they may arise.
This optimization was very effective. It drastically reduced the waiting for the render thread.
Pipeline barrier handling
As reported by other developers, this has been a difficult part to implement. We opted for automatic management of resources. In our case, the complexity is linked to the conjunction of several features (asynchronous compute shaders, multi-threaded rendering, “bindless” resources, support of resource aliasing).
Moreover, during the development of Detroit: Become Human, aside from the errors that are detected by the validation layer, there was no framework that allows us to check the code correctness for those. In some cases, only artifacts of rendering would hint at a problem, and the probability of their occurrence proved to be highly variable depending on the GPU and the drivers used. Validation Layer support has recently been added for Vulkan® Synchronization that supports single command buffers; this should be really helpful in the future.
We used the notion of “barrier context”. A barrier context will compute all barriers and layout changes and will issue a single call. Each resource maintains a “barrier resource state”, which helps to detect memory hazards, aliases transitions, and queue family transitions.
Async compute rendering
Due to time constraints, this feature is less advanced than its PlayStation® 4 counterpart. The populating of the light cluster and the HBAO compute shader are currently done asynchronously. On the PlayStation® 4, post-processing passes at the end of the frame where also overlapped asynchronously with the next frame. This is also possible with the Vulkan® renderer but has not been implemented yet.
Globally, the gains were modest but not negligible either, given that only a small part has been parallelized for now. The implementation is quite rigorous, as it checks for each resource to see whether it is used simultaneously by several queue families by mistake (non-retail builds only). This allowed us to use the feature with confidence, and as we found that a lot of tweaking was needed to make the most of it, this was a welcome safety net during the development.
We used exclusive resource sharing, but this made the implementation more complex. This is due to the need for “queue transfer ownership barriers”, which are needed to transition one resource between transfer, graphics, or compute queues. Because we based the renderer on the previous code, we had no way to deduce the resources that would be used when starting an async part. This meant that sometimes, some back and forth “patching” was required to be able to insert those barriers. This is also a hint that a render graph would simplify this part a lot. Clearly Vulkan® has been designed for this kind of engine architecture.
Like other engines, we chose the more incremental and safe approach to transition to Vulkan®. This worked well enough for us during the Detroit: Become Human PC port, and doing otherwise would not have fit into our time budget due to the quantity of higher-level rendering code that already existed. This also meant that there is still room for improvement.
The only issue we’ve met is the defragmentation of GPU memory. The strategy suggested in the VMA documentation involved waiting for all command buffers to finish moving allocations before updating them to their new position in memory. This is very safe but caused an FPS spike. We started modifying the code to implement an asynchronous defragmentation. But while we started to implement this, VMA was being updated with a similar solution!
We finally reverted our code and upgraded VMA to avoid issues with future upgrades. We need to carefully select allocations that are not currently being deleted or transferred to GPU memory, and send them to VMA for defragmentation. And instead of waiting for the queue to finish, we update the allocations to their new position after two frames. Previous memory is then deleted after the update, and a few frames later.
This solution of course entails that allocations during defragmentation are present twice in memory. But since it implies only a small amount of allocations, the memory spike is barely noticeable. And even if the number of allocations sent to VMA represent only a small percentage of total allocations, the regular and frequent defragmentation covers all of them in a limited number of frames.
Other modifications were needed to ensure that all allocations were correctly copied in memory. In VMA initially, only buffer copy commands were issued. This caused problems for images that are tiled (most of our textures), with multiple mipmap levels and/or faces (cube maps). The creation of these command buffers was removed from VMA and implemented to guarantee that buffer and image allocations are copied with respective copy commands.
The defragmentation is enabled in our patch 3.0. It’s executed every two frames and decreases the GPU memory usage a lot.
For most of our render targets (buffers, shadow maps, etc) which depend on resolution and graphic options, we decided to not put them in memory pools. They change only if the player changes the resolution or the graphic options, and we don’t want to move big quantities of memory in the defragmentation.
When a player changes the resolution, we destroy all our render targets, and wait for all command buffer completion. This way, we can create the new render targets when the memory is released, and we don’t allocate over the GPU budget. If we don’t do that, we have at some point render targets allocated for two different resolutions. This is not a big deal because the driver can use virtual memory if it doesn’t have physical memory, but it slows down the game during a few frames and it is noticeable.
The implementation of defragmentation also pushed us to closely analyze GPU memory usage. VMA can dump all the allocations of a VmaAllocator in a file. The dump results can then be summed up in an image thanks to VmaDumpVis , allowing us to analyze the pools and dedicated allocations used by VMA. This dump was also useful for tracking memory leaks that were notably present when exiting a level in Detroit: Become Human and returning to the main menu, or when going to the next level (each allocation can be tagged with a name to be easily identifiable).
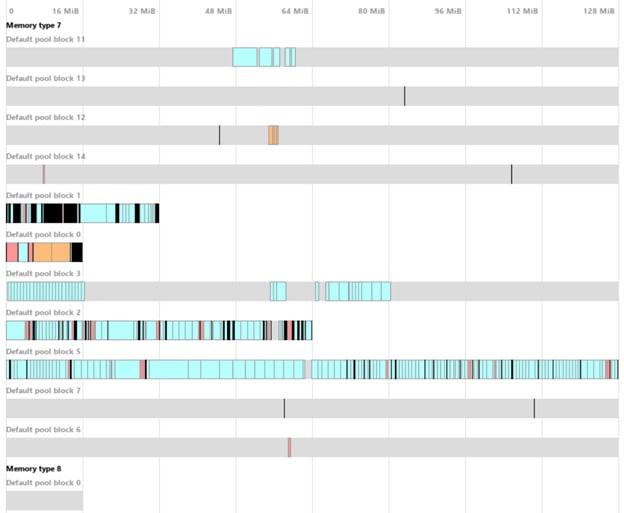
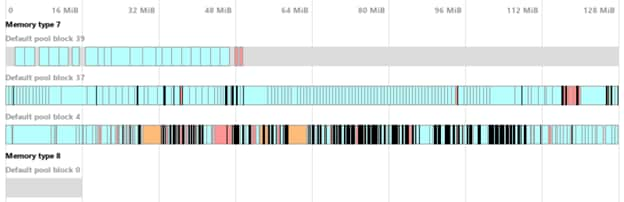
The two images below show the difference between active defragmentation or not. These results were created after returning to the Main Menu from one of the missions. The number of allocations is the same (~950), but total allocated memory is higher without defragmentation (Figure 1). More importantly, we can observe a few allocations that are scattered between six blocks of 128 MB. Allocated blocks are not lost, but allocations in the middle of a block can interfere with new allocations. For example, an allocation of 96 MB would need a new block since it cannot fit in any of the six blocks.
Of course, going back to menu does not necessarily represent an in-game situation, but memory gains have also been observed in all the levels.
Figure 1 - without defragmentation
Figure 2 - with defragmentation
GPU Memory Aliasing
Another GPU memory optimization adapted from the PlayStation® 4 is the use of GPU memory aliasing for the dedicated allocations of the Engine Render Targets. Memory aliasing allows the binding of a single GPU memory allocation ( VmaAllocation ) to different textures or buffers. Some of our Render Target textures share the same parameters passed to VkImageCreateInfo (notably dimensions and mip levels). And so, follow the conditions defined by Vulkan® to be aliased. The dedicated allocation memory aliasing feature must also be supported and enabled.
To reuse these allocations, the creation and binding functions of VMA had to be extracted and redefined to allow an allocation to be passed on to these functions and applied to new textures. If the binding to an existing allocation fails, we fallback and create a new allocation to bind.
GPU memory aliasing saves up to 164 MB (going from 1.60 GB to 1.44 GB in Full HD).
Default and custom memory pools
Another important functionality from VMA is the usage of custom pools. VMA creates a default memory pool for each memory type that needs an allocation. However, the default pools can allocate blocks of memory of increasing size at any point in time. This was not adapted for a specific memory type we use for uploading. For that memory type, at the start of some missions, its default pool would allocate a multitude of memory blocks before stabilizing and so generate a lot of visible stutter. To alleviate this problem, we started by monitoring usage of that memory type and determined a sufficient, but not excessive amount of memory that needed to be pre-allocated. We therefore created a custom pool with a base amount of pre-allocated blocks of memory, that would not be freed until game exit.
Some lessons learned while porting to Vulkan®
Using the validation layer is a must from day one. It is very easy for things to go wrong without noticing it in Vulkan®. We are glad we used it from the start.
Some features (barrier handling being the most prominent) clearly benefit from the prior knowledge of when and in which queue a resource will be used.
The descriptor layout system of Vulkan® is quite flexible and can accommodate a lot of cases. Choosing the right organization depending on one’s needs is crucial, as it may have big implications on the code performance and complexity.
We found that using “dynamic buffers” helped to reduce the number of descriptor updates when using ring buffers. We tried to use it as much as possible while staying under the hardware limits – we choose AMD GPUs as the baseline for this.
Conclusion
The port of Detroit: Become Human to the PC was a great experience. The Vulkan® version of our engine is much faster than the OpenGL® version.
We still have a lot to do to improve the engine on PC. For instance, we want to explore the render graph approach. This will help us to improve barrier management, asynchronous shaders, and memory aliasing.
Lou is part of AMD's European Game Engineering Team. She is focused on helping game developers get the most out of Radeon™ GPUs using Vulkan® and DirectX®12 technologies.