AMD FidelityFX™ Variable Shading
AMD FidelityFX Variable Shading drives Variable Rate Shading into your game.
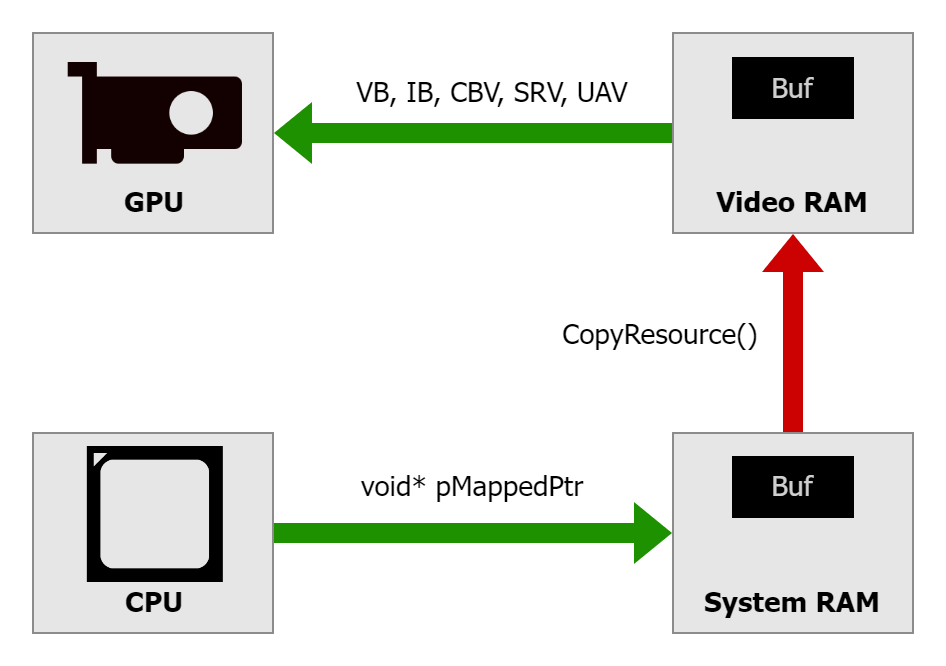
When developing a graphics application using Direct3D 12 for a PC with a discrete graphics card, we work with 2 types of memory: system RAM located on the motherboard and video RAM (VRAM) located on the graphics card. The main processor (CPU) has fast and direct access to the system RAM, while the graphics processor (GPU) has fast and direct access to the VRAM. Communication between them needs to go through the PCI Express® bus. In graphics applications, the typical direction is to transfer data from the CPU to the GPU. The amount of data can vary, from updating small constant buffers every frame with new positions of objects on the scene to streaming large textures and meshes loaded from disk.
In the Direct3D 12 API, there are multiple ways to perform such a data upload. A typical solution is to allocate one “staging” copy of the buffer in D3D12_HEAP_TYPE_UPLOAD memory (which is typically located in system RAM), Map() it to obtain a CPU pointer, write the data, have another buffer in D3D12_HEAP_TYPE_DEFAULT (which is VRAM), and issue a copy operation to it using a function like CopyResource() before the second buffer is used by the GPU - bound to a shader slot as a vertex buffer, constant buffer, etc.:
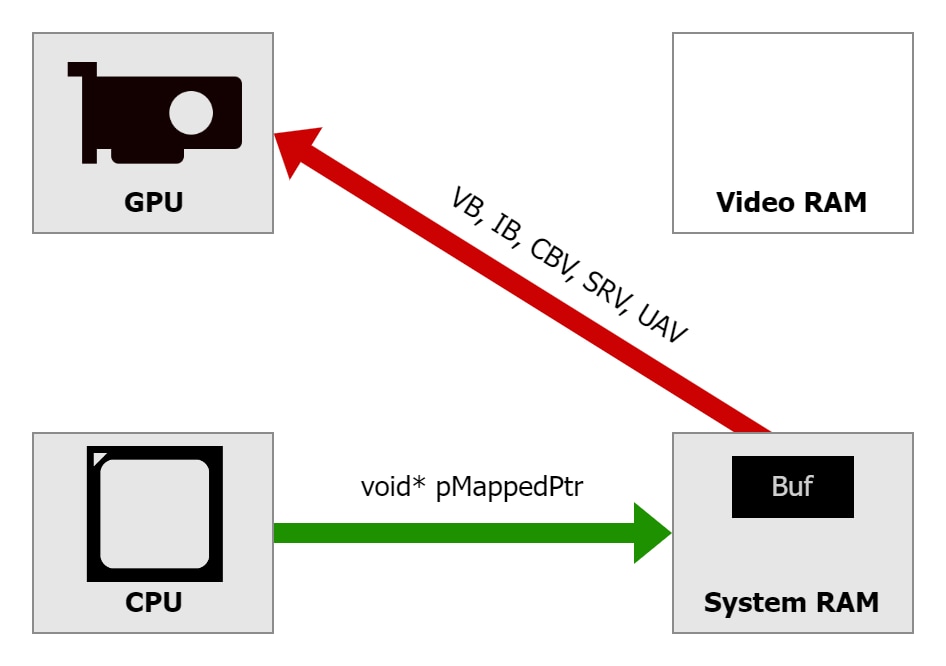
Another option is to reach out to the original buffer in the UPLOAD heap directly from shaders. It is possible to obtain an address of such buffer, create a descriptor, and access it from shader code just like any other resource bound to the graphics pipeline. This approach avoids another copy of the data, but the shader can run slower, as reading data directly from the buffer located in the UPLOAD heap requires reaching out to system RAM through PCIe®:
A copy operation between two buffers can also be performed in multiple ways. Copy commands like CopyResource() or CopyBufferRegion() can be executed on a copy, graphics, or compute queue, which have different characteristics. A copy can also be performed by writing a compute shader that will read the source buffer and write the destination buffer number-by-number.
There is yet another possibility: to have a memory pool located in video RAM but directly accessible for mapping to the CPU. This feature has existed for a long time, and it was known as Base Address Register (BAR). This special area of memory typically had only 256 MB. Modern PCs offer a possibility to extend it to the entire VRAM, making it all directly accessible to the CPU. This is called Resizable BAR (ReBAR) and needs to be explicitly enabled in UEFI/BIOS settings of the motherboard. Until recently, access to this memory wasn’t accessible to developers using Direct3D 12, only in Vulkan® (a memory type with VK_MEMORY_PROPERTY_DEVICE_LOCAL_BIT and VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT set). This is why in June 2021 we published an article “How to get the most out of Smart Access Memory (SAM)”, which explains how our graphics driver could make use of that memory automatically by placing some resources allocated in UPLOAD heap in VRAM. See also: AMD Smart Access Memory.
In March 2023, with Agility SDK version 1.710.0-preview, Microsoft extended the D3D12 API with another type of memory heap: D3D12_HEAP_TYPE_GPU_UPLOAD. With this flag, ReBAR memory becomes accessible for explicit use for those who develop with D3D12. To read more about it, see the announcement on DirectX Developer Blog and the official specification. The AMD driver supporting it was released in June 2023 as AMD Software: Adrenalin Edition 23.10.01.14 for DirectX®12 Agility SDK. Since the Agility SDK 1.613.0 released on March 11th, 2024, the feature became available for retail use and no longer needs Developer Mode enabled in Windows.
To use this new type of memory effectively, we need to understand its characteristics. It is typically located in VRAM, although it can fall back to system RAM in some cases (e.g. when debugging under PIX). Buffers created in this memory can be mapped and accessed directly from the CPU. Of course, they can also be used by the GPU, e.g. as a vertex buffer or an index buffer. The memory is uncached and write-combined from the CPU perspective, just like the UPLOAD heap, but this time, it is the CPU access that needs to go through PCIe bus:
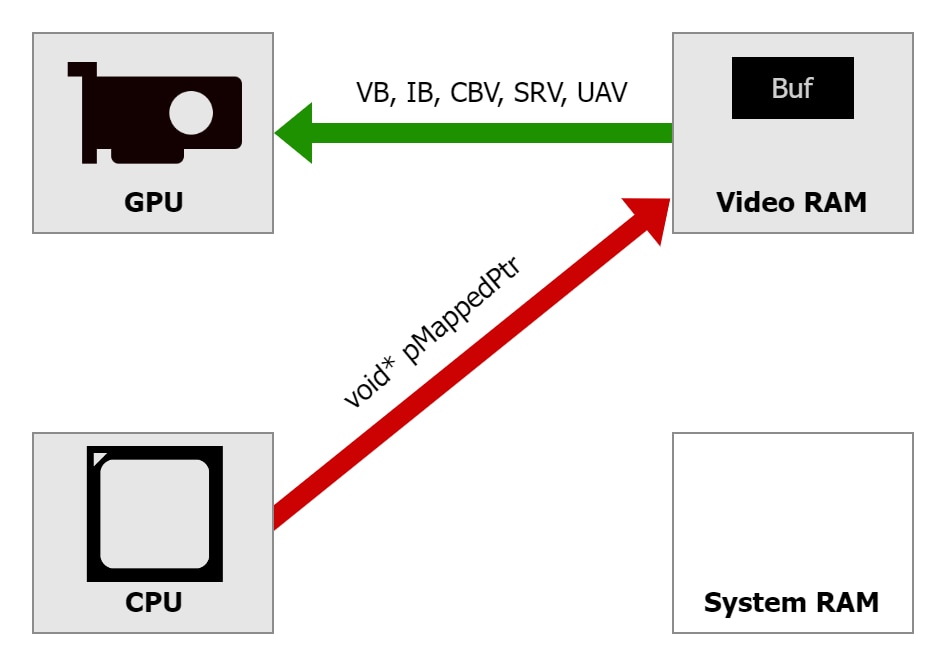
D3D12_HEAP_TYPE_GPU_UPLOAD from the GPU (e.g. as buffers bound to shaders) is as fast as when using DEFAULT heaps since they are also located in VRAM. This gives an opportunity to write from the CPU to the same buffer as read by the GPU, without a need for additional copy of the buffer to occupy memory and additional copy operation that would take extra time and effort to execute.D3D12_HEAP_TYPE_GPU_UPLOAD performed through a mapped pointer can be slower than writing to system RAM because they need to go through PCIe bus, but with modern PCIe Gen 4 and later, the writes can be same order of magnitude as to system RAM when done correctly (see next paragraphs).D3D12_HEAP_TYPE_GPU_UPLOAD is write-combined, so it is very important to use a good access pattern (good locality) when writing the data. A memcpy() from a normal system memory is recommended. Sequential write number-by-number, forward or backward, also performs well. Random accesses or writes with a large stride do not. This is the same recommendation as for the UPLOAD heap, but with GPU_UPLOAD the difference in performance between good and bad access patterns is even larger. For example, writes to GPU_UPLOAD with stride between individual values exceeding 32 DWORDs may be 2 times slower than writes to UPLOAD.D3D12_HEAP_TYPE_GPU_UPLOAD is uncached, so it is very important to never read from it, only write. There is no “write-only memory” – reads from such pointer are guaranteed to work correctly, but they are extremely slow. It is easy to accidentally introduce some reads, e.g. by doing pMappedPtr[i] += v;. This is the same recommendation as for the UPLOAD heap, but with GPU_UPLOAD the performance penalty of memory reads is even larger.D3D12_HEAP_TYPE_GPU_UPLOAD is available for mapping directly, so copying data can often be avoided, but when a copy is needed between two buffers located in VRAM, prefer graphics or compute queue for doing them. The copy queue is designed to reach maximum throughout when copying data over PCIe. For GPU-GPU copies it may work slower. Writing a custom shader to perform such copies may be a good idea, as it can also reach peak performance, while it can run in parallel with other such copies, other draw calls, or compute dispatches, as it doesn’t issue an implicit barrier before and after each command, like copy commands do. Copying using a shader is especially beneficial for small amounts of data.D3D12_HEAP_TYPE_GPU_UPLOAD is in VRAM, so be mindful of the size of resources created in it. They will add up to the VRAM usage together with resources in the DEFAULT heap. When they exceed available budget (as queried through IDXGIAdapter3::QueryVideoMemoryInfo function with DXGI_MEMORY_SEGMENT_GROUP_LOCAL), new allocations may fail or the application may experience performance degradation, as some allocations get silently migrated to system RAM in the background, without our explicit control or a way to know about it.Map()/Unmap() many times.Please keep in mind that the feature may not be available on all platforms. Enabling ReBAR requires hardware and software support in many places, including supporting motherboard with updated BIOS, supporting graphics card with updated graphics driver, and explicit enablement in the UEFI/BIOS settings. Support needs to be checked by querying D3D12_FEATURE_DATA_D3D12_OPTIONS16::GPUUploadHeapSupported. When this flag is FALSE, the application needs to fall back to some other method of data uploading.
Writing from the CPU code to the same buffer as read by shaders executed on the GPU imposes risk of race condition bugs. A care should be taken to ensure proper synchronization. GPU works asynchronously to the CPU, typically rendering frames enqueued some time ago, while CPU is one or more frames ahead, calculating logic and recording graphics commands for future frames. While no explicit cache flush, invalidate, or other type of barrier is needed to make the data written by the CPU available to the GPU, you need to make sure CPU doesn’t overwrite data that can be still in use by the GPU. Write the data before a command list is queued for execution and wait for a fence to make sure the execution finished. Double/triple-buffering such data or using a ring buffer can be a good solution.
This article discussed only buffers, but unlike in D3D12_HEAP_TYPE_UPLOAD, the GPU_UPLOAD heap also allows creating textures in D3D12_TEXTURE_LAYOUT_UNKNOWN. With them, ID3D12Resource::WriteToSubresource function can be used to upload data form system memory directly to such texture, sparing CPU cycles to swizzle the pixels. However, this may not be the most performant method of texture uploading.
D3D12 Memory Allocator library provides support for GPU Upload Heaps in the latest version you can pick from the “master” branch.
Using the new D3D12_HEAP_TYPE_GPU_UPLOAD, on systems where it is available can be a good alternative to other ways of uploading data from the CPU to the GPU. It can reach better performance when implemented correctly. A general way to think about it is a shift in place where the data crosses PCIe bus. With GPU_UPLOAD heap, it happens when the CPU code is writing to a mapped pointer, as opposed to the copy operation, or GPU shader code reaching out directly to system RAM – as shown on the images above. Actual performance may vary depending on the specific project, so we recommend measuring on a variety of hardware/software configurations and choosing the solution that works best for you.
©2023 Advanced Micro Devices, Inc. All rights reserved. AMD, the AMD Arrow logo, Adrenalin Edition, Radeon, Ryzen, and combinations thereof are trademarks of Advanced Micro Devices, Inc. Microsoft is a registered trademark of Microsoft Corporation in the US and/or other countries. PCIe and PCI Express are registered trademarks of PCI-SIG Corporation. Vulkan and the Vulkan logo are registered trademarks of the Khronos Group Inc. Other product names used herein are for identification purposes and may be trademarks of their respective owners.