HIP Threads: GPU power for teams without GPU experts
HIP Threads lets C++ teams eliminate CPU hotspots by running familiar multithreaded code on AMD GPUs, no kernel rewrites or GPU expertise required, delivering real speedups in days.
Over the past year, AMD with close partnership with OSV, OEM and ISV partners been optimizing our software and hardware stack to enable efficient acceleration of latest and greatest AI model inference on AMD Ryzen™ AI and Radeon™ GPUs. Continuing that journey, AMD has taken a holistic approach optimizing AI workload stack starting from AI application going all the way down to the silicon to optimize running on AMD integrated and discrete GPUs. This required taking new initiatives and enhancing existing workflows including but not limited to generating AMD optimized models, building efficient ML libraries to optimally that implements the models, building efficient drivers and compilers that generates optimized hardware commands and enhancing the GPU hardware with ML accelerators that execute them fast and efficiently.
Using the optimized generative AI workflow described below, we were able to achieve up to 4.3x inference speedup and up to 2x memory reduction running the latest and greatest image generation models on AMD Radeon™ GPUs.
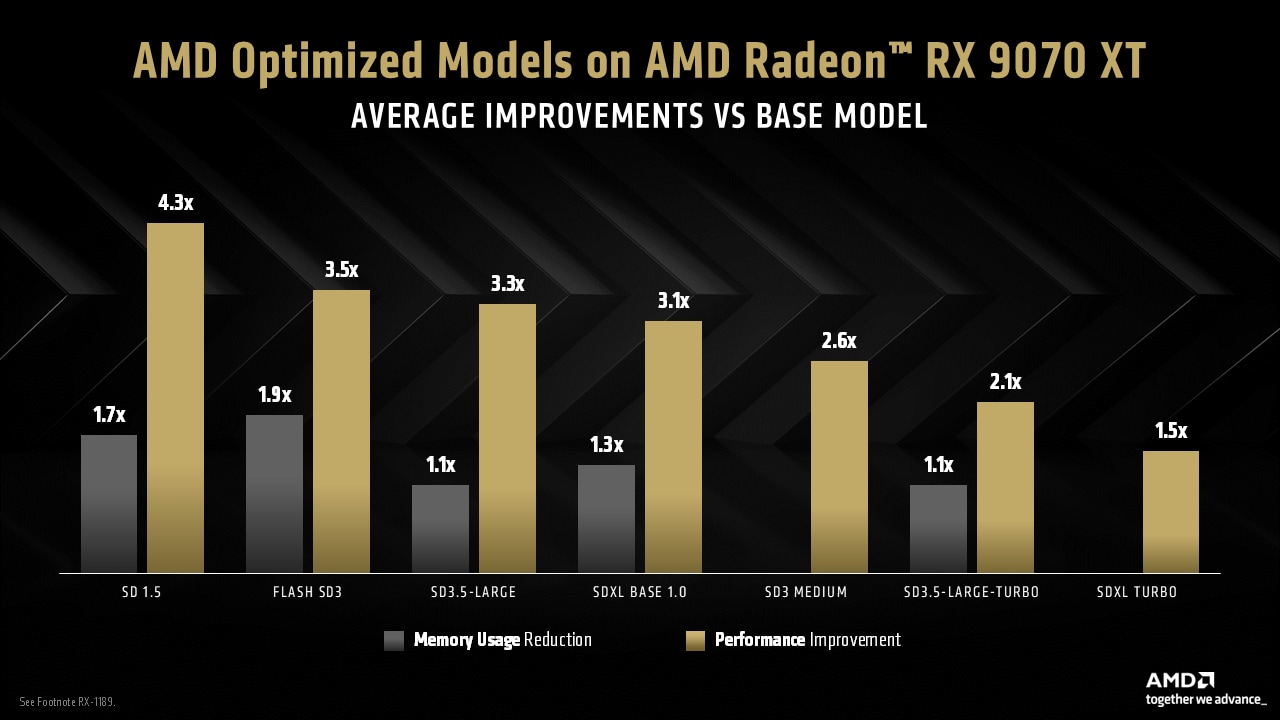 Fig 1: AMD Radeon™ RX 9070 XT performance and memory utilization improvements vs. base model. SD = Stable Diffusion. Results subject to change. See footnote 1
Fig 1: AMD Radeon™ RX 9070 XT performance and memory utilization improvements vs. base model. SD = Stable Diffusion. Results subject to change. See footnote 1
 Fig 2: AMD Ryzen™ AI performance and memory utilization improvements vs. base model. SD = Stable Diffusion. Results subject to change. See footnote 2 3
Fig 2: AMD Ryzen™ AI performance and memory utilization improvements vs. base model. SD = Stable Diffusion. Results subject to change. See footnote 2 3
In this article will touch on all these building blocks that makes up the AMD software and hardware stack to run today’s latest and greatest generative AI workloads on AMD Radeon™ and AMD Ryzen™ AI platforms. This is a continuous journey, and we will continue to evolve our Software (SW) and Hardware (HW) stack which is designed to be best in class to service today’s AI needs.
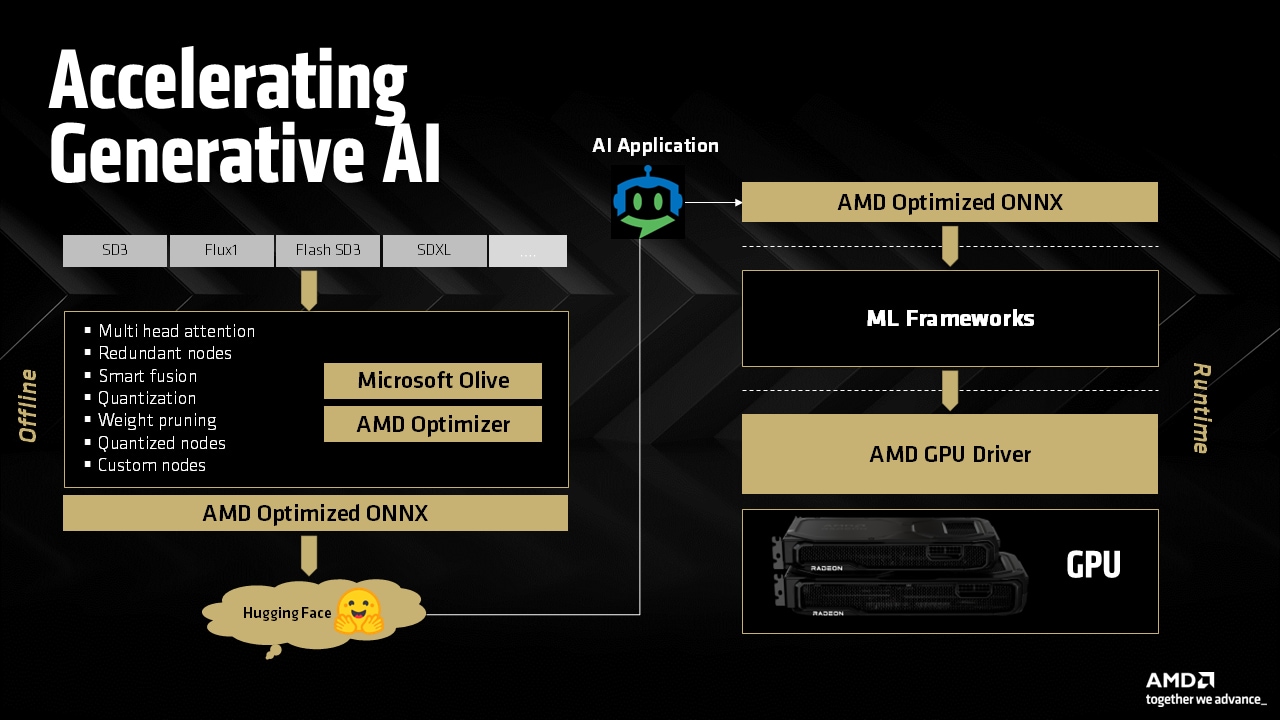 Fig 3: AMD Generative AI workflow
Fig 3: AMD Generative AI workflow
With the launch of AMD Radeon™ RX 9000 series graphics, we are glad to introduce AMD GPU optimized model repository and space in Hugging Face (HF), where we will host and link highly optimized generative AI models that can run efficiently on AMD GPUs. The initial set of models will be ONNX based converted from PyTorch or other sources, optimized via Microsoft® Olive and AMD Optimizer toolchains for efficient execution on the AMD hardware. These models are available on Hugging Face and integrated with Amuse application for easy usage and deployment.
These models are state of the art image generator models from Stability AI, Black Forrest Labs, and others optimized and highly tuned for AMD Radeon™ GPUs.
Below sections will give some of the insights into the hardware and software that makes the performance upside possible running on AMD GPUs.
To accelerate generative AI workloads on AMD hardware and to make sure the model is as optimal as possible for the underlying software blocks, we have developed AMD’s own offline tool chains that adds on top of Microsoft® Olive toolchains to prepare optimized ONNX models for execution on AMD Radeon™ GPUs
 Fig 4: AMD Model Optimizer building blocks
Fig 4: AMD Model Optimizer building blocks
Some of the custom optimizations includes optimizing flash attention nodes for various model architecture including but not limited to Unet, DiT Transformers and others. This allows the AMD Radeon™ GPU to take advantage of its full AI compute power without being bottlenecked by trips to external memory.
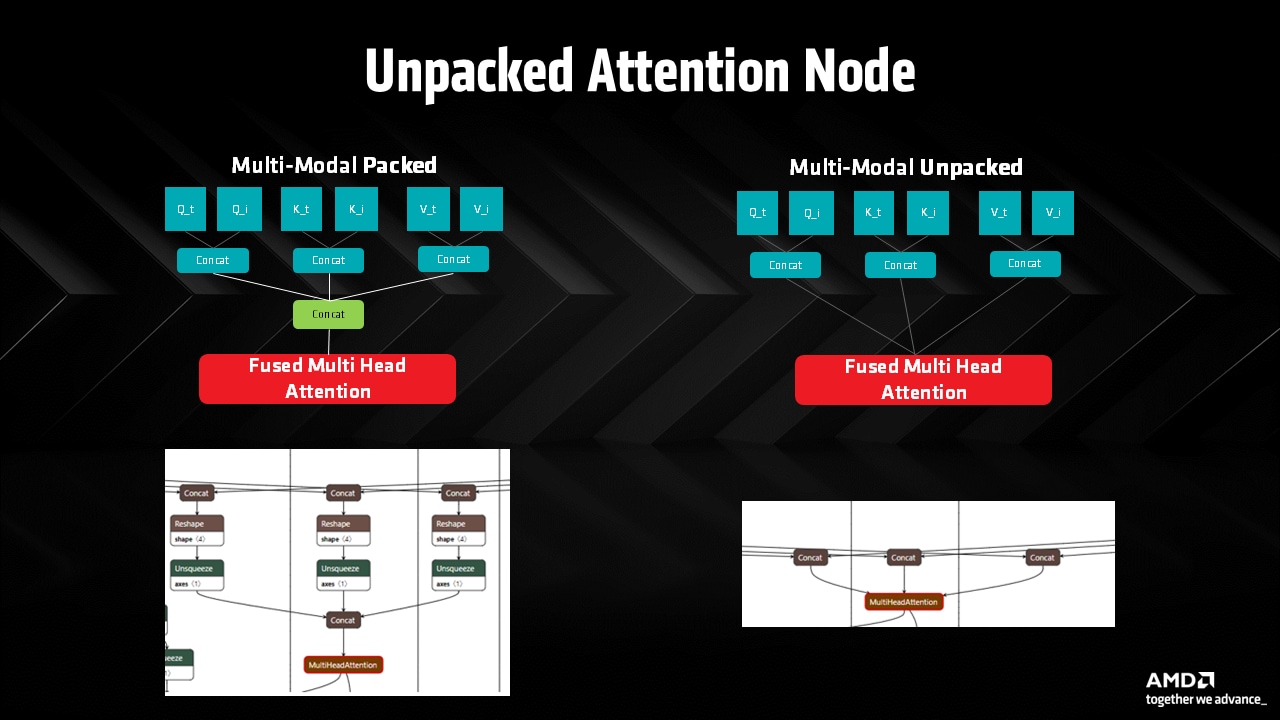
Attention blocks are the backbone of modern transformer architectures that is seen in the latest and greatest generative AI models. Here at AMD, especially with the introduction of the AMD Radeon™ RX 9000 series GPUs, we optimize running these building blocks efficiently on the underlying AMD GPU hardware. These involves optimizing the source models significantly with target hardware in mind, optimizing the ML kernels libraries, device drivers etc. that will engage the latest and greatest AMD Matrix Multiply Accumulate (MMA) cores to provide throughput and efficient memory access for the full workload.
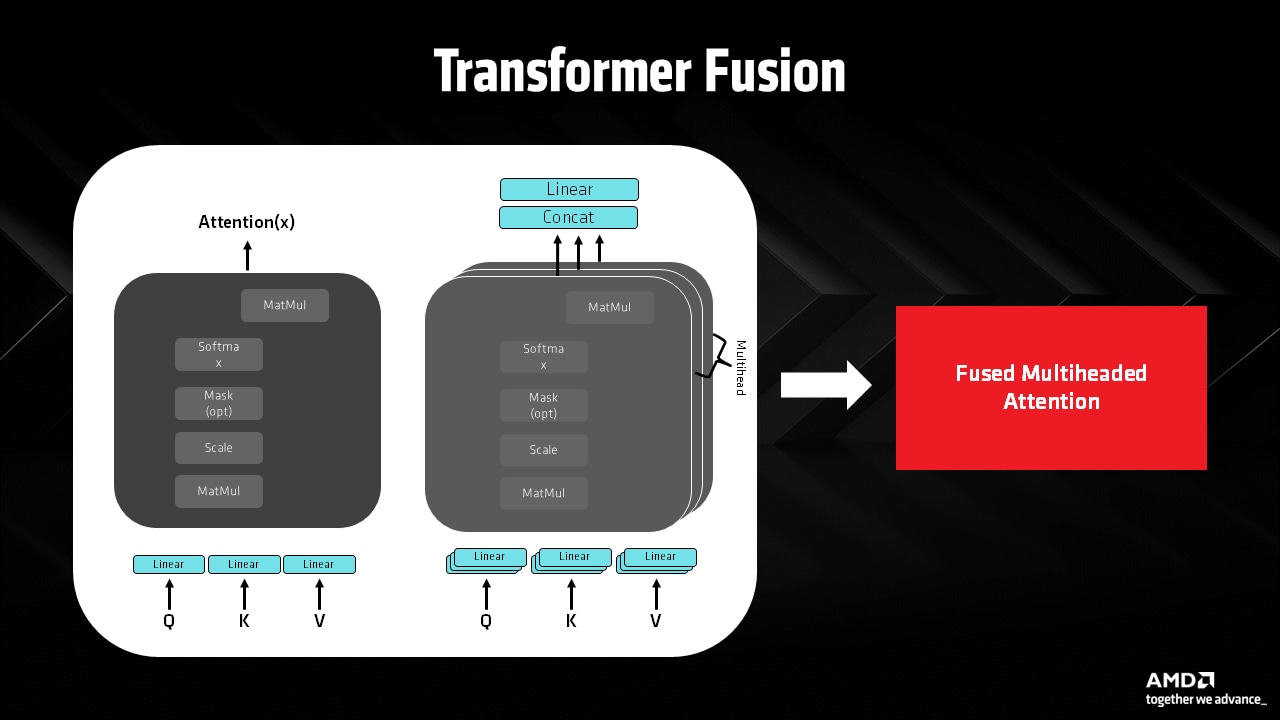 Fig 5: Fused attention blocks
Fig 5: Fused attention blocks
Generating unpacked attention node to reduce roundtrip to memory and increase the efficiency of the Matrix Multiply Accumulate (MMA) cores:
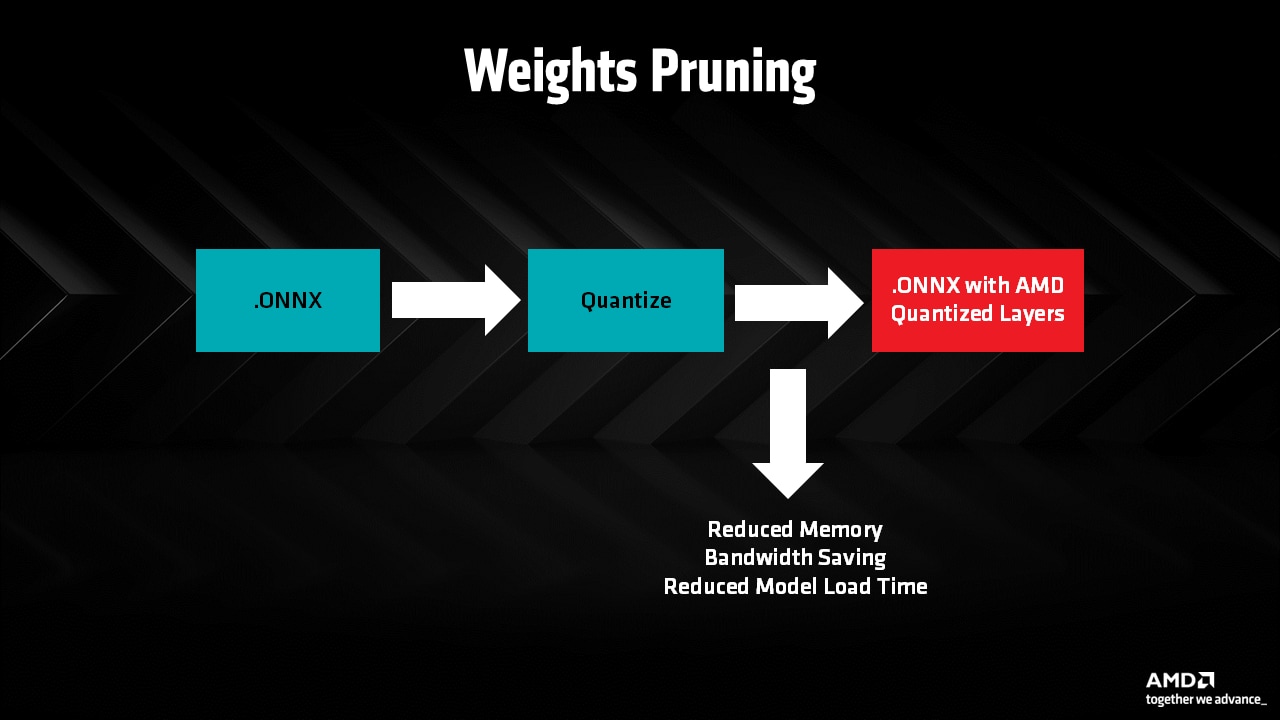
Weights pruning to reduce memory footprint loading and running generative AI models:
The AMD Radeon™ RX 9000 series GPUs, powered by AMD RDNA™ 4 architecture, introduce 2nd generation AI accelerators, delivering significant improvements over the AMD Radeon™ RX 7000 series (AMD RDNA™ 3 architecture) in capabilities, efficiency, and throughput. These advancements make the AMD RDNA™ 4 architecture a powerhouse for machine learning workloads, optimizing compute performance and data handling for next-generation AI applications.
On a per-compute-unit basis, AMD RDNA™ 4 doubles the 16-bit dense Matrix Multiply Accumulate (MMA or Wave MMA) operations per cycle and achieves up to 4x speedup for 8-bit and 4-bit integer WMMA operations compared to AMD RDNA™ 3. The introduction of new FP8 and BF8 precision formats further enhances compute throughput, offering 4x the 16-bit floating-point WMMA rate of AMD RDNA™ 3 (See footnote 4).
Beyond these raw compute gains, AMD RDNA™ 4 incorporates hardware support for 4:2 structured sparsity, effectively doubling the performance of standard dense WMMA operations when sparsity is leveraged. Additionally, AMD RDNA™ 4 optimizes data movement efficiency by reducing WMMA data replication in registers, enabling 2x larger tiling and improving data transfer efficiency from cache to registers (See footnote 4).
To further streamline ML workloads, the AMD RDNA™ 4 architecture introduces new transpose matrix load instructions, allowing data to be transposed in-flight while loading from memory. These enhancements make AMD RDNA™ 4 a powerful and efficient architecture for next-generation AI and machine learning applications, pushing the boundaries of GPU-accelerated computation.
 Fig 6: AMD 2nd generation AI Accelerators. See footnote 4
Fig 6: AMD 2nd generation AI Accelerators. See footnote 4
 Fig 7: AMD Radeon™ RX 9070 Series compute configs. See footnote 5
Fig 7: AMD Radeon™ RX 9070 Series compute configs. See footnote 5
| Data type | RX 7900 XTX FLOPS/clock/CU | RX 9070 XT FLOPS/clock/CU |
|---|---|---|
| FP16 | 512 | 1024 |
| BF16 | 512 | 1024 |
| FP8 | N/A | 2048 |
| BF8 | N/A | 2048 |
| IU8 | 512 | 2048 |
| IU4 | 1024 | 4096 |
| Data type | RX 7900 XTX FLOPS/clock/CU | RX 9070 XT FLOPS/clock/CU |
|---|---|---|
| FP16 | N/A | 2048 |
| BF16 | N/A | 2048 |
| FP8 | N/A | 4096 |
| BF8 | N/A | 4096 |
| IU8 | N/A | 4096 |
| IU4 | N/A | 8192 |
The below section gives a high-level overview of using dense matrix WMMA (Wave Matrix Multiply Accumulate) operations. Usability changes from AMD RDNA™ 3 architecture:
The call signature has changed slightly to accommodate the reduced register usage and layout changes.
// Use half16 as an alias of the internal clang vector type of 16 fp16 valuestypedef _Float16 half16 __attribute__((ext_vector_type(16)));
half16 a_frag;half16 b_frag;
// initialize c fragment to 0half16 c_frag = {};
///... load elements into the fragmentsc_frag = __builtin_amdgcn_wmma_f16_16x16x16_f16_w32(a_frag, b_frag, c_frag, false);
// 8 VGPRs per C,D fragment per thread in wave32 modeconst int lane = threadIdx.x % 16;
for (int ele = 0; ele < 8; ++ele){ // index into matrix C const int r = ele * 2 + (lIdx / 16); // store results from unpacked c_frag output c[16 * r + lane] = c_frag[ele*2];}// Use half8 as an alias of the internal clang vector type of 8 fp16 valuestypedef _Float16 half8 __attribute__((ext_vector_type(8)));
half8 a_frag;half8 b_frag;
// initialize c fragment to 0half8 c_frag = {};///... load elements into the fragments
c_frag = __builtin_amdgcn_wmma_f16_16x16x16_f16_w32_gfx12(a_frag, b_frag, c_frag);
// C frag is in the same layout as B matrix in registers, 4 vgprs per threadconst uint32_t outwaveRow = (__lane_id() >= 16) ? 8 : 0; // use wave lane id intrinsicconst uint32_t outwaveCol = (__lane_id() % 16);
#pragma unrollfor (int i = 0; i < 8; ++i){ const uint32_t rowAddr = outwaveRow + i; const uint32_t colAddr = outwaveCol;
// store results from packed c_frag output c[rowAddr * 16 + colAddr] = c_frag[i];}WMMA normally requires that the A matrix is row-major, and the B matrix is in column-major order in memory. This forces developers to either pre-transpose the B matrix into this format or do an inline transpose which is costly.
AMD RDNA™ 4 introduces a new efficient matrix load instruction that handles conversion from row-major to column-major and vice-versa on load, removing the need to perform these transforms manually.
Each datatype has its own transpose loader, but we will focus on Fp16 here.
This will execute a 128-bit load per lane, outputting a vector of 8 f16, transposing on load.
Threads are organized into octants whose data gets remapped into the correct register layout on load.
// Thread indexing math within the 16x16 tile to loadconst uint32_t quadGroup = __lane_id() / 4;const uint32_t quadGroupThreadPos = __lane_id() % 4;const uint32_t groupKHiLo = quadGroup % 2;const uint32_t groupKquarterHiLo = __lane_id() / 16;const uint32_t groupNHiLo = (__lane_id()/8) % 2;const uint32_t rowAddr = (quadGroupThreadPos + 8 * groupKHiLo + 4 * groupKquarterHiLo) * 16;const uint32_t colAddr = 8 * groupNHiLo;const uint32_t laneBaseAddr = rowAddr + colAddr;
using QuadWord = int16_t __attribute__((ext_vector_type(8)));
// we pointer cast from half to a 8 wide integer vector typeQuadWord* quadWordPtr = reinterpret_cast<QuadWord*>(BbufferPtr + laneBaseAddr);
regsB = __builtin_amdgcn_global_load_tr_b128_v8i16(quadWordPtr);Putting it all together, a simple, single WMMA kernel could look like this:
// Wave Matrix Multiply Accumulate (WMMA) using HIP compiler intrinsic
// Does a matrix multiplication of two 16x16, fp16 matrices, and stores them into a 16x16 fp16 result matrix
#include <iostream>#include <hip/hip_runtime.h>#include <hip/hip_fp16.h>
using namespace std;
// Use half8 as an alias of the internal clang vector type of 16 fp16 valuestypedef _Float16 half8 __attribute__((ext_vector_type(8)));
// assumes single wave per workgroup (32 threads)__global__ void wmma_matmul(__half* pA, __half* pB, __half* pC){
// a and b fragments are stored in 8 VGPRs each, in packed format, so 16 elements each for a and b // a_frag will store one column of the 16x16 matrix A tile // b_frag will store one row of the 16x16 matrix B tile half8 a_frag; half8 b_frag;
// initialize c fragment to 0 half8 c_frag = {};
// load A row-major in memory for (uint32_t i = 0, j = 8; i < 4; ++i, ++j) { uint32_t lowHigh = __lane_id() / 16; uint32_t rowAddr = __lane_id() % 16;
auto colAddr1 = i + lowHigh * 4; auto colAddr2 = j + lowHigh * 4;
a_frag[i] = pA[(rowAddr * 16) + colAddr1]; a_frag[i + 4] = pA[(rowAddr * 16) + colAddr2]; }
// load B if col-major memory for (uint32_t i = 0, j = 8; i < 4; ++i, ++j) { uint32_t lowHigh = __lane_id() / 16; uint32_t rowAddr = __lane_id() % 16;
auto colAddr1 = i + lowHigh * 4; auto colAddr2 = j + lowHigh * 4;
b_frag[i] = pB[(rowAddr * 16) + colAddr1]; b_frag[i + 4] = pB[(rowAddr * 16) + colAddr2]; }
// call the WMMA intrinsic with OPSEL set to "false" c_frag = __builtin_amdgcn_wmma_f16_16x16x16_f16_w32_gfx12(a_frag, b_frag, c_frag);
const uint32_t outwaveRow = (__lane_id() >= 16) ? 8 : 0; // use wave lane id intrinsic const uint32_t outwaveCol = (__lane_id() % 16);
for (int i = 0; i < 8; ++i) { const uint32_t rowAddr = outwaveRow + i; const uint32_t colAddr = outwaveCol;
// store results from packed c_frag output c[rowAddr * 16 + colAddr] = c_frag[i]; }}
// host code:int main(int argc, char* argv[]){ // declare input arrays on host __half a[16 * 16] = {}; __half b[16 * 16] = {}; __half c[16 * 16] = {};
__half *a_gpu, *b_gpu, *c_gpu;
// malloc the space on the debive hipMalloc(&a_gpu, 16*16 * sizeof(__half)); hipMalloc(&b_gpu, 16*16 * sizeof(__half)); hipMalloc(&c_gpu, 16*16 * sizeof(__half));
// fill in some data into matrices A and B for (int i = 0; i < 16; ++i) { for (int j = 0; j < 16; ++j) { a[i * 16 + j] = (__half)1.f; b[i * 16 + j] = (__half)1.f; } }
// upload the data to the gpu hipMemcpy(a_gpu, a, (16*16) * sizeof(__half), hipMemcpyHostToDevice); hipMemcpy(b_gpu, b, (16*16) * sizeof(__half), hipMemcpyHostToDevice); hipMemcpy(c_gpu, c, (16*16) * sizeof(__half), hipMemcpyHostToDevice);
// invoke the wmma kernel wmma_matmul<<<dim3(1), dim3(32, 1, 1), 0, 0>>>(a_gpu, b_gpu, c_gpu);
// wait for device to finish hipDeviceSynchronize();
// copy the result back to the host hipMemcpy(c, c_gpu, (16 * 16) * sizeof(__half), hipMemcpyDeviceToHost);
// free memory on the device hipFree(a_gpu); hipFree(b_gpu); hipFree(c_gpu);
for (int i = 0; i < 16; ++i) { for (int j = 0; j < 16; ++j) { printf("%f ", (float)c[i * 16 + j]); } printf("\\n"); }
return 0;}The above example is a simplified demonstration that doesn’t address how to process large GEMM operations across many workgroups, handle edge cases, or anything like that. There are a variety of techniques that can be leveraged to get the most out of the hardware with the main considerations being optimizing:
The specific techniques that can be explored to accomplish the above include:
AMD Playground application to run image generation using generative AI: https://www.amuse-ai.com/
HIP Programing Language: https://github.com/ROCm/HIP
AMD RDNA™ 3 WMMA: /learn/wmma_on_rdna3/
A pipelined implementation that incorporates many of the performance concepts above, and uses the simpler rocWMMA API for ease of use: https://github.com/ROCm/rocWMMA/blob/develop/samples/perf_hgemm.cpp
Understanding Latency Hiding on GPUs: https://www2.eecs.berkeley.edu/Pubs/TechRpts/2016/EECS-2016-143.pdf
Implementing Level 3 BLAS Routines in OpenCL on Different Processing Units: https://picture.iczhiku.com/resource/paper/WhKWkSfghuwIYvbX.pdf
THIS INFORMATION IS PROVIDED ‘AS IS.” AMD MAKES NO REPRESENTATIONS OR WARRANTIES WITH RESPECT TO THE CONTENTS HEREOF AND ASSUMES NO RESPONSIBILITY FOR ANY INACCURACIES, ERRORS, OR OMISSIONS THAT MAY APPEAR IN THIS INFORMATION. AMD SPECIFICALLY DISCLAIMS ANY IMPLIED WARRANTIES OF NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR ANY PARTICULAR PURPOSE. IN NO EVENT WILL AMD BE LIABLE TO ANY PERSON FOR ANY RELIANCE, DIRECT, INDIRECT, SPECIAL, OR OTHER CONSEQUENTIAL DAMAGES ARISING FROM THE USE OF ANY INFORMATION CONTAINED HEREIN, EVEN IF AMD IS EXPRESSLY ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
The information presented in this document is for informational purposes only and may contain technical inaccuracies, omissions, and typographical errors. The information contained herein is subject to change and may be rendered inaccurate for many reasons, including but not limited to product and roadmap changes, component and motherboard version changes, new model and/or product releases, product differences between differing manufacturers, software changes, BIOS flashes, firmware upgrades, or the like. Any computer system has risks of security vulnerabilities that cannot be completely prevented or mitigated. AMD assumes no obligation to update or otherwise correct or revise this information. However, AMD reserves the right to revise this information and to make changes from time to time to the content hereof without obligation of AMD to notify any person of such revisions or changes. GD-18.
Links to third-party sites are provided for convenience and unless explicitly stated, AMD is not responsible for the contents of such linked sites, and no endorsement is implied. GD-98.
GD-220e: Ryzen™ AI is defined as the combination of a dedicated AI engine, AMD Radeon™ graphics engine, and Ryzen processor cores that enable AI capabilities. OEM and ISV enablement is required, and certain AI features may not yet be optimized for Ryzen AI processors. Ryzen AI is compatible with: (a) AMD Ryzen 7040 and 8040 Series processors and Ryzen PRO 7040/8040 Series processors except Ryzen 5 7540U, Ryzen 5 8540U, Ryzen 3 7440U, and Ryzen 3 8440U processors; (b) AMD Ryzen AI 300 Series processors and AMD Ryzen AI PRO 300 Series processors; (c) all AMD Ryzen 8000G Series desktop processors except the Ryzen 5 8500G/GE and Ryzen 3 8300G/GE; (d) AMD Ryzen 200 Series processors and Ryzen PRO 200 Series processors except Ryzen 5 220 and Ryzen 3 210; and (e) AMD Ryzen AI Max Series processors and Ryzen AI PRO Max Series processors. Please check with your system manufacturer for feature availability prior to purchase. GD-220e.
Microsoft® Olive is an active branch which changes often, so the interfaces and setup may look slightly different depending on when the branch is downloaded.
© 2025 Advanced Micro Devices, Inc. All rights reserved. AMD, the AMD Arrow logo, Radeon, Ryzen, and combinations thereof are trademarks of Advanced Micro Devices, Inc. Microsoft is a registered trademark of Microsoft Corporation in the US and/or other countries. Other product names used in this publication are for identification purposes only and may be trademarks of their respective owners. Certain AMD technologies may require third-party enablement or activation. Supported features may vary by operating system. Please confirm with system manufacturer for specific features. No technology or product can be completely secure.
RX-1189: Testing as of April 2025 by AMD. All tests conducted using Amuse 3.0 RC and Adrenalin 24.30.31.05 Driver. Sustained performance average (elapsed time) of multiple runs using the specimen prompt: “Craft an image of a cozy fireplace with crackling flames, flickering candles, and a pile of cozy blankets nearby”. Models tested: Stable Diffusion 1.5, Stable Diffusion XL 1.0, SDXL Turbo, SD 3.0 Medium, Stable Diffusion 3.5 Large and Stable Diffusion 3.5 Large Turbo against Microsoft Olive conversion of the base model. AMD Radeon™ RX 9070 XT 16GB with Intel Core i9 13900K, 32GB DDR5 4800 MT/s memory and Windows 11 Pro 24H2. Performance in partial offload configurations will be affected by disk and memory speeds. Performance may vary. RX-1189. ↩
SHO-31: Testing as of April 2025 by AMD. All tests conducted using Amuse 3.0 RC and Adrenalin 24.30.31.05 Driver. Sustained performance average (elapsed time) of multiple runs using the specimen prompt: “Craft an image of a cozy fireplace with crackling flames, flickering candles, and a pile of cozy blankets nearby”. Models tested: Stable Diffusion 1.5, Stable Diffusion XL 1.0, SDXL Turbo, SD 3.0 Medium, Stable Diffusion 3.5 Large and Stable Diffusion 3.5 Large Turbo against Microsoft Olive conversion of the base model. ASUS ROG Flow Z13 equipped with an AMD Ryzen™ AI MAX+ 395 processor and 64GB of DDR5 8000 MT/s memory and Windows 11 Pro 24H2. Variable Graphics Memory set to 48GB. Performance may vary. SHO-31. ↩
STX-118: Testing as of April 2025 by AMD. All tests conducted using Amuse 3.0 RC and Adrenalin 24.30.31.05 Driver. Sustained performance average (elapsed time) of multiple runs using the specimen prompt: “Craft an image of a cozy fireplace with crackling flames, flickering candles, and a pile of cozy blankets nearby”. Models tested: Stable Diffusion 1.5, Stable Diffusion XL 1.0, SDXL Turbo, SD 3.0 Medium and Stable Diffusion 3.5 Large Turbo against Microsoft Olive conversion of the base model. ASUS Zenbook S16 equipped with an AMD Ryzen™ AI 9 HX 370 processor and 32 GB of DDR5 7500 MT/s memory and Windows 11 Pro 24H2. Variable Graphics Memory set to 16GB. Performance may vary. STX-118. ↩
RX-1143: Based on specifications of AMD RDNA 4 architecture compared to AMD RDNA 3 architecture as of December 2024. ↩ ↩2 ↩3
GD-151: Boost Clock Frequency is the maximum frequency achievable on the GPU running a bursty workload. Boost clock achievability, frequency, and sustainability will vary based on several factors, including but not limited to: thermal conditions and variation in applications and workloads. GD-151. ↩