HIP Ray Tracing
HIP RT is a ray tracing library for HIP, making it easy to write ray tracing applications in HIP.
If your CPU hotspots are hitting performance, and your GPU is sitting idle, here’s how to fix both.
Your profiler shows it clearly: those CPU hotspots are limiting performance. You know GPUs could help, but your team doesn’t have GPU experts. Sound familiar?
You’re not alone. Many development teams leave performance on the table because traditional GPU programming requires significant changes and specialized knowledge. Many teams don’t touch the GPU because the learning curve is steep and the ROI timeline is long.
HIP Threads is a C++ concurrency library that lets you use AMD GPUs with the same mental model you already use for CPU multithreading. No kernel rewrites. No unfamiliar programming models. Just your trusted C++ patterns, running on GPUs.
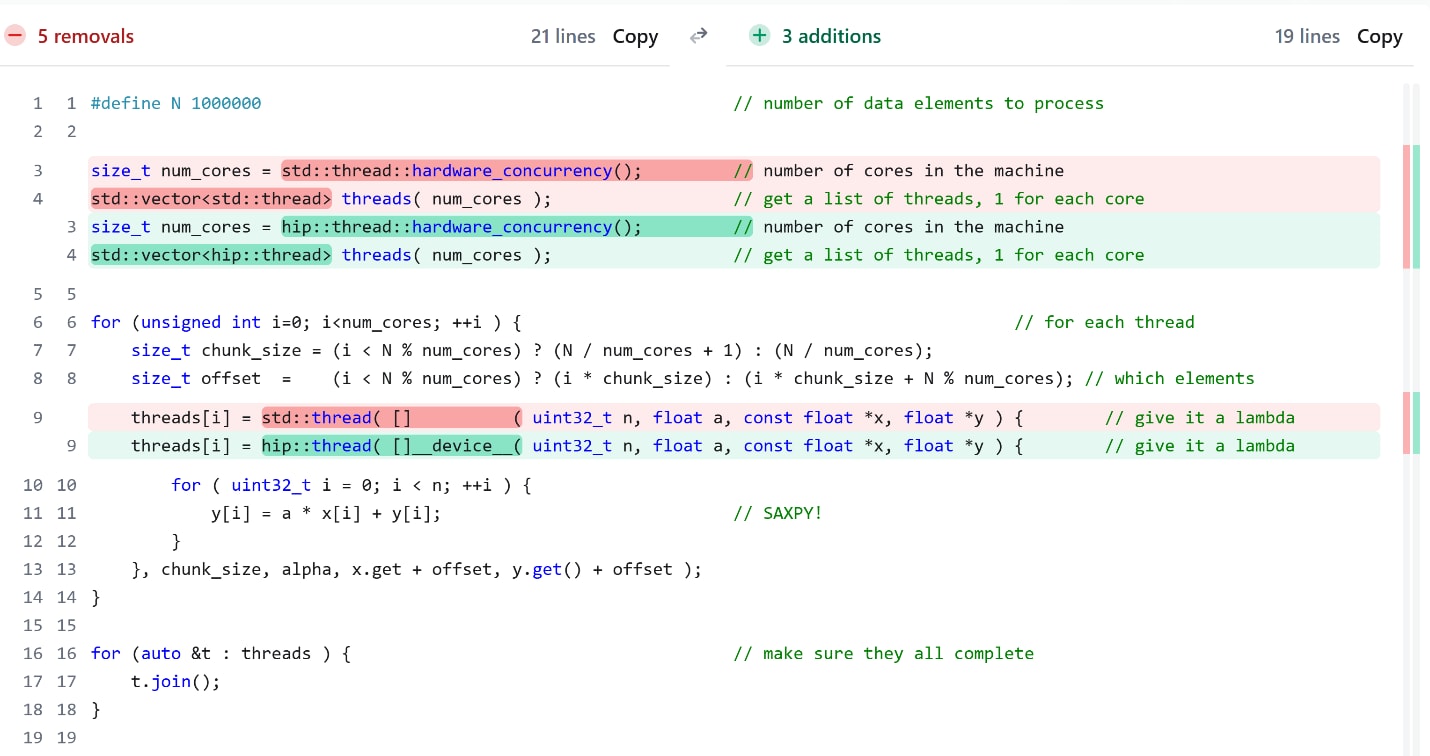
*// That’s it. Your code now runs on AMD GPUs.
These are reported speedups from early users. Here’s what teams achieved in just days:
| Application | Performance Gain | Time to Implement |
|---|---|---|
| SAXPY Operations | 6.4x faster* | Days, not months |
| Ray Tracing | 2.9x faster* | Days, not months |
| Sparse Matrix Multiply | 3.6x faster* | Days, not months |
*See claims RPS-167, RPS-168, and RPS-169 in footnotes.
HIP Threads is perfect for:
C++ teams with CPU bottlenecks who see clear hotspots in their profiler.
Developers without GPU expertise who can’t justify learning CUDA/AMD ROCm™.
Tool vendors and platform teams who want simple GPU integration for their users.
Traditional GPU programming:
Learn new programming models (grids, blocks, warps).
Rewrite working code into kernels.
Justify months of refactoring to management.
Hire GPU specialists or train your team for long-term support.
With HIP Threads:
Use your existing C++ threading knowledge.
It fits easily into your development environment.
Port hotspots incrementally.
See results in days, not months.
HIP Threads maps familiar C++ threading patterns to efficient GPU execution. No magic, just smart engineering that bridges the gap between CPU and GPU programming models. Think of it as a translator that speaks both C++ developer and GPU hardware fluently.
We’re actively working with developers, tool vendors, and platform teams who want to make GPU acceleration as approachable as CPU threading.
Your GPUs are waiting. You know your hotspots. The only thing standing between you and significant performance gains is starting. No GPU expertise required. No massive refactoring. Just more performance.
Discuss this blog on the AMD Developer Community.
Sign up to our AMD Developer Newsletter for the latest news.
Footnotes
Testing by AMD as of February 2026, on the AMD Radeon™ AI PRO R9700 using ROCm 7.0.2 and AMDGPU driver 6.16.6 driver using HIP Threads on the GPU versus standard threads on the CPU, on a test system configured with an AMD Ryzen™ 9 9900X, AMD Radeon™ AI PRO R9700, 64GB DDR5-4800 RAM, ASUS TUF GAMING B850-PLUS WIFI motherboard, and Ubuntu 24.04.2 LTS, using the SAXPY (Single-precision A times X plus Y) computation function test. System manufacturers may vary configurations, yielding different results. RPS-167.
Testing by AMD as of February 2026, on the AMD Radeon™ AI PRO R9700 using ROCm 7.0.2 and AMDGPU driver 6.16.6 driver using HIP Threads on the GPU versus standard threads on the CPU, on a test system configured with an AMD Ryzen™ 9 9900X, AMD Radeon™ AI PRO R9700, 64GB DDR5-4800 RAM, ASUS TUF GAMING B850-PLUS WIFI motherboard, and Ubuntu 24.04.2 LTS, using the “Ray Tracing in One Weekend” ray traced rendering test. System manufacturers may vary configurations, yielding different results. RPS-168.
Testing by AMD as of February 2026, on the AMD Radeon™ AI PRO R9700 using ROCm 7.0.2 and AMDGPU driver 6.16.6 driver using HIP Threads on the GPU versus standard threads on the CPU, on a test system configured with an AMD Ryzen™ 9 9900X, AMD Radeon™ AI PRO R9700, 64GB DDR5-4800 RAM, ASUS TUF GAMING B850-PLUS WIFI motherboard, and Ubuntu 24.04.2 LTS, using the Sparse Matrix Multiply (pwtk.mtx) test. System manufacturers may vary configurations, yielding different results. RPS-169.