HIP Ray Tracing
HIP RT is a ray tracing library for HIP, making it easy to write ray tracing applications in HIP.
In this blog, we present HIP RT v2.2. The major change for this version is that HIP RT now supports multi-level instancing.
In some cases, it might be beneficial to organize a scene into more than two levels. Multi-level instancing may reduce memory requirements significantly. For instance, a single geometry representing an apple can be instantiated as a part of a tree, and the tree can be instantiated to form a forest. (see the illustration below) We can also organize scenes semantically: meshes are organized into objects, and the objects are organized into a scene. This feature is essential to render a large scene with limited amount of memory.
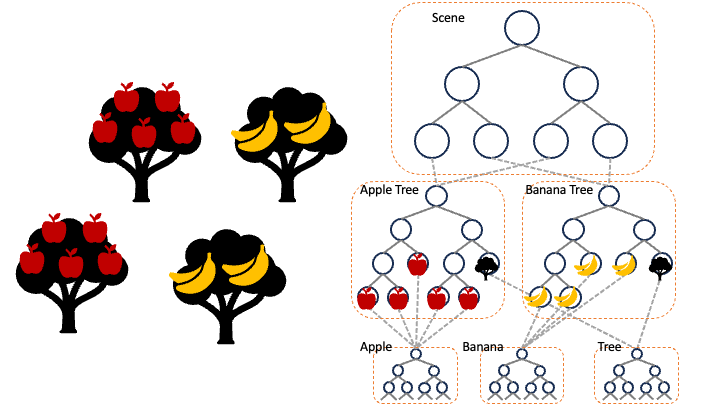
To support multi-level instancing in HIP RT, we introduce a new structure representing an instance in HIP RT such that we can instantiate not only geometries but also scenes:
struct hiprtInstance{ hiprtInstanceType type; union { hiprtGeometry geometry; hiprtScene scene; };};In the build input struct, the array of instantiated geometries is replaced by an array of instances:
struct hiprtSceneBuildInput{ /* A device array of 'hiprtInstance' objects */ hiprtDevicePtr instances; ...};To traverse a hierarchy with more than two levels, we need an additional stack to backtrack to upper levels (one entry for each extra instance level). The default traversal objects implicitly contain this instance stack with four entries (at most five levels). For the traversal objects with a custom stack, we have to specify the instance stack explicitly:
...hiprtSharedStackBuffer sharedInstanceStackBuffer{};hiprtGlobalInstanceStack instanceStack(globalInstanceStackBuffer, sharedInstanceStackBuffer);hiprtSceneTraversalClosestCustomStack<hiprtGlobalStack, hiprtGlobalInstanceStack> tr(scene, ray, stack, instanceStack);The global instance stack buffer can be created via the HIP RT API:
hiprtGlobalStackBufferInput instanceStackBufferInput;instanceStackBufferInput.type = hiprtStackTypeGlobal;instanceStackBufferInput.entryType = hiprtStackEntryTypeInstance;instanceStackBufferInput.stackSize = InstanceStackSize;instanceStackBufferInput.threadCount = MaxThreads;
hiprtGlobalStackBuffer globalInstanceStackBuffer;hiprtCreateGlobalStackBuffer(context, instanceStackBufferInput, globalInstanceStackBuffer);The instance stack management brings additional logic to the traversal loop using more registers than the two-level traversal. Since the instance stack type is a template argument, by passing hiprtEmptyInstanceStack, the compiler instantiates the code without the logic for multiple levels.
In the case of multi-level instancing, instead of a single instance ID, we now have multiple IDs (one for each instance level). The first ID corresponds to the top level, the second ID to the next level, and so on:
struct hiprtHit{ union { uint32_t instanceID = hiprtInvalidValue; uint32_t instanceIDs[hiprtMaxInstanceLevels]; }; uint32_t primID = hiprtInvalidValue; hiprtFloat2 uv; hiprtFloat3 normal; float t = -1.0f;};We also extended the transformation query functions to handle multiple instance IDs:
hiprtFrameSRT hiprtGetObjectToWorldFrameSRT(hiprtScene scene, const uint32_t (&instanceIDs)[hiprtMaxInstanceLevels], float time = 0.0f);hiprtFrameSRT hiprtGetWorldToObjectFrameSRT(hiprtScene scene, const uint32_t (&instanceIDs)[hiprtMaxInstanceLevels], float time = 0.0f);hiprtFrameMatrix hiprtGetObjectToWorldFrameMatrix(hiprtScene scene, const uint32_t (&instanceIDs)[hiprtMaxInstanceLevels], float time = 0.0f);hiprtFrameMatrix hiprtGetWorldToObjectFrameMatrix(hiprtScene scene, const uint32_t (&instanceIDs)[hiprtMaxInstanceLevels], float time = 0.0f);There is one conceptual change we need to mention. In the previous versions, the normal returned in the hit structure was in the world space. Internally, we had to transform this normal manually to world space after the traversal loop. This is way more complicated with multiple levels, introducing non-negligible overhead. We also noticed that most of the user applications do not use this normal at all. Therefore, we decided to return the normal in the object space. If needed, we introduced the following functions that can be used to transform the normal to world space:
hiprtFloat3 hiprtNormalObjectToWorld(hiprtFloat3 normal, hiprtScene scene, uint32_t instanceID, float time = 0.0f);hiprtFloat3 hiprtNormalObjectToWorld(hiprtFloat3 normal, hiprtScene scene, const uint32_t (&instanceIDs)[hiprtMaxInstanceLevels], float time = 0.0f);Our team also worked on and managed to run PBRT-v4 on AMD GPUs. Specifically, it has another GPU backend, which was ported to HIP and HIPRT. Our fork of PBRT-v4 can be found here. The multi-level instancing is one of the important features that allows the rendering on a GPU with limited VRAM. The image below is the Moana Island Scene rendered on the AMD Radeon™ PRO W7900 with 48GB VRAM, in-core. This scene is organized into three levels with 156 unique primitives and 31 billion instantiated primitives:

Another critical feature is batch construction introduced in HIPRT v2.1, which accelerates BVH build over many small geometries. This is especially useful for hair models consisting of millions of hair strands, where each hair strand is represented as a single geometry:


Besides multi-level instancing, we added compaction for geometries and scenes, creating a copy of the structure with smaller memory footprint. We also significantly optimized the construction speed, especially for the fast and balanced build.
The download link for HIP RT v2.2 is available on the HIP RT page. The PBRT HIP port is available on the GPUOpen Github.
If you’re looking for some guidance on getting started with HIPRT, check out the HIP RT SDK tutorials repository and the HIP RT documentation page.
Moana Island Scene
Copyright 2017-2022 Disney Enterprises, Inc. All rights reserved.
THIS SCENE DESCRIPTION IS PROVIDED BY WALT DISNEY PICTURES “AS IS” AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL WALT DISNEY PICTURES BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SCENE DESCRIPTION, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.