AMD Radeon™ GPU Profiler
AMD RGP gives you unprecedented, in-depth access to a GPU. Easily analyze graphics, async compute usage, event timing, pipeline stalls, barriers, bottlenecks, and other performance inefficiencies.
AMD hardware can process neural networks extremely fast with the ONNX Runtime - DirectML execution provider (EP), but it’s also important to know how to use it correctly.
In this topic, I will discuss a common way to utilize the performance of the ONNX Runtime - DirectML EP and prevent data transfer between CPU and GPU.
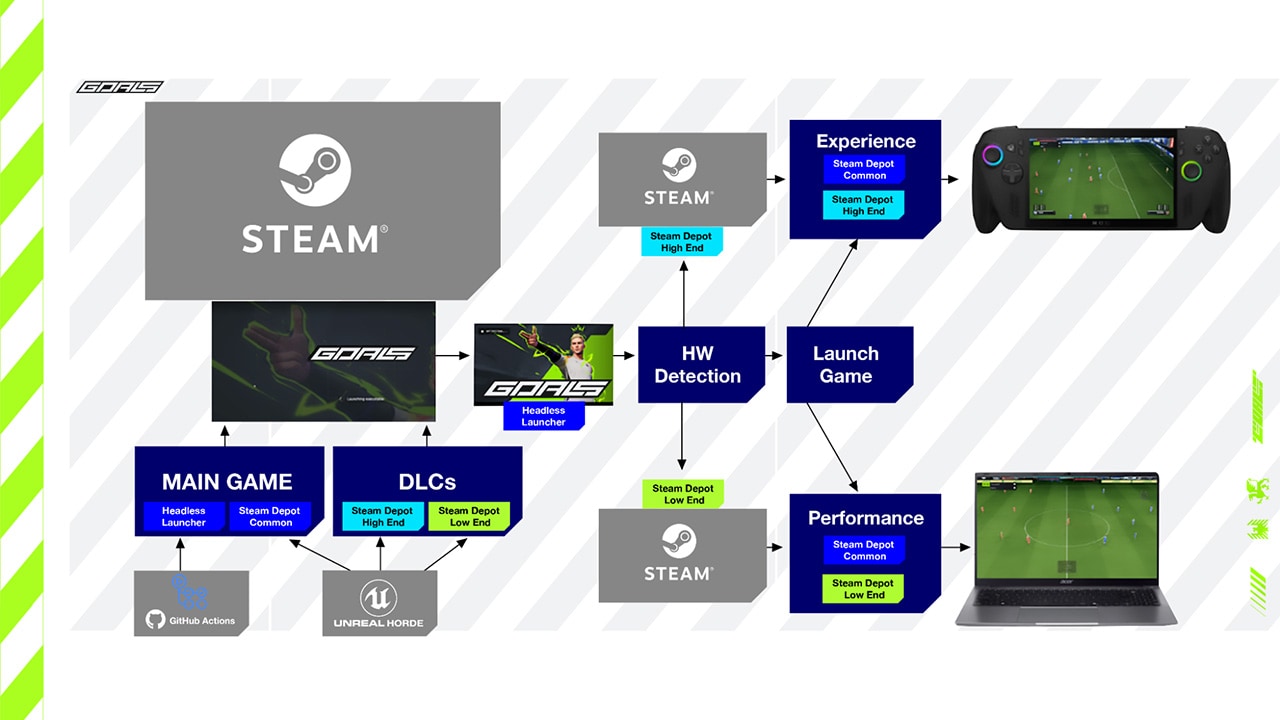
First, let’s start a basic scenario when using the ONNX Runtime - DirectML EP.
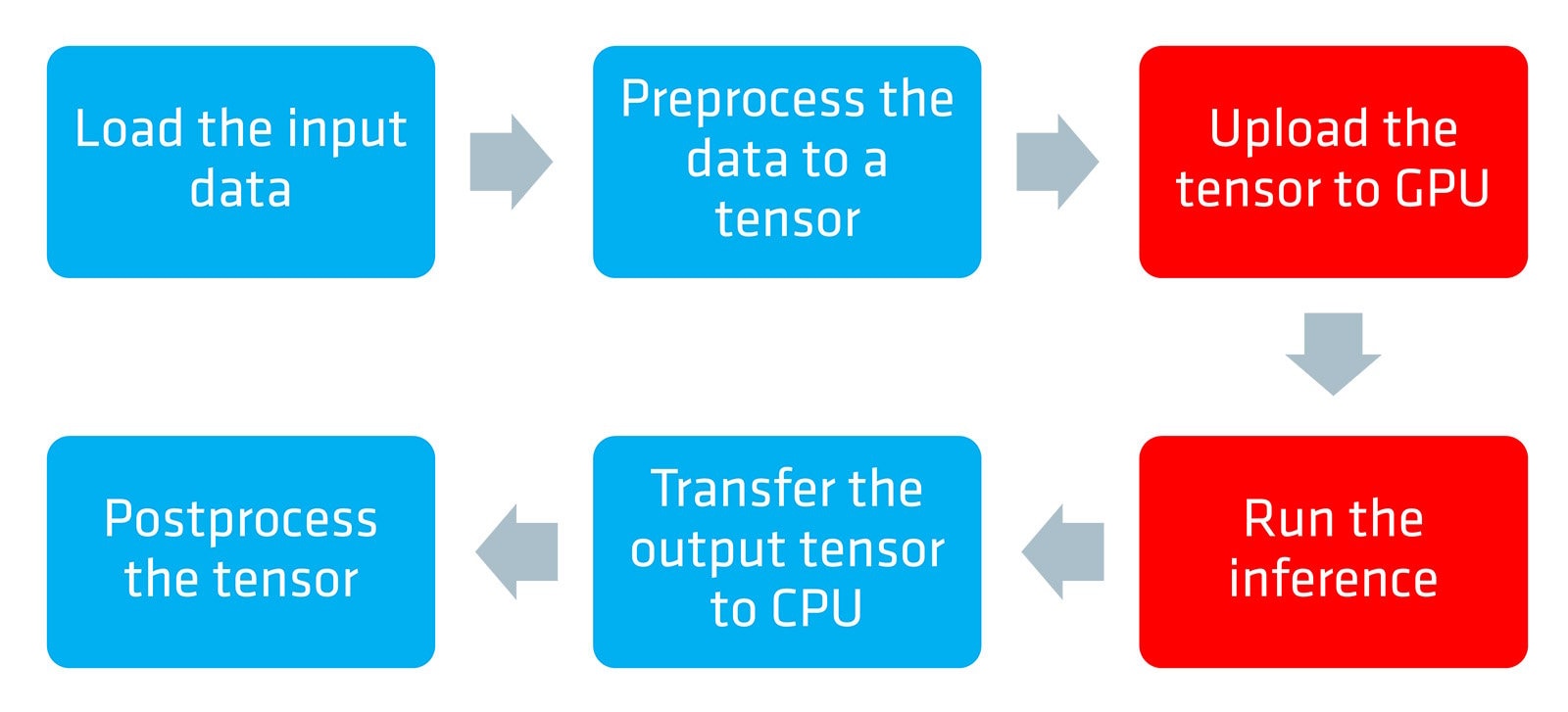
In this scenario, there are many data transfers between the CPU and the GPU that can cause unnecessary latency. A GPU is faster for pre- and post-processing than a CPU and the input data might already be on the GPU, for example, in a gaming scenario.
A much better way would be to build a native inference pipeline to execute all the procedures on the GPU, which makes sense.
But how do you put it into practice with the ONNX Runtime - DirectML EP? For that, you need to dive into DirectX® 12 which is the basis of DirectML.
Usually, DirectML creates a DirectX 12 device and compute queue by itself. But for native pipelines, end users also need a DirectX 12 device and queue to pre- and post-process the data, so the same DirectX 12 context should be shared by end users and DirectML.
To use the ONNX Runtime - DirectML EP + DirectX 12, there must be a way to create DirectML context with an existing DirectX 12 device and queue that can be reached by the DirectML API.
Ort::SessionOptions sessionOptions;Ort::GetApi().GetExecutionProviderApi("DML", ORT_API_VERSION, reinterpret_cast<const void**>(&OrtDmlApi));Microsoft::WRL::ComPtr<ID3D12Device> dx12Device;Microsoft::WRL::ComPtr<IDMLDevice> dmlDevice;// Create DML device via DX12 device.HRESULT hr = DMLCreateDevice1(dx12Device.Get(), DML_CREATE_DEVICE_FLAG_NONE, DML_FEATURE_LEVEL_2_0, IID_PPV_ARGS(&dmlDevice));if (SUCCEEDED(hr)) { Microsoft::WRL::ComPtr<ID3D12CommandQueue> commandQueue; D3D12_COMMAND_QUEUE_DESC desc{}; desc.Flags = D3D12_COMMAND_QUEUE_FLAG_NONE; desc.Type = D3D12_COMMAND_LIST_TYPE_COMPUTE;
if (SUCCEEDED(hr = dx12Device->CreateCommandQueue(&desc, IID_PPV_ARGS(&commandQueue)))) { // Enable the DML device in current session. OrtDmlApi->SessionOptionsAppendExecutionProvider_DML1(sessionOptions, dmlDevice.Get(), commandQueue.Get()); }}Now you can create the ONNX Runtime session in the normal way with the Ort::SessionOptions object.
Now that the ONNX Runtime - DirectML EP + DirectX 12 context is created, let’s talk about how to build the input and output tensor.
As the ONNX Runtime - DirectML EP is based on DirectX 12, there must be a way to create a DirectML tensor value with an existing DirectX 12 resource that can also be reached by the DirectML API.
ID3D12Resource* resource; // resource must be initialized before. std::vector<int64_t> shape = { 1920, 1080 }; // dummy shape size ONNXTensorElementDataType type = ONNX_TENSOR_ELEMENT_DATA_TYPE_FLOAT;
void* dmlAllocatorResource; Ort::ThrowOnError(ortDmlApi->CreateGPUAllocationFromD3DResource(resource, &dmlAllocatorResource));
// reset this ptr once dml resource isn't needed in the future. std::unique_ptr<void, std::function<void(void*)>> dmlAllocatorResourceCleanup(dmlAllocatorResource, [ortDmlApi](void* ptr) { ortDmlApi->FreeGPUAllocation(ptr); });
Ort::MemoryInfo memoryInfo("DML", OrtAllocatorType::OrtDeviceAllocator, 0, OrtMemType::OrtMemTypeDefault);
// create the OrtValue as a tensor letting ort know that we own the data buffer OrtValue* value; Ort::ThrowOnError(ortApi.CreateTensorWithDataAsOrtValue( memoryInfo, dmlAllocatorResource, static_cast<size_t>(resource->GetDesc().Width), shape.data(), shape.size(), type, &value));
return { Ort::Value(value), std::move(dmlAllocatorResourceCleanup) };Now the existing DirectX 12 resource is mapped to an Ort::Value object. You can run the inference via Ort::Session::Run(...) with the input and output Ort::Value containing your DirectX 12 resource.
Although it isn’t necessary, as you already have the reference of the DirectX 12 resource, there is a way to get the DirectX 12 resource from the Ort::Value, and this is useful when you want to get the DirectX 12 resource reference from the Ort::Value created by the ONNX Runtime - DirectML EP itself.
ComPtr<ID3D12Resource> inputResource;Ort::ThrowOnError(ortDmlApi->GetD3D12ResourceFromAllocation(allocator, inputTensor.GetTensorMutableData<void*>(), &inputResource));As the DirectX 12 resources are now mapped to the Ort::Value, you can now work on how to make preprocessing and postprocessing faster.
This can be achieved by the existing DirectX 12 device and its compute shader queue.
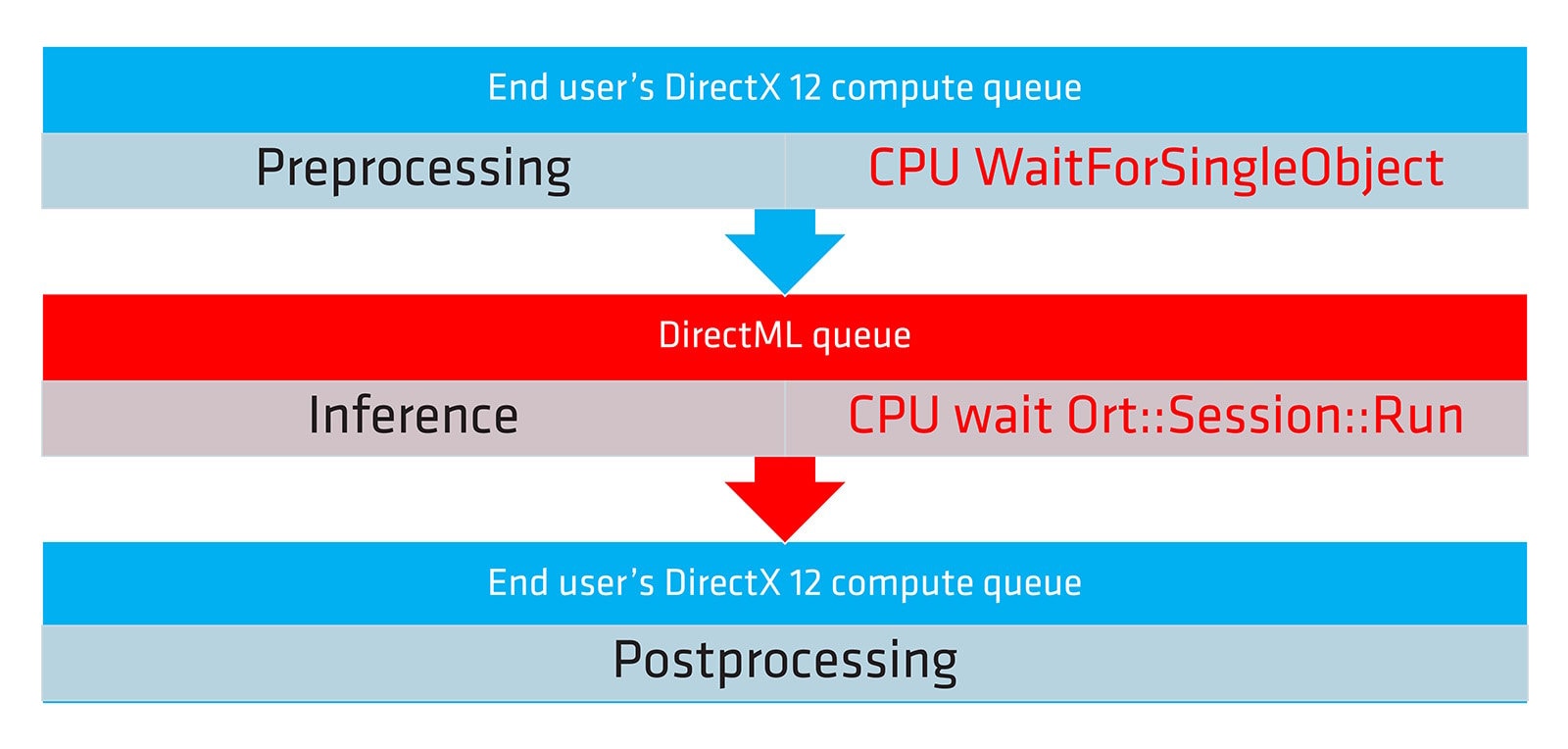
As DirectML doesn’t expose the DirectX 12 command list used by the command queue, it’s hard to use GPU synchronization between preprocessing and inference.
Also, Ort::Session::Run(...) uses CPU synchronization to leverage the difference of each execution provider, so it’s also hard to use GPU synchronization between inference and postprocessing.
There are some limitations of the DirectML API and might cause more CPU workload, which may be addressed in future API updates from Microsoft.
Although I’ve covered a lot of theoretical knowledge in this topic, practice makes perfect, so I encourage you to spend more time experimenting with some of the example code available online.
Also the official DirectML NPU sample shows the conversion between the Ort::Value and DirectX 12 resource very well, and although it’s for an NPU, it can be very easily ported to a GPU.
For more information about the execution process, please check out the code comments.