AMD Radeon™ Developer Panel
The RDP provides a communication channel with the Radeon™ Adrenalin driver. It generates event timing data used by the Radeon™ GPU Profiler (RGP), and the memory usage data used by the Radeon™ Memory Visualizer (RMV).
With the October 2024 AMD Radeon™ Developer Tools Suite release, we are thrilled to announce a new addition to our tools family that has been in development for quite some time: Driver Experiments.
If you are a graphics programmer, you may have encountered situations when you thought: - Why is my application crashing or working incorrectly on this particular GPU? If only I could disable some optimizations done by the graphics driver or enable some extra safety features, I would check if the bug goes away.
Or, if you don’t have the source code of your application on the machine where you are testing to be able to reconfigure it, you could say: - I wish I could pretend my GPU doesn’t support ray tracing, or force-off V-sync, and see if it helps.
Or, maybe you even thought: - I suspect this is a bug in the graphics driver! I am sure developers at AMD have some secret tools to control it that helps them with testing. If only such tool was available publicly…
Now, with Driver Experiments, it all becomes possible!
To get started with the Driver Experiments feature, you need Radeon Developer Panel v3.2 or later. You will also need the following:
Driver Experiments offer a way to change the behavior and performance characteristics of a game or other graphics application without modifying its source code or configuration. They control the low-level behavior of the graphics driver. This tool exposes some of the driver settings that were previously only available to AMD engineers who develop the driver, e.g. disabling support for ray tracing or some optimizations in the shader compiler. It may be useful for debugging issues in graphics applications – alone or together with other tools, like Radeon GPU Detective (RGD), Radeon GPU Profiler (RGP), Radeon Memory Visualizer (RMV), or Radeon Raytracing Analyzer (RRA).
Driver Experiments, like all the tools in the Radeon Developer Tool Suite, are intended for developers, and not for end users. They should be used only in the in-house development or testing environment.
Note the difference between Driver Experiments and settings available in AMD Software: Adrenalin Edition. Although there may be some overlap (e.g. v-sync control), settings available on AMD Software generally allow tweaking the experience in games, so they are intended for end users, while Driver Experiments expose lower-level controls of the graphics driver that may influence the behavior, performance, or even stability of an application, and so they should be only used carefully and consciously by graphics programmers.
In addition, please note that, in some special cases, an enabled experiment may end up not being activated on certain system configurations (depending on the GPU model, driver version and application logic).
Driver Experiments can help identify bugs in graphics applications. Such bugs often arise from incorrect use of the graphics API (DirectX® 12, Vulkan®). It is important to also use other means of debugging, like errors and warnings reported by the debug/validation layers, or frame capturing tools such as PIX on Windows or RenderDoc.
Some bugs can also be attributed to the graphics driver. Although not uncommon, they shouldn’t be the first suspect when debugging. When using modern graphics APIs, which are low-level and close to the hardware, bugs are usually on the application side even if an application works correctly on one GPU and works incorrectly or crashes on another GPU vendor or model.
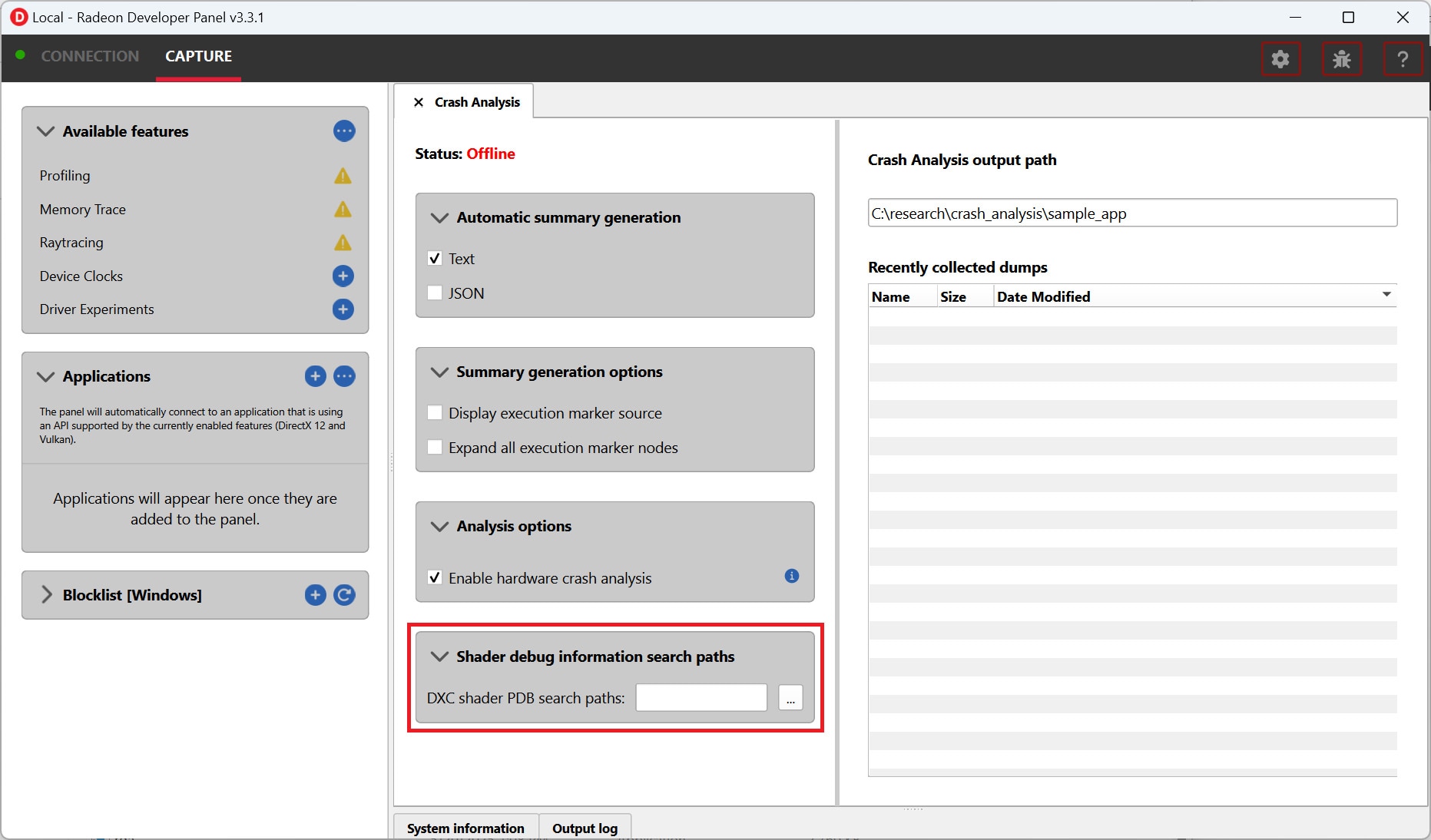
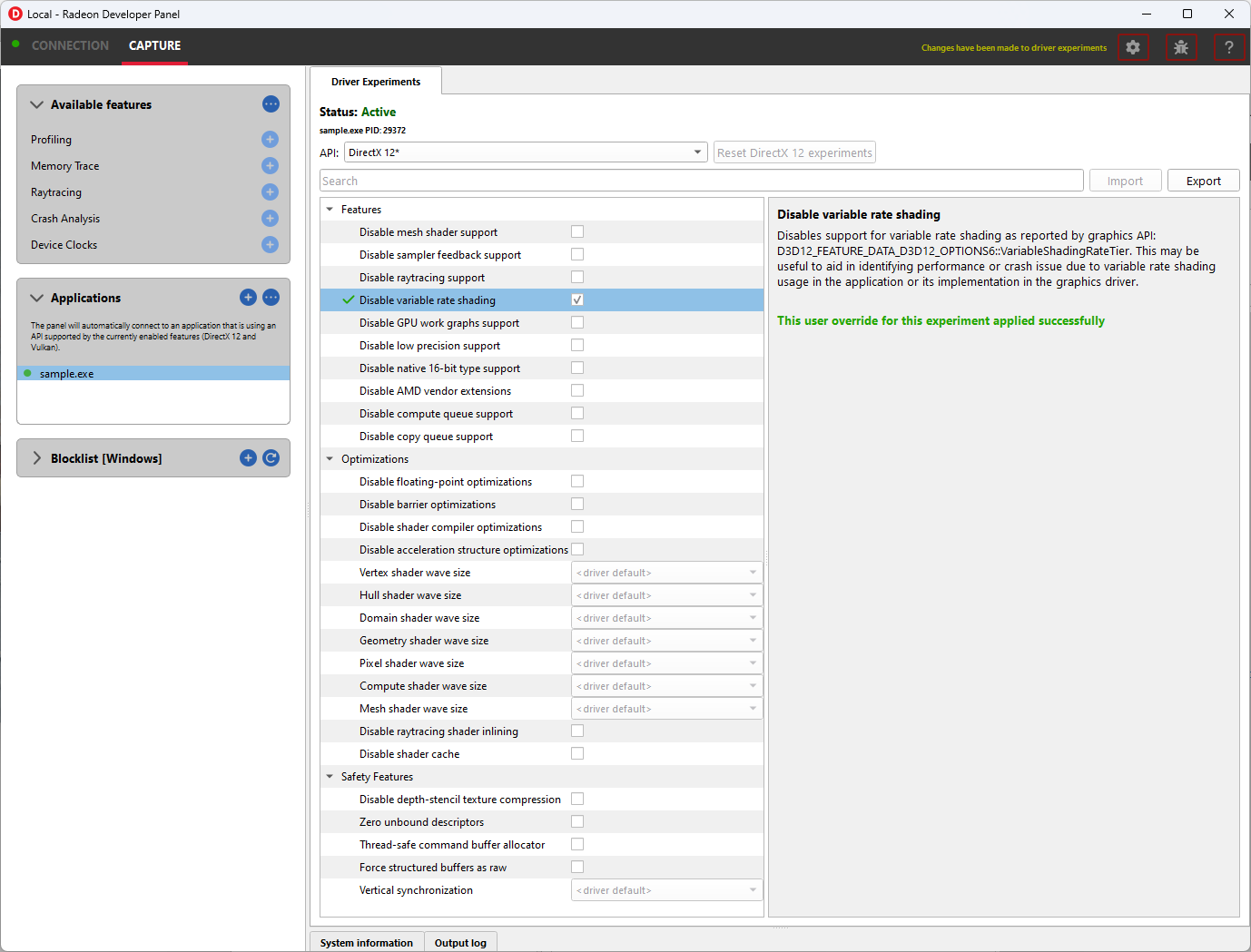
Driver Experiments are activated using the Radeon Developer Panel. As of RDP v3.2 you will find a new “Driver Experiments” feature in the panel alongside other features like “Profiling” or “Crash Analysis”. That feature will display the list of experiments that are supported for each API and will allow you to activate experiments for the next application that connects to the panel.
Note that experiments are active only as long as Radeon Developer Panel is running. Closing the Panel application or restarting the system reverts them to defaults.
For more details about how to activate Driver Experiments using RDP, please refer to the RDP product documentation.
The current set of experiments to modify and their values can be saved to a JSON file using Export button and loaded later using Import button.
Experiments are separate per graphics API (DirectX 12, Vulkan). Both APIs offer a similar set of experiments, but some of them are available in only one API.
Experiments may be used as the only feature in Radeon Developer Panel or together with other features.
For example, taking an RGP capture while experiments are activated will allow you to observe how the experiments influenced the performance of some specific render passes and draw calls.
You may, alternatively, enable Crash Analysis feature and capture an RGD crash dump. Opening files captured with active driver experiments in their respective tools will display a notification that the file was captured with some driver experiments applied, and lists their values.

Experiments in this group allow disabling support for some of the hardware features of modern AMD/Radeon GPUs. They may be useful for debugging. Activating the experiment disables a specific feature.
Disable mesh shader support
Disable sampler feedback support
Disable raytracing support
Disable variable rate shading
Disable GPU work graphs support
These experiments make it possible to disable support for some of the new GPU hardware features. When activated, the graphics API exposes no support for the feature, like D3D12_FEATURE_DATA_D3D12_OPTIONS7::MeshShaderTier, or equivalent Vulkan extension, like VK_EXT_mesh_shader, as if the GPU doesn’t have the support.
Applications that don’t require the feature typically then fall back to some other implementation, e.g. using vertex shaders instead of mesh shaders or using screen-space reflections instead of ray-traced reflections. If there is a bug in the application code that uses the feature, which makes it crash or return incorrect results, disabling the feature allows testing without the feature enabled. If, for example, a game crashes in some scenarios but works correctly after activating “Disable raytracing support” experiments, we can suspect the crash happens somewhere in the code that uses raytracing.
Disable low precision support
Disables support for 16-bit floating point numbers (half-floats) in shaders when used as minimum precision numbers. Minimum precision numbers in HLSL, like min16float type, allow declaring variables where 16-bit precision is sufficient, while the shader compiler is free to use full 32-bit precision (single precision float) if half-floats are not supported in some operation or if it would yield better performance. With this experiment activated, minimum precision numbers (D3D12_FEATURE_DATA_D3D12_OPTIONS::MinPrecisionSupport) are not supported and such numbers in shaders fall back to using the full 32-bit precision.
Using half-floats in shaders can improve performance in some cases due to faster calculations and smaller storage requirements, but it can also be a source of bugs. A 16-bit floating-point number retains only around 3 decimal digits of precision, can represent integer numbers exactly only up to 2048, and has a maximum value of 65504, above which it becomes infinity. This may be enough for calculations on HDR colors or normal vectors, but it is not sufficient to operate on vertex positions and many other types of data. It is very easy to exceed the maximum in the intermediate values used in calculations, e.g. in dot product of two vectors.
If activating this experiment fixes the problem of seeing incorrect results of the calculations in shaders, NaN or INF values, then likely the shader should be modified to use full precision (float) not low precision (min16float) in some places. It may also indicate a bug in the shader compiler, although less likely.
Disable native 16-bit type support
This experiment disables support for explicit 16-bit data types in shaders (D3D12_FEATURE_DATA_D3D12_OPTIONS4::Native16BitShaderOpsSupported) available in Shader Model 6.2, like type float16_t. When the experiment is activated, applications cannot use shaders that utilize native 16-bit types, and they should fall back to some implementation that use full precision numbers.
If activating this experiment fixes a bug, it may indicate a bug in the 16-bit version of the shader. Possibly, the precision or range of 16-bit numbers is insufficient for some calculations. It may also indicate a bug in the shader compiler, although less likely.
Disable AMD vendor extensions
Activating this experiment disables support for custom AMD extensions to the graphics APIs. In DirectX 12 it means extensions available through AMD GPU Services (AGS) library (AGSDX12ReturnedParams::ExtensionsSupported) are returned as unsupported. In Vulkan, it means VK_AMD_ and VK_AMDX_-prefixed device extensions are not available.
If an application makes use of such custom vendor extensions, this experiment can help with debugging. When the bug is fixed after activating this experiment, it indicates that the problem may be in the incorrect use of one of these extensions.
Disable compute queue support
When this experiment is activated, the Vulkan implementation does not expose compute-only queues. It means that for the queue family with QUEUE_COMPUTE_BIT but not QUEUE_GRAPHICS_BIT set, queueCount = 0, as if the GPU did not support asynchronous compute queue. Vulkan applications should typically be prepared for that and fall back to an implementation that executes its workload on the graphics queue only.
In DirectX 12 there is no way to expose the lack of support for asynchronous compute queue. When the experiment is activated, the GPU executes all commands submitted to compute queues on the graphics queue, serialized with the graphics workload.
This experiment can be used for debugging problems with asynchronous compute. If activating it fixes the bug, it may indicate a problem with synchronization or accessing resources shared between 3D workload (draw calls) executed on the graphics queue and compute dispatches intended to run in parallel in the compute queue.
Disable copy queue support
Activating this experiment for DirectX 12 makes all copy commands submitted to the copy queue executing on the graphics queue instead, which can help in debugging synchronization issues with workloads intended to run in parallel on multiple queues.
Experiments in this group allow disabling or controlling shader compiler behavior and other parts of the graphics driver which are enabled by default to improve the performance. While optimizations should not change the logic, in some cases disabling them may help in debugging various types of issues.
Disable floating-point optimizations
This experiment controls the behavior of the shader compiler. When activated, the compiler skips some of the optimizations typically done on the shader code related to calculations on floating-point numbers, like fusing MUL + ADD instructions into an FMA instruction. While in general optimizations should not change the compiler logic, they can change the precision of some operations, so the numerical results would not be bit-exact to the least significant bits with the unoptimized version.
If activating this experiment fixes a bug (e.g., a discrepancy between numerical results of a position-only versus full vertex shader), it may indicate that the application relies too much on the precision of the calculations. Changing some expressions in the shader code may help. It may also indicate a bug in the shader compiler, although less likely.
Disable shader compiler optimizations
When active, the experiment disables shader compiler optimizations which in result may result in non optimal shader code. This may cause shaders to take longer to run.
If enabling this experiment fixes a bug, it may indicate the bug is related to timing of individual draw calls, which may be a problem with synchronization, like a missing barrier. It may also indicate a bug in the shader compiler.
Disable barrier optimizations
This experiment disables some optimizations made by the driver at the level of synchronization and barriers between draw calls. By default, the driver optimizes command execution as much as possible, inserting fine-grained barriers to ensure correctness and maximum performance at the same time. For example, a pixel shader may need to wait for the pixel shader of the previous draw call to finish, but the vertex shader of that draw call can start executing earlier. This experiment disables some of these optimizations, which may decrease performance.
If activating this experiment fixes a bug, it may indicate a bug in synchronization, like a missing or incorrect barrier.
Disable acceleration structure optimizations
This experiment disables some of the optimizations made by the driver when building ray tracing acceleration structures, which may increase their size in memory and decrease the traversal performance in ray tracing. It should not change the logic.
If activating this experiment fixes a bug, it can indicate the application incorrectly handles synchronization between ray tracing dispatches (e.g. a missing or incorrect barrier) or incorrectly handles increased size required for acceleration structures or scratch buffers needed for their building. It may also indicate a bug in the driver, although less likely.
Force shader wave size
AMD RDNA architecture supports 32 or 64 threads per wave. Every shader is compiled in one of these modes (32 or 64 threads per wave), while the decision is made by the shader compiler based on some heuristics with the goal of reaching maximum performance. This experiment allows enforcing specific mode of shader compilation for a specific shader stage (vertex, hull, domain, geometry, pixel, compute, mesh shader) whenever possible. This should not change the logic, but it can impact performance.
If a shader uses explicit wave functions (called subgroup functions in Vulkan), like WaveReadLaneFirst, and toggling this experiment fixes a bug, it can indicate the shader relies on a specific wave size to work correctly, which should not be the case. It may also indicate a bug in the shader compiler, although less likely.
The experiment may also be used to compare the performance of a draw call executing the same shader with different wave sizes. If profiling (e.g. using RGP) shows that the wave size selected by the driver is not optimal for a specific shader, you can use [WaveSize()] attribute from Shader Model 6.6 to prepare an optimized version of the shader with explicit wave size to be used when possible.
Disable raytracing shader inlining
DXR shaders on AMD GPUs can be compiled in one of two modes. It can be observed in tools like RGP or RRA as:
The decision is made by the shader compiler based on some heuristics with the goal of reaching maximum performance. It should not change the logic. This experiment forces the compiler always choose the Indirect mode.
If activating this experiment shortens the time it takes for a game to launch and load while it creates Pipeline State Objects (PSOs), it indicates that the creation of ray tracing PSOs takes significant amount of this time. It is worth doing it in the background and creating many PSOs in parallel on multiple threads.
If activating this experiment fixes a bug: a CPU crash or hang on PSO creation, GPU crash on shader execution, or incorrect results returned, it indicates a bug in the shader compiler.
Disable shader cache
Shader compilation happens in two stages:
This experiment disables the shader cache implemented by the driver. It should not change the logic, but it can impact the duration of PSO creation.
If activating this experiment makes the application launch and load much longer, it can indicate the creation of the application PSOs take significant time that is optimized thanks to the cache, but new users would experience it the first time they launch the application. Activating this experiment can help achieve more reliable measurement of the application startup time with cold shader caches.
Experiments in this group generally offer extra safety features that can decrease performance but can make the application more correct and stable. If activating a safety feature improves the application’s stability it could hint on the type of error in the code which makes the application unstable.
Disable depth-stencil texture compression
GPUs utilize internal compression formats for textures. This should not be confused with general data compression file formats (like ZIP) or algorithms (like Deflate), or with explicit block-compressed texture pixel formats (like BC6, ASTC). Internal compression formats are lossless, opaque to the developer, and typically increase rather than decrease texture sizes in memory (a space is needed for additional metadata), in favor of increased performance when using it. Such compression is typically used on render-target and depth-stencil textures. A decision whether a texture should be compressed is made by the driver based on some heuristics with the goal of achieving maximum performance. It can be observed in RGP, on the Render/depth targets tab, DCC column.
Compressed textures may be more sensitive to incorrect data. If a texture is created in place where the memory may contain garbage data (e.g. created as placed in a larger memory heap where another resource existed before, or aliasing memory with some other resource used in a disjoint period throughout each render frame), it must be correctly initialized with either Clear, Copy, or DiscardResource operation, so that compression metadata are valid. Otherwise, the results are undefined. Overwriting the whole texture using a shader as a render target, depth-stencil, or UAV doesn’t count as proper initialization. In such case, visual artifacts can remain, or it can even lead to a GPU crash.
This experiment disables internal compression of depth-stencil textures. If activating it fixes a bug related to incorrect rendering, it can indicate missing or incorrect initialization of a depth-stencil texture.
Zero unbound descriptors
This experiment initializes unbound descriptors with zeros. If enabling it fixes a bug, it can indicate that the application may be accessing an unbound descriptor table.
Thread-safe command buffer allocator
Command buffer allocator objects are not thread-safe and should only be accessed from one thread at a time. When an application uses parallel recording of command buffers or multiple threads, it typically uses a separate command allocator per thread.
This experiment makes command allocators thread-safe, synchronized internally. If activating it fixes a bug, it can indicate the bug is related to synchronization between threads that use command allocators and command buffers for rendering.
Force structured buffers as raw
A structured buffer defines a stride, which is the number of bytes needed for a single instance of the structure, or a step to take with a pointer to move to the next structure instance. This parameter is passed when creating a Shader Resource View (SRV) descriptor for a structured buffer, but the structure of specific size is also declared in the shader code for that structured buffer to be bound to the specific shader resource slot. These two should match. If they do not match, the result is undefined and may differ between different GPUs.
This experiment forces the GPU to use the stride from the shader instead of the descriptor. If activating it fixes a bug, it may indicate the bug is about incorrect declaration of the structured buffer in the application code or in the shader code, or accidentally using a raw buffer instead of a structured buffer.
Vertical synchronization
Vertical synchronization (V-sync) is a setting commonly offered by games to control the behavior of presenting frames on the screen.
When off, frames are presented as soon as they are ready (when rendering is finished). It typically increases the number of frames per second (FPS), makes the GPU busier, up to 100% (if the game is not bound by its CPU workload), but it can expose an unpleasant visual effect on the screen known as tearing. This mode is good for testing the system and the game under maximum load, and for performance measurements.
When on, new frames are presented only when the monitor is ready to present them. FPS is then limited to the refresh rate of the monitor (60 Hz on typical monitors), GPU load is lower, battery usage is lower, as the game is blocked and waits until a subsequent frame can be rendered and presented. Tearing effect is not present, and so this mode is good for normal gaming.
V-sync is typically controlled by the application. This experiment allows to override it and force it to be on or off. This allows performing tests with various purposes on applications that don’t offer control over V-sync. For example, if forcing it on fixes a bug, it may indicate the bug is sensitive to timing of draw calls and render passes, which may be caused by incorrect CPU-GPU synchronization of render frames, command buffer submission, Present call, etc. If V-sync forced on fixes the problem with the whole system crashing or shutting down, it may indicate a problem with GPU or CPU overheating.
Driver Experiments is a new tool that allows low-level control of the AMD Adrenalin driver. It is helpful for game developers and other graphics developers in debugging their applications if they crash or work incorrectly on an AMD GPU.
This page is just a blog post announcing public release of the first version of the tool. For the most up-to-date information, including supported hardware and software, the list and description of all the experiments currently available, please check the RDP product page on GPUOpen.com and the RDP documentation, “Driver Experiments” chapter. If you have ideas for new experiments worth adding or any suggestions to the tool in general, you can open “Issue” tickets in the RDP repository on GitHub.