Post-mortem GPU crash debugging with LLMs
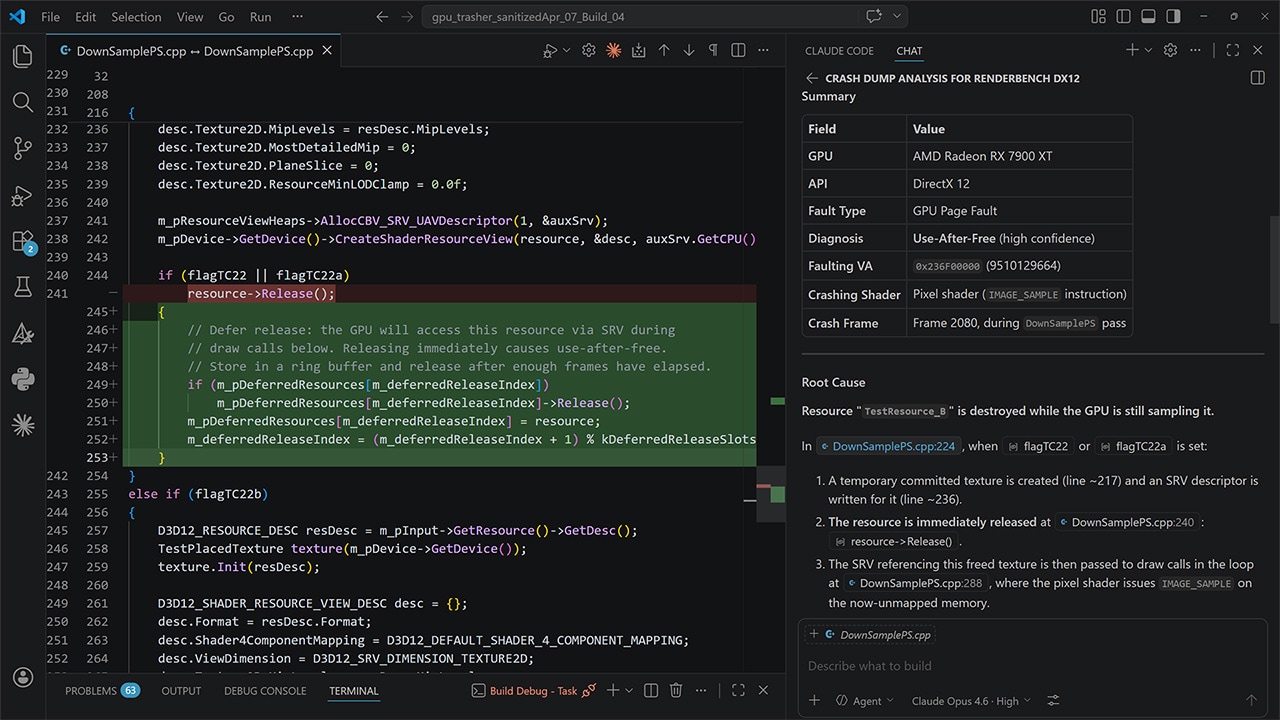
The new AMD RGD MCP Server connects LLM agents to AMD's GPU crash analysis pipeline, turning a single prompt into root-cause analysis and source-code fix suggestions.
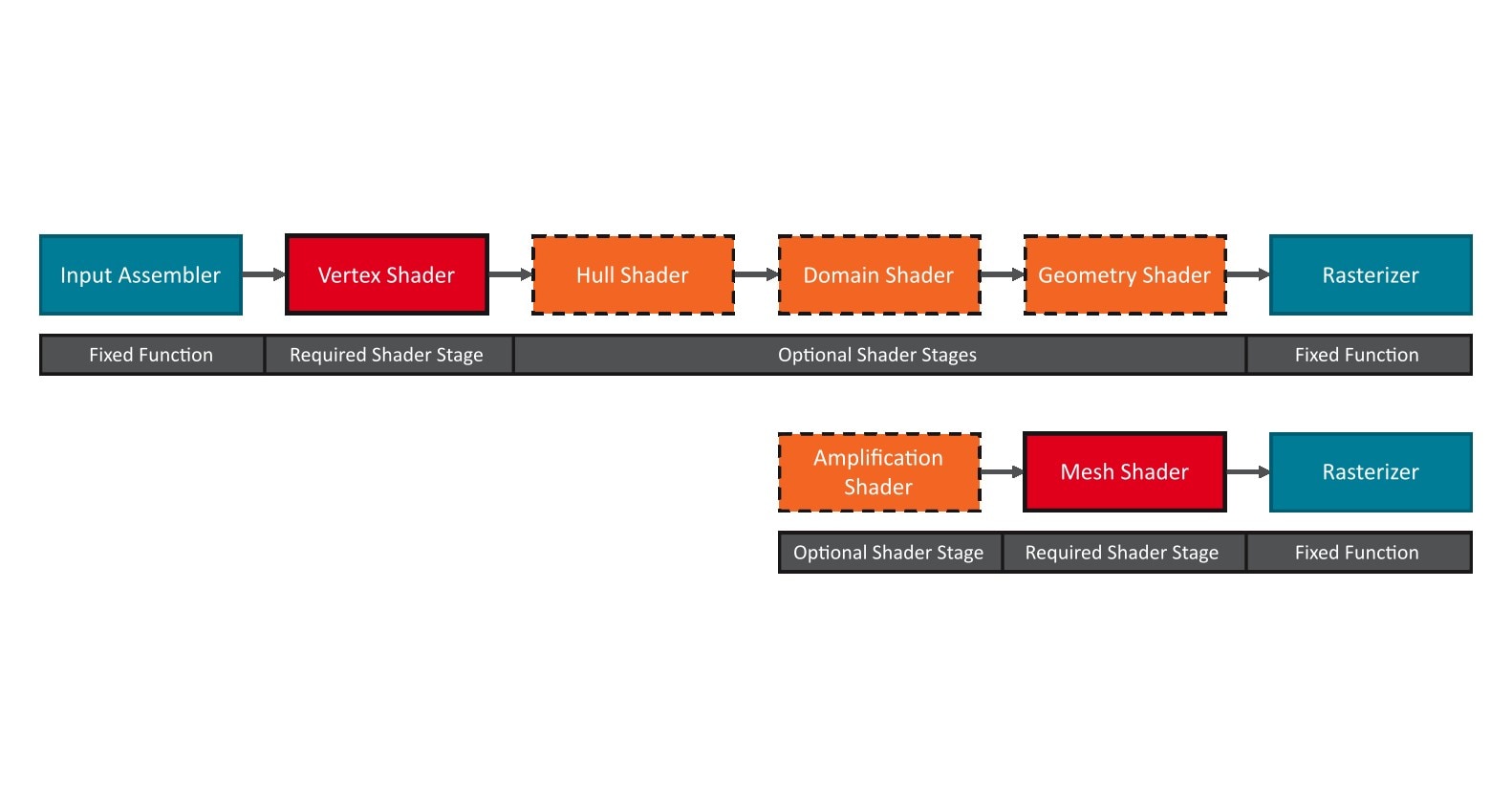
The new Wave Matrix Multiply Accumulate (WMMA) instructions added in HLSL Shader Model 6.8 allow shader developers to accelerate Generalized Matrix Multiplication (GEMM) matrix operations of the form:
WMMA instructions task all threads in a wave to collaboratively perform a matrix-multiply operation with higher efficiency and throughput than previously achievable using SM 6.7 or earlier instructions.
GEMM operations have many uses in in signal-processing, physics simulations, machine learning, and computer vision.
Some examples include:
For more information on WMMA, see: