Tips and Tricks
Start Small
Don’t try jumping straight into the deep end on this one! The Microsoft DirectX® 12 Work Graphs specification is large, complex, and nuanced. I strongly encourage you to build sandboxes and experiment with features to ensure that your mental model matches the GPUs behavior before you attempt to exercise those features in the wild.
The tools surrounding Work Graphs are also still in development. Work Graphs support for PIX is coming along very nicely, but there are still use cases that will break it. At this point, if you attempt to do things of significant complexity with Work Graphs… you may end up needing to build your own infrastructure to grab values from the GPU, and/or some additional tooling to mass-process or visualize those results.
Referencing Work Graph Entrypoints by Name instead of by Index
In previous examples, we looked at selecting the desired Entrypoint as an index supplied when generating the D3D12_DISPATCH_GRAPH_DESC. This index-based referencing can be quite confusing… especially in an iterative environment where the index-based locations of specific entrypoints may change over time, or where multiple developers are working on a given piece of content and only one of them really knows which entrypoint was originally intended.
One solution to this problem is building a map from Entrypoint name to Entrypoint index. You can then wrap your DispatchGraph invocations such that you specify the name of your desired Entrypoints and look up the appropriate indices on-demand. This will improve collaboration and scalability.
Building this map is straightforward. Here’s an example using commonly available types from the C++ STL:
Copied!
std::map<std::wstring, UINT> BuildEntrypointIndices(ID3D12StateObject* pStateObject, std::wstring programName)
{
std::map<std::wstring, UINT> EntrypointIndices;
ID3D12WorkGraphProperties* pWorkGraphProperties;
pStateObject->QueryInterface(IID_PPV_ARGS(&pWorkGraphProperties));
UINT WGIndex = pWorkGraphProperties->GetWorkGraphIndex(programName.c_str());
UINT NumEntrypoints = pWorkGraphProperties->GetNumEntrypoints(WGIndex);
for (UINT EntrypointIndex = 0; EntrypointIndex < NumEntrypoints; EntrypointIndex++)
{
D3D12_NODE_ID ID = pWorkGraphProperties->GetEntrypointID(WGIndex, EntrypointIndex);
EntrypointIndices.insert({ ID.Name, EntrypointIndex });
}
pWorkGraphProperties->Release();
return EntrypointIndices;
}
Use SV_DispatchGrid sparingly
Using SV_DispatchGrid comes with a cost. If you know that the common case has a fixed size, it can be beneficial to split a node into the common case and hard-code the dispatch size, and a general case which sets the dispatch size as needed. Fortunately, you can use the same record type here, as by specifying [NodeDispatchGrid(x,y,z)] the SV_DispatchGrid entry simply gets ignored. See below for how to combine this with MaxRecordsSharedWith.
Watch where you Stomp
The most difficult-to-diagnose category of issue that I have personally run into during my Work Graphs misadventures have ultimately been memory stomps… but the memory that I’m stomping was allocated by the driver instead of by the user. Let’s talk a little about how that has happened to me, and how you might be able to recognize it if it’s happening to you.
In the section on Recursion, we discussed the API-defined limit on how deep the execution of Work Graph nodes can proceed (32); I think about this as the Work Graph “depth ceiling.” In that discussion, we talked about how the API tries to help you detect and avoid errors caused by exceeding this ceiling… but there are some situations where it simply can’t do so. There are other ceilings that exist in the Work Graphs specification; the one I have needed to interact with most frequently is the ceiling on [MaxRecords()].
From Microsoft’s DirectX 12 Work Graphs specification…
There is a limit on output record storage that is a function of the following variables:
…
Broadcasting and Coalescing launch nodes:
Maxrecords <= 256
…
Thread launch node:
Maxrecords <= 8
Exceeding declared values of these kinds of limiters usually ends in a memory stomp. Sometimes that stomp is gracious, and you get a hung GPU. Other times, you are not so lucky! If you ever find yourself staring at your screen thinking “this is literally impossible”, chances are good you’ve hit one of these.
As a concrete example, one of the more complex efforts I have undertaken with Work Graphs ported an existing algorithm from a series of Compute Shaders into a single Work Graph. During my initial passes at understanding that algorithm, I didn’t pay enough attention to how the data structures that algorithm consumed were generated; as a result, I failed to understand a critical nuance of interacting with that data structure. Eventually, I had a semi-functional Work Graph that went completely haywire on specific sets of inputs.
When I finally started to understand what was happening, I was staring at values I had dumped from the GPU back to the CPU. One of the values I had dumped was a thread-local variable that existed “on the stack” in one of my Work Graph nodes. Five lines before dumping the value of that variable back to the CPU, I assigned the variable a hard-coded value of 0x10. By the time that value reached the CPU, it was no longer 0x10 (“this is literally impossible”). I had a memory stomp.
That particular error was caused by inadvertently calling OutputComplete() on a larger number of records than was specified in [MaxRecords()] (which itself was already at the ceiling of 256 for a "coalescing" node). This happened because I decided whether to produce an Output Record by interacting with the data structure that I had failed to fully understand. No element of the compiler, runtime, validation layer, or execution context was able to warn me that this had occurred… and the subsequent debugging effort devolved into exhaustively testing everything. If you ever find yourself staring at something thinking “this is literally impossible”, I hope this story comes to mind and saves you some time!
As a result of that specific example, I would also encourage you to take your first pass over new Work Graph implementations – and especially ports of existing functionality that you may not fully understand – by setting absolutely everything to [MaxRecords(256)] (or [MaxRecords(8)] if you’re in a "Thread"-launch node) whenever possible. Once the graph works, you can start dialling in the correct limiters to use in a way that provides immediate feedback; if you change the value and things go haywire, you know where to look!
Using [MaxRecordsSharedWith(n)]
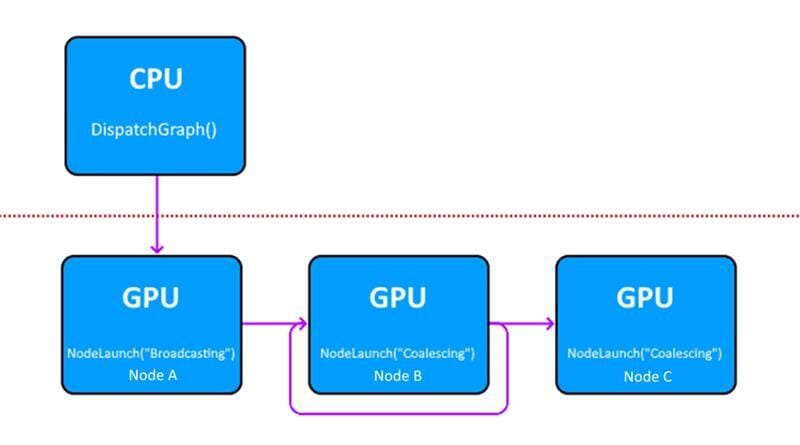
Consider the following graph structure:
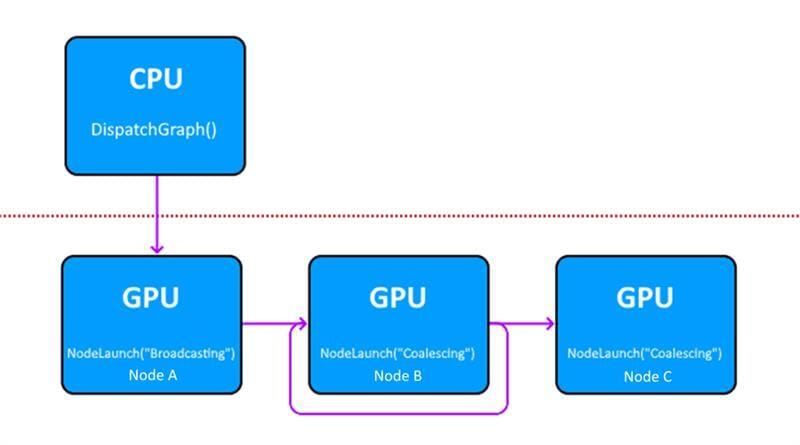
In this Work Graph, Node B can output records for two different nodes: Node B (recursively), or Node C. As we’ve already seen, the declaration for Node B must then contain multiple NodeOutput<> parameters. Each of those parameters must then be decorated with a maximum number of output records:
Copied!
[Shader("node")]
[NodeLaunch("coalescing")]
[NumThreads(32, 1, 1)]
void NodeB(
uint GroupIndex : SV_GroupIndex,
[MaxRecords(32)] GroupNodeInputRecords<NodeBInputRecord> inputData,
[MaxRecords(32)] NodeOutput<NodeBInputRecord> NodeB,
[MaxRecords(32)] NodeOutput<NodeCInputRecord> NodeC
)
But what if I told you that a single input to Node B can never output to both Node B and Node C simultaneously? What if I told you that Node B must choose one or the other? Under this precondition, we’ve declared 64 maximum output records… even though we only needed 32. The [MaxRecordsSharedWith()] attribute represents a cleaner and more scalable solution for this exact situation.
Copied!
[Shader("node")]
[NodeLaunch("coalescing")]
[NumThreads(32, 1, 1)]
void NodeB(
uint GroupIndex : SV_GroupIndex,
[MaxRecords(32)] GroupNodeInputRecords<NodeBInputRecord> inputData,
[MaxRecords(32)] NodeOutput<NodeBInputRecord> NodeB,
[MaxRecordsSharedWith(NodeB)] NodeOutput<NodeCInputRecord> NodeC
)
While the possible reductions in memory consumption are always valuable… if a node starts running up against the “MaxRecords ceiling” described in the section on Watch where you Stomp (or against the related ceilings on MaxOutputSize or SharedMemorySize), identifying opportunities to leverage this functionality can become critical to success!
Packing Records
Much like in many other GPU development contexts, packing and unpacking the data in your records such that those records consume less memory while they aren’t actively being used will produce performance savings. I’d encourage you to get the algorithm fully functional before you start packing the records, though!
More information on Work Graphs
Learn more here:
Downloads:
More Work Graphs content on GPUOpen:
Disclaimers
Links to third-party sites are provided for convenience and unless explicitly stated, AMD is not responsible for the contents of such linked sites, and no endorsement is implied. GD-98
Microsoft is a registered trademark of Microsoft Corporation in the US and/or other countries. Other product names used in this publication are for identification purposes only and may be trademarks of their respective owners.
DirectX is a registered trademark of Microsoft Corporation in the US and/or other countries.