




Application portability with HIP – AMD lab notes
This blog discusses various ROCm tools developers can leverage to port existing applications from CUDA to HIP.
C++17 parallel algorithms and HIPSTDPAR – AMD lab notes
This post discusses how to leverage C++17 parallel algorithms on AMD GPUs with HIPSTDPAR
Affinity part 2 – System topology and controlling affinity – AMD lab notes
This second part introduces common tools to understand the topology of your system and to control affinity for different applications
Affinity part 1 – Affinity, placement, and order – AMD lab notes
This first part introduces the concept of affinity and why its important for achieving better performance on AMD GPU nodes
Sparse matrix vector multiplication – part 1 – AMD lab notes
Sparse matrix vector multiplication (SpMV) is a core computational kernel of nearly every implicit sparse linear algebra solver. This is the first post in the series covering SpMV.
Jacobi Solver with HIP and OpenMP offloading – AMD lab notes
In this blog, we explore GPU offloading using HIP and OpenMP target directives and discuss their relative merits in terms of implementation efforts and performance.
Creating a PyTorch/TensorFlow Code Environment on AMD GPUs – AMD lab notes
The machine learning ecosystem is quickly exploding and this article is designed to assist data scientists/ML practitioners get their machine learning environments up and running on AMD GPUs.
Finite difference method – Laplacian part 4 – AMD lab notes
In the fourth and final part of Finite Difference Laplacian blog series we cover scaling studies and cache size limitations
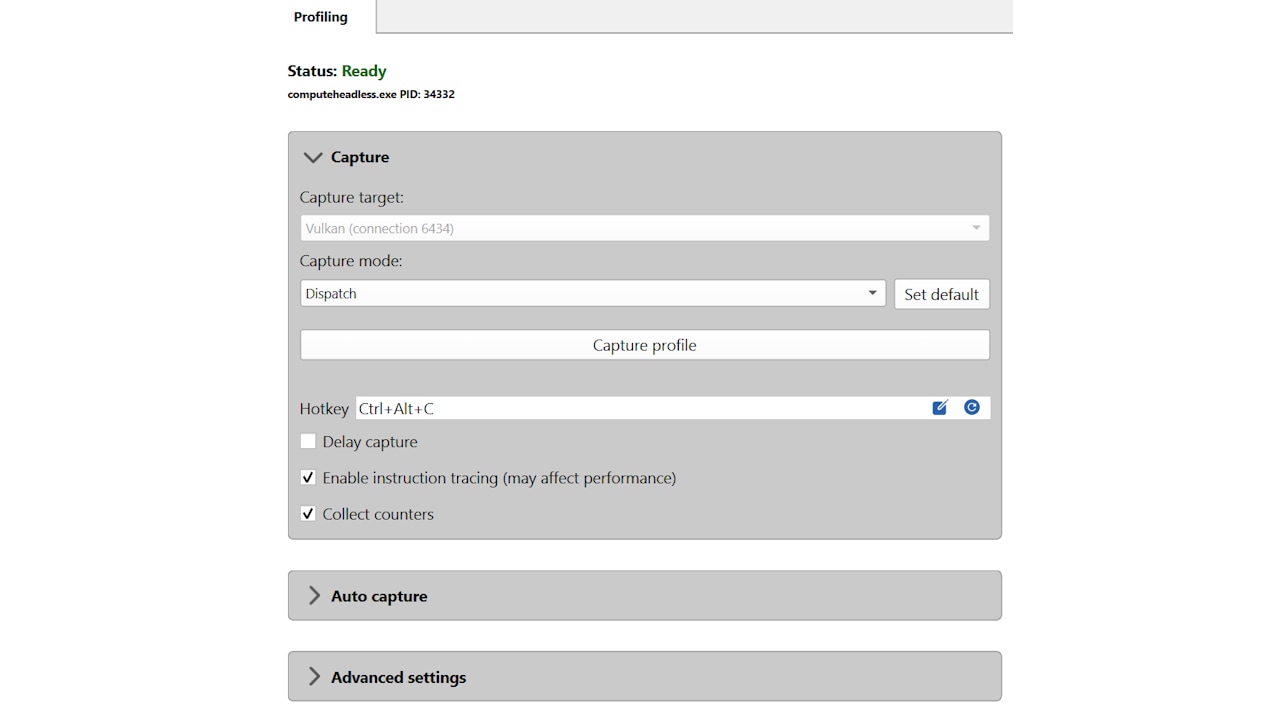
AMD Radeon™ GPU Profiler 2.4 adds support for AMD Radeon™ RX 9000 Series, pure-compute applications, DirectML applications (and more!)
Discover the latest Radeon GPU Profiler v2.4, now supporting Radeon RX 9000 Series GPUs and profiling for pure compute and DirectML applications. Enhance your optimization with improved ISA views and Work Graphs support.

Compute Shaders – Game Industry Conference 2021
This talk introduces compute shaders, explaining ideas from a software and hardware perspective, as well as considerations when writing compute shaders.

AMD FidelityFX™ Denoiser
AMD FidelityFX Denoiser is a set of denoising compute shaders which remove artefacts from reflection and shadow rendering.

Optimize Your Engine Using Compute
This talk by AMD’s Lou Kramer at 4C in 2018 discusses optimising your engine using compute.