TressFX
The TressFX library is AMD’s hair/fur rendering and simulation technology. TressFX is designed to use the GPU to simulate and render high-quality, realistic hair and fur.

Before we can start working on any kind of optimization, we must have a way to measure the performance in a consistent way and then to drill down and understand the implications.
We do have a benchmark mode in the Total War games, which can reliably reproduce the same frames over and over. We also have a console with lots of dev commands, including one which captures all the device and rendering calls in a frame and measure them both on CPU and GPU.
Then we use a small ruby script to convert this data to chrome timeline format which can be displayed in chrome://tracing
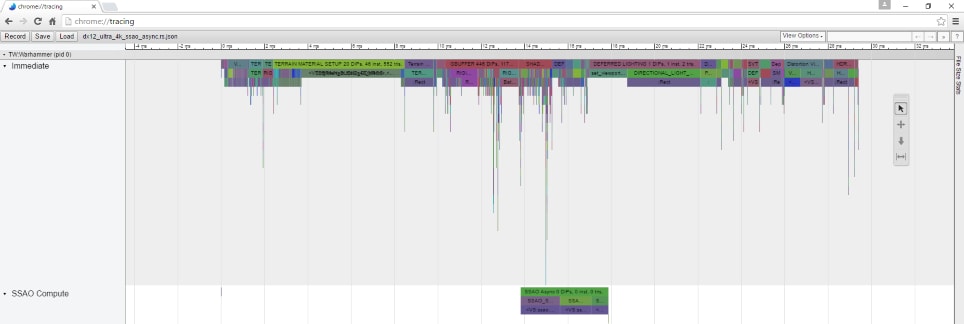
This is how a typical scene in Total War: Warhammer looks like rendered at 4K. We use the timeline view first to find hotspots, then to validate our improvements by comparing results against previous captures we take with our internal tools.
One of our most important tools in optimization was the shader analyser tool in CodeXL (and formerly GPUPerfStudio). The tool gives us information about register usage for the shaders used. I will walk you through the process of optimizing the pixel shader which combines the 8 layers of a terrain tiles. After running the shader through the analyser, this was our starting point:

Let me explain this a bit.
As we’re not using any additional LDS (Local Data Share) in our pixel shaders (beyond that used for our interpolants), the two resources that we care most about are SGPRs (Scalar General Purpose Register) and VGPRs (Vector General Purpose Register). From the view of a single thread (or a single pixel in this case) both types of register just contain a single 32-bit value. However, at the hardware-level GCN works on groups of 64 threads called wavefronts. From the point of view of a wavefront SGPRs are a single 32-bit values that is shared across all threads in the same wavefront. Conversely, VGPRs have a unique 32-bit value for each thread in the wavefront. One way to think of it is that any values that are constant across a group of 64 threads, for example the descriptors for your textures, can be stored in SGPRs while values that are (or have the potential to be) unique to each thread are stored in VGPRs.
From the point of view of a single thread each of the vector registers hold a single value. 256 VGPRs can mean 64 float4, 128 float2, 256 float or any combination of these. For example, if we sample a texture, but only use its RGB components and not its alpha channel, it will take up 3 VGPRs. Let’s do some math: we want to blend 8 terrain layers. Each layer has a diffuse, a normal and a spec/gloss texture. We use all 4 channels of the diffuse texture, 2 channels of the normal texture and 2 channels of the spec/gloss texture. That’s 4+2+2 = 8 VGPRs per layer. Multiplied by 8 layers is 64 VGPRs. So we’ve already used up a quarter of all the available registers in the SIMD and we haven’t even started to talk about other parts of the code, blend maps, height map, etc. Some registers can be reused, but as we’ll see soon it’s not as trivial as it seems.
The number of used registers is important, because modern hardware runs multiple wavefronts at the same time. You can think about this as processing multiple pixels at the same time. This means that one of the main limiting factors on the number of pixels we can have in flight is the number of registers the shaders require. If a single SIMD in the hardware has 256 VGPRs and a shader is using 200 of them for example, the GPU can work only on one wavefront at a time. After the first wavefront is launched on a SIMD it leaves 56 registers unused, which is not enough to accommodate another wavefront running the same shader. If it’s using 110 VGPRs, two wavefronts can run at the same time (112+112=224 and 32 registers remain unused). If the shader uses only 24 or less VGPRs, the hardware can run 10 wavefronts on a SIMD at the same time. 10 concurrent wavefronts is the current maximum for Fiji GPUs, such as the Radeon® Fury X. This limit is hard wired.
Back to the terrain shader, it was using 104 VGPRs. This means at most two wavefronts can be in flight at the same time, which is 128 pixels as we can have a maximum of 64 pixels in a single wavefront. Reducing the number or VGPRs can increase the number of wavefronts that can be active in parallel and can in some cases result in better performance.
So why are we using that many registers you may ask? We process the textures one by one, there is no need to keep all texture samples in registers all the time. Unfortunately, we don’t have control over how the shader compiler inside the driver translates DirectX Assembly to GCN ISA (which is the machine code for AMD GPUs), nor can we supply the GCN ISA directly (at least on PC). This means the shader compiler inside the driver has to deal with conflicting goals here. One goal as we’ve seen is keeping the register usage count as low as possible. Another goal is to hide as much latency from sampling textures as possible. Let me explain this quickly.
Accessing data from memory (from textures or buffers) can take a long time, but it can happen parallel to both Vector and Scalar ALU execution. As long as we don’t need to use the result of the memory load we can keep working on other instruction to give the memory subsystem enough time to fetch the data. The more computation we can put between issuing the load and using the results, the more likely we won’t have to wait for the load from memory. To achieve this the compiler attempts to issue the vector memory requests which will ultimately write to our VGPRs as early as possible. This means the VGPRs that will ultimately contain the data we read from memory are not available for use by other instructions until our memory access has completed. This will help hiding the latency of the memory request, but on the other hand it can increase register pressure in the shader, which can often lead to the shader requiring more registers. At this time there is no way controlling this behaviour directly.
The way we hinted the compiler to re-use certain registers was to wrap the layer blending inside a loop and use the loop semantic to ensure the compiler won’t unroll it. This is the result after this quick restructuring:

With this simple trick we managed to claim back 42 registers. Which meant double the wavefront occupancy for this shader. This change translated to an almost two-times speedup in rendering tiles.
For a quick introduction to profiling on the GPU, I recommend the following article:
https://mynameismjp.wordpress.com/2011/10/13/profiling-in-dx11-with-queries/
If you’d like to see some practical examples on hiding latency and GCN ISA:
https://bartwronski.com/2014/03/27/gcn-two-ways-of-latency-hiding-and-wave-occupancy/
You can find more information about the GCN architecture here: