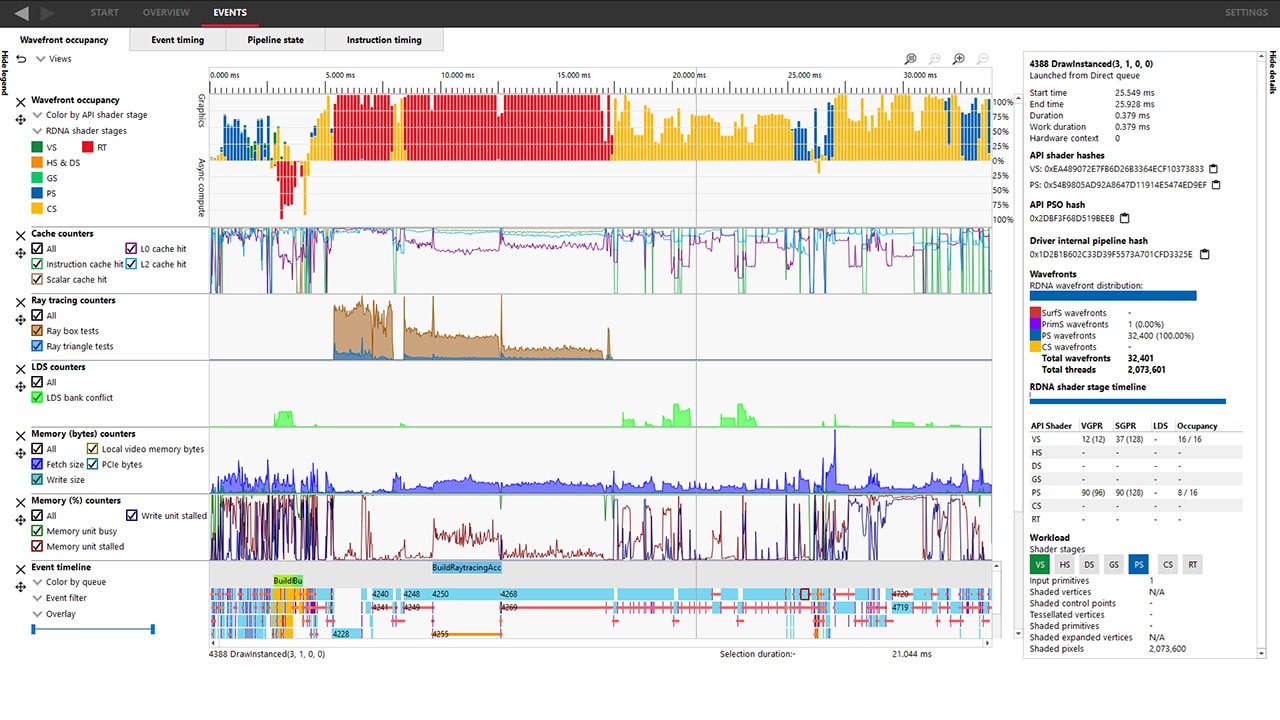
1 | 9 | ::::::: :: | label_basic_block_1: s_swappc_b64 s[2:3], s[2:3]
2 | 9 | ::::::: :: | s_andn2_b32 s0, s9, 0x3fff0000
3 | 9 | ::::::: :: | s_mov_b32 s1, s0
4 | 9 | ::::::: :: | s_mov_b32 s2, s10
5 | 9 | ::::::: :: | s_mov_b32 s3, s11
6 | 9 | ::::::: :: | s_mov_b32 s0, s8
7 | 9 | ::::::: :: | s_buffer_load_dwordx8 s[4:11], s[0:3], 0x00
8 | 9 | ::::::: :: | s_buffer_load_dwordx8 s[12:19], s[0:3], 0x20
9 | 9 | ::::::: :: | s_waitcnt lgkmcnt(0)
10 | 10 | ^ v:::::: :: | v_mul_f32 v0, s4, v4
11 | 11 | :^ v:::::: :: | v_mul_f32 v1, s8, v4
12 | 12 | ::^ v:::::: :: | v_mul_f32 v2, s12, v4
13 | 13 | :::^v:::::: :: | v_mul_f32 v3, s16, v4
14 | 12 | x::: v::::: :: | v_mac_f32 v0, s5, v5
15 | 12 | :x:: v::::: :: | v_mac_f32 v1, s9, v5
16 | 12 | ::x: v::::: :: | v_mac_f32 v2, s13, v5
17 | 12 | :::x v::::: :: | v_mac_f32 v3, s17, v5
18 | 11 | x::: v:::: :: | v_mac_f32 v0, s6, v6
19 | 11 | :x:: v:::: :: | v_mac_f32 v1, s10, v6
20 | 11 | ::x: v:::: :: | v_mac_f32 v2, s14, v6
21 | 11 | :::x v:::: :: | v_mac_f32 v3, s18, v6
22 | 10 | x::: v::: :: | v_mac_f32 v0, s7, v7
23 | 10 | :x:: v::: :: | v_mac_f32 v1, s11, v7
24 | 10 | ::x: v::: :: | v_mac_f32 v2, s15, v7
25 | 10 | :::x v::: :: | v_mac_f32 v3, s19, v7
26 | 9 | vvvv ::: :: | exp pos0, v0, v1, v2, v3
27 | 5 | ::: :: | s_buffer_load_dwordx4 s[4:7], s[0:3], 0x40
28 | 5 | ::: :: | s_buffer_load_dwordx4 s[8:11], s[0:3], 0x50
29 | 5 | ::: :: | s_buffer_load_dwordx4 s[0:3], s[0:3], 0x60
30 | 5 | ::: :: | s_waitcnt expcnt(0)
31 | 6 | ^ v:: :: | v_mul_f32 v0, s4, v8
32 | 7 | :^ v:: :: | v_mul_f32 v1, s8, v8
33 | 8 | ::^ v:: :: | v_mul_f32 v2, s0, v8
34 | 7 | x:: v: :: | v_mac_f32 v0, s5, v9
35 | 7 | :x: v: :: | v_mac_f32 v1, s9, v9
36 | 7 | ::x v: :: | v_mac_f32 v2, s1, v9
37 | 6 | x:: v :: | v_mac_f32 v0, s6, v10
38 | 6 | :x: v :: | v_mac_f32 v1, s10, v10
39 | 6 | ::x v :: | v_mac_f32 v2, s2, v10
40 | 5 | vvv :: | exp param0, v0, v1, v2, off
41 | 2 | vv | exp param1, v12, v13, off, off
Maximum # VGPR used 13, # VGPR allocated: 14