AMD FidelityFX™ Single Pass Downsampler (SPD)
AMD FidelityFX Single Pass Downsampler (SPD) provides an AMD RDNA™ architecture optimized solution for generating up to 12 MIP levels of a texture.
The ability to write code in assembly is essential to achieving the best performance for a GPU program. In a previous blog we described how to combine several languages in a single program using ROCm and Hsaco. This article explains how to produce Hsaco from assembly code and also takes a closer look at some new features of the GCN architecture. I’d like to thank Ilya Perminov of Luxsoft for co-authoring this blog post.
Programs written for GPUs should achieve the highest performance possible. Even carefully written ones, however, won’t always employ 100% of the GPU’s capabilities. Some reasons are the following:
Consider a program that uses one of GCN’s new features (source code is available on GitHub). Recent hardware architecture updates—DPP and DS Permute instructions—enable efficient data sharing between wavefront lanes. To become more familiar with the instruction set, review the GCN ISA Reference Guide.
Note: the assembler is currently experimental; some of syntax we describe may change.
Two new instructions, ds_permute_b32 and ds_bpermute_b32 , allow VGPR data to move between lanes on the basis of an index from another VGPR. These instructions use LDS hardware to route data between the 64 lanes, but they don’t write to LDS memory. The difference between them is what to index: the source-lane ID or the destination-lane ID. In other words, ds_permute_b32 says “put my lane data in lane i,” and ds_bpermute_b32 says “read data from lane i.” The GCN ISA Reference Guide provides a more formal description.
The test kernel is simple: read the initial data and indices from memory into GPRs, do the permutation in the GPRs and write the data back to memory. An analogous OpenCL kernel would have this form:
__kernel void hello_world(__global const uint * in, __global const uint * index, __global uint * out){ size_t i = get_global_id(0); out[i] = in[ index[i] ];}Formal HSA arguments are passed to a kernel using a special read-only memory segment called kernarg . Before a wavefront starts, the base address of the kernarg segment is written to an SGPR pair. The memory layout of variables in kernarg must employ the same order as the list of kernel formal arguments, starting at offset 0, with no padding between variables—except to honor the requirements of natural alignment and any align qualifier.
The example host program must create the kernarg segment and fill it with the buffer base addresses. The HSA host code might look like the following:
/** This is the host-side representation of the kernel arguments that the simplePermute kernel expects.*/struct simplePermute_args_t { uint32_t * in; uint32_t * index; uint32_t * out;};/** Allocate the kernel-argument buffer from the correct region.*/hsa_status_t status;simplePermute_args_t * args = NULL;status = hsa_memory_allocate(kernarg_region, sizeof(simplePermute_args_t), (void**)(&args));assert(HSA_STATUS_SUCCESS == status);aql->kernarg_address = args;/** Write the args directly to the kernargs buffer;* the code assumes that memory is already allocated for the* buffers that in_ptr, index_ptr and out_ptr point to*/args->in = in_ptr;args->index = index_ptr;args->out = out_ptr;The host program should also allocate memory for the in , index and out buffers. In the GitHub repository, all the run-time-related stuff is hidden in the Dispatch and Buffer classes, so the sample code looks much cleaner:
// Create Kernarg segmentif (!AllocateKernarg(3 * sizeof(void*))) { return false; }
// Create buffersBuffer *in, *index, *out;in = AllocateBuffer(size);index = AllocateBuffer(size);out = AllocateBuffer(size);
// Fill Kernarg memoryKernarg(in); // Add base pointer to “in” bufferKernarg(index); // Append base pointer to “index” bufferKernarg(out); // Append base pointer to “out” bufferTo launch a kernel in real hardware, the run time needs information about the kernel, such as
All this data resides in the amd_kernel_code_t structure. A full description of the structure is available in the AMDGPU-ABI specification. This is what it looks like in source code:
.hsa_code_object_version 2,0.hsa_code_object_isa 8, 0, 3, "AMD", "AMDGPU"
.text.p2align 8.amdgpu_hsa_kernel hello_world
hello_world:
.amd_kernel_code_tenable_sgpr_kernarg_segment_ptr = 1is_ptr64 = 1compute_pgm_rsrc1_vgprs = 1compute_pgm_rsrc1_sgprs = 0compute_pgm_rsrc2_user_sgpr = 2kernarg_segment_byte_size = 24wavefront_sgpr_count = 8workitem_vgpr_count = 5.end_amd_kernel_code_t
s_load_dwordx2 s[4:5], s[0:1], 0x10s_load_dwordx4 s[0:3], s[0:1], 0x00v_lshlrev_b32 v0, 2, v0s_waitcnt lgkmcnt(0)v_add_u32 v1, vcc, s2, v0v_mov_b32 v2, s3v_addc_u32 v2, vcc, v2, 0, vccv_add_u32 v3, vcc, s0, v0v_mov_b32 v4, s1v_addc_u32 v4, vcc, v4, 0, vccflat_load_dword v1, v[1:2]flat_load_dword v2, v[3:4]s_waitcnt vmcnt(0) & lgkmcnt(0)v_lshlrev_b32 v1, 2, v1ds_bpermute_b32 v1, v1, v2v_add_u32 v3, vcc, s4, v0v_mov_b32 v2, s5v_addc_u32 v4, vcc, v2, 0, vccs_waitcnt lgkmcnt(0)flat_store_dword v[3:4], v1s_endpgmCurrently, a programmer must manually set all non-default values to provide the necessary information. Hopefully, this situation will change with new updates that bring automatic register counting and possibly a new syntax to fill that structure.
Before the start of every wavefront execution, the GPU sets up the register state on the basis of the enable_sgpr_* and enable_vgpr_* flags. VGPR v0 is always initialized with a work-item ID in the x dimension. Registers v1 and v2 can be initialized with work-item IDs in the y and z dimensions, respectively. Scalar GPRs can be initialized with a work-group ID and work-group count in each dimension, a dispatch ID, and pointers to kernarg , the aql packet, the aql queue, and so on. Again, the AMDGPU-ABI specification contains a full list in in the section on initial register state. For this example, a 64-bit base kernarg address will be stored in the s[0:1] registers (enable_sgpr_kernarg_segment_ptr = 1) , and the work-item thread ID will occupy v0 (by default). Below is the scheme showing initial state for our kernel.
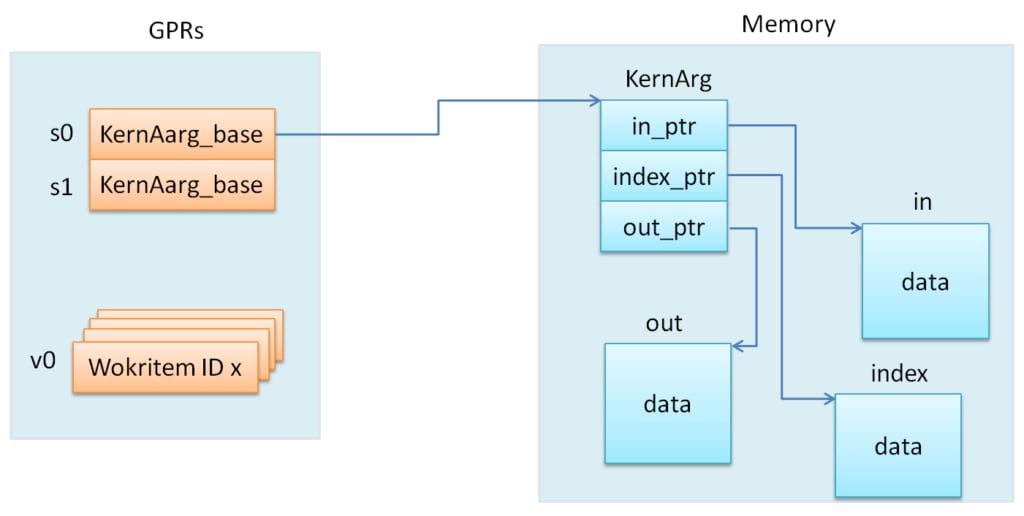
The next amd_kernel_code_t fields are obvious: is_ptr64 = 1 says we are in 64-bit mode, and kernarg_segment_byte_size = 24 describes the kernarg segment size. The GPR counting is less straightforward, however. The workitem_vgpr_count holds the number of vector registers that each work item uses, and wavefront_sgpr_count holds the number of scalar registers that a wavefront uses. The code above employs v0–v4 , so workitem_vgpr_count = 5 . But wavefront_sgpr_count = 8 even though the code only shows s0–s5 , since the special registers VCC , FLAT_SCRATCH and XNACK are physically stored as part of the wavefront’s SGPRs in the highest-numbered SGPRs. In this example, FLAT_SCRATCH and XNACK are disabled, so VCC has only two additional registers.
In current GCN3 hardware, VGPRs are allocated in groups of 4 registers and SGPRs in groups of 16. Previous generations (GCN1 and GCN2) have a VGPR granularity of 4 registers and an SGPR granularity of 8 registers. The fields compute_pgm_rsrc1_*gprs contain a device-specific number for each register-block type to allocate for a wavefront. As we said previously, future updates may enable automatic counting, but for now you can use following formulas for all three GCN GPU generations:
compute_pgm_rsrc1_vgprs = (workitem_vgpr_count-1)/4
compute_pgm_rsrc1_sgprs = (wavefront_sgpr_count-1)/8Now consider the corresponding assembly:
// initial state:// s[0:1] - kernarg base address// v0 - workitem id
s_load_dwordx2 s[4:5], s[0:1], 0x10 // load out_ptr into s[4:5] from kernargs_load_dwordx4 s[0:3], s[0:1], 0x00 // load in_ptr into s[0:1] and index_ptr into s[2:3] from kernargv_lshlrev_b32 v0, 2, v0 // v0 *= 4;s_waitcnt lgkmcnt(0) // wait for memory reads to finish
// compute address of corresponding element of index buffer// i.e. v[1:2] = &index[workitem_id]v_add_u32 v1, vcc, s2, v0v_mov_b32 v2, s3v_addc_u32 v2, vcc, v2, 0, vcc
// compute address of corresponding element of in buffer// i.e. v[3:4] = &in[workitem_id]v_add_u32 v3, vcc, s0, v0v_mov_b32 v4, s1v_addc_u32 v4, vcc, v4, 0, vcc
flat_load_dword v1, v[1:2] // load index[workitem_id] into v1flat_load_dword v2, v[3:4] // load in[workitem_id] into v2s_waitcnt vmcnt(0) & lgkmcnt(0) // wait for memory reads to finish
// v1 *= 4; ds_bpermute_b32 uses byte offset and registers are dwordsv_lshlrev_b32 v1, 2, v1
// perform permutation// temp[thread_id] = v2// v1 = temp[v1]// effectively we got v1 = in[index[thread_id]]ds_bpermute_b32 v1, v1, v2
// compute address of corresponding element of out buffer// i.e. v[3:4] = &out[workitem_id]v_add_u32 v3, vcc, s4, v0v_mov_b32 v2, s5v_addc_u32 v4, vcc, v2, 0, vcc
s_waitcnt lgkmcnt(0) // wait for permutation to finish
// store final value in out buffer, i.e. out[workitem_id] = v1flat_store_dword v[3:4], v1
s_endpgmThe next step is to produce a Hsaco from the ASM source. LLVM has added support for the AMDGCN assembler, so you can use Clang to do all the necessary magic:
clang -x assembler -target amdgcn--amdhsa -mcpu=fiji -c -o test.o asm_source.s
clang -target amdgcn--amdhsa test.o -o test.coThe first command assembles an object file from the assembly source, and the second one links everything (you could have multiple source files) into a Hsaco. Now, you can load and run kernels from that Hsaco in a program. The GitHub examples use Cmake to automatically compile ASM sources.
In a future post we will cover DPP, another GCN cross-lane feature that allows vector instructions to grab operands from a neighboring lane.
Ilya Perminov is a software engineer at Luxoft. He earned his PhD in computer graphics in 2014 from ITMO University in Saint Petersburg, Russia. Ilya interned at AMD in 2015, during which time he worked on graphics-workload tracing and performance modeling. His research interests include real-time rendering techniques, GPUs architecture and GPGPU.
amd_kernel_code_t 
The AMD GPU Services (AGS) library provides software developers with the ability to query AMD GPU software and hardware state information that is not normally available through standard operating systems or graphics APIs.

An explanation of how GCN hardware coalesces memory operations to minimize traffic throughout the memory hierarchy.

Cross-lane operations are an efficient way to share data between wavefront lanes. This article covers in detail the cross-lane features that GCN3 offers.