
Vulkan® Memory Allocator
VMA is our single-header, MIT-licensed, C++ library for easily and efficiently managing memory allocation for your Vulkan® games and applications.
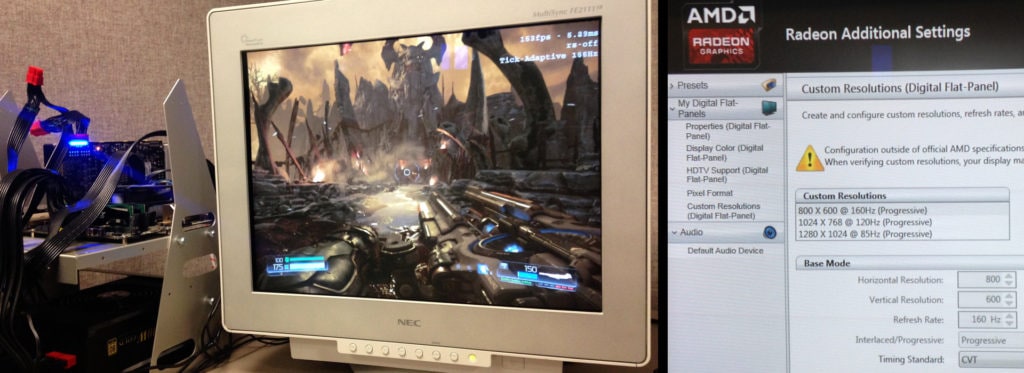
This post takes a look at some of the interesting bits of helping id Software with their DOOM® Vulkan® effort, from the perspective of AMD’s Game Engineering Team, and relaying critical tips which can help others working on Vulkan®.
DOOM has the right combination of a mixed Forward and Deferred graphics pipeline which makes it amenable to high frame rates when GPU-bound. Also DOOM has 4:3 aspect ratio support. I knew that Vulkan® would enable me to play this game at a V-Synced 160 Hz without missing frames on my CRT TV for the ultimate in low-latency no-jitter perfect-motion twitch experience. So I jumped on the opportunity to help make that happen, and got the ultimate reward, ability to play through the game in that configuration using a custom driver display setting on my Radeon™ Fury X based development box (photo above).
Thanks again to Billy Khan, Robert Duffy, and id Software for hosting us to help on-site, and to Axel Gneiting, Jean Geffroy, and Tiago Sousa, for making a stunning Vulkan® path in DOOM.
Axel Gneiting’s response in the DSOGaming DOOM Tech Interview highlights the key points:
“On the tools side there is very good Vulkan® support in RenderDoc now, which covers most of our debugging needs. We choose Vulkan®, because it allows us to support Windows® 7 and 8, which still have significant market share and would be excluded with DirectX® 12. On top of that Vulkan® has an extension mechanism that allows us to work very closely with GPU vendors to do very specific optimizations for each hardware.”
Various general purpose AMD Vulkan® extensions were quickly finished to enable specific optimizations for DOOM. This effort at AMD involved first working with id Software to understand their need, writing extension specs, getting prototype glslangValidator.exe support for those extensions for GLSL to SPIR-V translation (later sending a pull request to incorporate into the public tool), implementation from the shader compiler and driver teams, and finally testing efforts from the driver QA team.
Often we talk about how Vulkan® and DirectX® 12 are equally first class APIs in the AMD Driver Stack, and the best way to understand why is to look at how both are implemented in the driver. The graphics driver stack on Windows® is divided into three primary components:
The User-Mode Driver is implemented with 2 layers:
The other major part of this driver stack is the compiler pipeline which has the following layers:
Because DirectX® 12, Vulkan® and Mantle are all explicit APIs, they fit naturally together. Optimizations in the driver and compiler are shared across APIs. The primary area where Vulkan® diverges from DirectX® 12 is that Vulkan® officially supports extensions. It becomes possible to expose hardware features before they are common across vendors and reach the lowest common denominator which enables them to be re-introduced as core features in the APIs.
Working as an interface between developers and other teams inside AMD, my Vulkan® extension request list is heavily influenced by requests from game developers. All those developer twitter comments, notes in GDC presentations, emails, and more get collected and prioritized. The work to enable DOOM is the beginning for Vulkan®, in the background we are busy working on the next round of extensions and improvements.
For some developers, with Windows 7 support, Vulkan® offers the opportunity to move forward in engine design without having to be limited to technology that can be implemented in a Direct3D® 11 backwards compatibility path. For example with Vulkan®, it is possible to optimize by factoring out binding of Resources to just the start of each Command Buffer: “Bind Everything” as one Descriptor Set, use Push Constants to supply indexes when resource indexes need to be specialized per draw or dispatch (see the Vulkan® Fast Paths presentation). Likewise with Events, it is possible to avoid draining the GPU on dependent draws or dispatches, by interleaving independent work. Vulkan® provides the expressiveness to leverage the hardware in efficient ways.
For existing engines which have migrated from OpenGL® or Direct3D® 11 beginnings, the top items to get right to ensure optimal performance are as follows.
Covered in detail in the Vulkan® Device Memory post, an early step in any port to Vulkan® is setting up Resource allocation, making sure to get groups of smaller Resources “pooled” into larger allocations in the appropriate Memory Heap. This is also the opportunity to alias memory of Resources which are not used at the same time to reduce total DEVICE_LOCAL memory budget. Vulkan® vkAllocateMemory() allocations in the AMD driver on Windows® are WDDM Allocations, so it is important to limit the number of those and also avoid allocating at run-time after initialization. Since Fiji and Tonga GPUs, it is also possible to leverage the hardware Delta Color Compression by using the Graphics Queue to copy HOST_VISIBLE to DEVICE_LOCAL Images for non-block-compressed formats.
Getting multiple Command Buffers recording in parallel is the first step in ensuring a high-draw-count application stays GPU bound, and has a side effect of possibly lowering latency. Going parallel on the CPU enables DOOM to hit such high frame rates. Parallel Command Buffer recording is relatively straightforward, setup at least one Command Pool per parallel recording thread.
The advantage of Asynchronous Compute is that it enables utilizing the time that the GPU would otherwise be idle due to fixed-function hardware limits and cases where the application might otherwise be waiting for the GPU to drain for a dependent pass. Improvements in performance vary based on workload, but in DOOM it is common to see a 7% whole frame performance increase utilizing Async Compute around just 50% of the frame. The best place to start to incorporate Asynchronous Compute is when drawing geometry.
Planning for Asynchronous Compute is best done as early as possible. One of the things to design for early is VK_SHARING_MODE_EXCLUSIVE for Image Resources, which means only one Queue owns access to the Resource at any one time. This enables maintaining DCC on Render Targets and non-block-compressed Sampled Images uploaded using the Graphics Queue. I have seen a 3% whole frame gain enabling Exclusive Sharing on top of the gains of Asynchronous Compute. Using Exclusive Sharing requires the Image Barrier to be duplicated on both Queues to implement an exclusive ownership transfer. Best to plan and incorporate that into the game’s graphics abstraction/portability layer early, because it can be complex to retro-fit later.
This step involves opening GPUView and verifying the game with V-sync disabled is able to fully fill the GPU with work without pipeline bubbles to ensure Presentation is fully pipelined. On Windows® with the AMD driver it is best to Present from the Async Compute Queue. It is also important for latency to structure the game pipeline to run exclusively in the Graphics Queue and then transition the work for that frame exclusively to the Async Compute Queue all the way through Presentation, without ever switching back to the Graphics Queue to process more of the frame (as that would introduce substantial latency with 2 frames fighting for time on the same Queue).
The optimal path on Vulkan® for presentation starts with requesting a 2-deep swap chain to minimize latency when V-sync (or VK_PRESENT_MODE_FIFO_KHR) is selected. Make sure to place the vkAcquireNextImageKHR() call as late as possible in the frame because this call can block according to the Vulkan® spec. I would suggest splitting a command buffer such that the Acquire is only done right before recording the second part which first writes into the acquired Image. Only two Semaphores are required to hook up Presentation. The first is passed into the Acquire call, and set as the Wait Semaphore for the Command Buffer which Image Stores into the Acquired Image. The second is set as the Signal Semaphore for that same Command Buffer, and then is set as input into the vkQueuePresentKHR() call. Also remember that in Vulkan®, the spec allows the Acquire to return Image indexes in random order, so an application cannot assume round-robin order even with FIFO mode and a 2-deep swap chain (for example windowed presents can blit, enabling the same Image index to be ready and returned at the next Acquire).
As Vulkan® places much of what used to be driver work in the hands of the developer, it is important to test on each hardware vendor as early as possible during development. Also it is quite important to actively test on the different major chipsets and memory configurations. For instance make sure to test using 2 GB GPUs if that is the min spec for the title. For AMD GPUs it is best to test on at least both 2nd generation (e.g. R9 390) and 3rd generation (e.g. Radeon™ 380 and Fury X), as well as latest 4th generation (e.g. Radeon™ RX 480) GCN parts.

















