Meet AMD FSR™ Technologies
Integrate our "Redstone" neural rendering technologies to take your game to new levels of fidelity and performance.

Integrate our "Redstone" neural rendering technologies to take your game to new levels of fidelity and performance.
Integrate our "Redstone" neural rendering technologies to take your game to new levels of fidelity and performance.

AMD FSR "Redstone" SDK 2.3 brings ML-powered FSR Upscaling 4.1.1 to AMD Radeon RX 7000 Series GPUs, along with Frame Generation 4.0.1 and Ray Regeneration 1.2 improvements for…

The AMD FSR Redstone SDK enables developers to integrate neural rendering technologies, including ML-powered upscaling, frame generation, denoising, and radiance caching, for…

Download the AMD FSR plugin for Unreal Engine, and learn how to install and use it.

The new AMD Radeon Developer Tool Suite release delivers RGP 2.7 with shader source code viewing, instruction‑level divergence metrics, and Extended PIX Marker support, expanded…

Practical guide to fusing GEMMs on AMD RDNA™ 4 architecture, covering WMMA layout, a transpose-by-swapping A/B technique, HIP sample code, and hipBLAS-verified results used in…

AMD Schola v2.1 deepens Unreal Engine integration, adding StateTree support, Kubernetes-oriented distributed training, stronger Minari workflows, and much more to streamline…

AMD is partnering with Samsung on a multivendor Vulkan extension for Dense Geometry Format (DGF) to help enable dramatically smaller geometry, reduced memory/latency for…

AMD DGF SuperCompression (DGFS) cuts DGF geometry file sizes while preserving exact block reconstruction and enabling fast decode to either DGF blocks or conventional meshlets for…

It is often difficult to know where to start when taking your first in the world of graphics. This guide is here to help with a discussion of first steps and a list of useful…
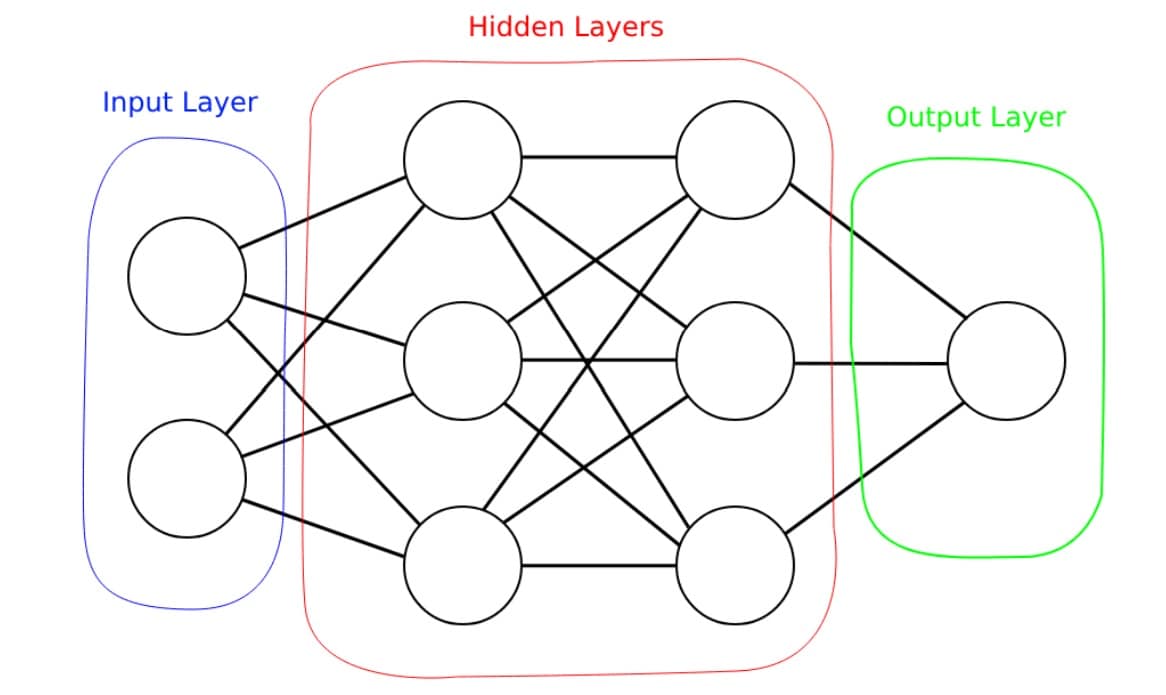
If you're a graphics dev looking to understand more about deep learning, this blog introduces the basic principles in a graphics dev context.
 | WMMA guide for AMD RDNA 4 architecture GPUs - part 3Learn how to implement fast in-register matrix transpose on AMD RDNA™ 4 architecture GPUs with a WMMA-based identity trick, delivering a lightweight, memory-free alternative proven in Llama.cpp. |
 | WMMA guide for AMD RDNA 4 architecture GPUs - part 2Achieve peak AMD RDNA™ 4 architecture memory bandwidth for low-precision GEMM by fusing WMMA to double the K dimension, enabling 128-bit loads for FP8/INT8, and matching hipBLAS results bit-for-bit. |
 | Introducing MiniDXNN: MLP library for DirectX 12MiniDXNN is a native HLSL and DirectX 12 library for lightning-fast MLP inference leveraging AMD Radeon™ RX 9000 series matrix cores via cooperative vector APIs, delivering optimized kernels, samples, full source and docs to remove compute interop friction. |
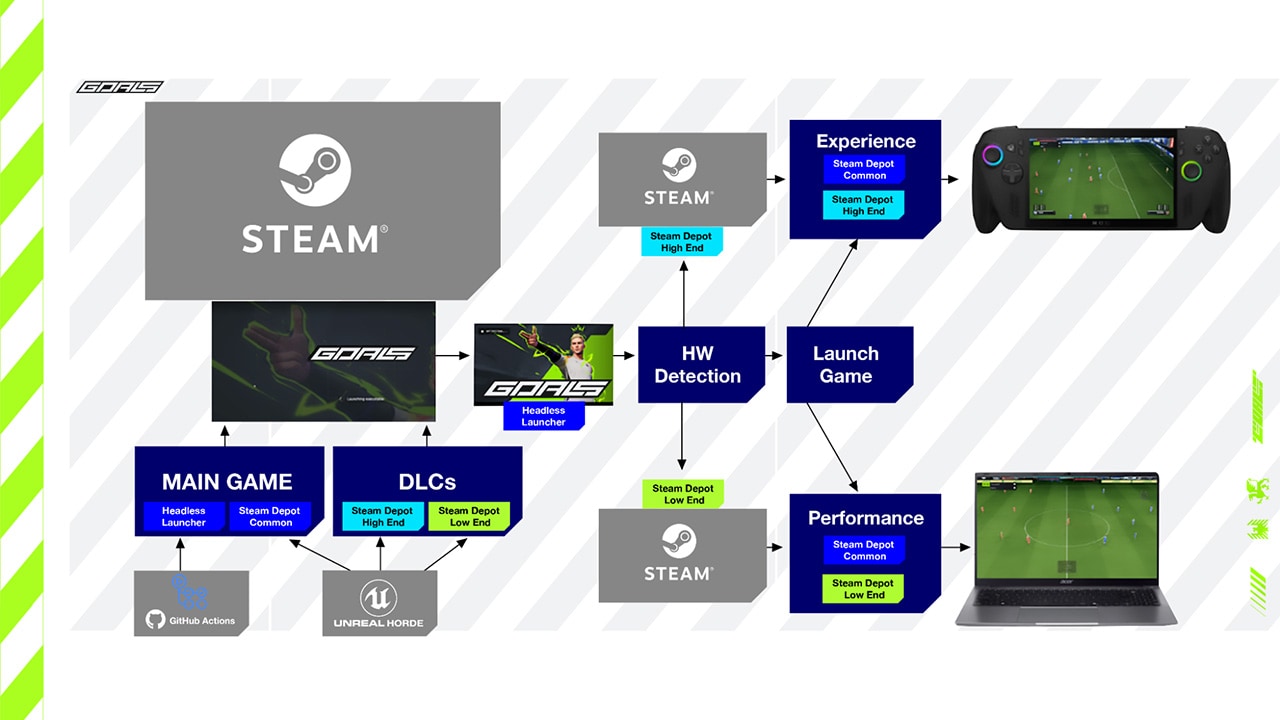 | How GOALS delivers sustained, competitive esports performance on handheld PCs - part 1The first part of a developer-first look at how GOALS leverages AMD Ryzen APUs and the ADLX SDK to implement a system that reduces power, fan noise and carbon footprint across legacy and handheld hardware while preserving competitive performance. |
 | How GOALS delivers sustained, competitive esports performance on handheld PCs - part 2The second part of how GOALS optimizes AMD Ryzen handheld PC gaming performance using AMD FSR Upscaling and Frame Generation, handcrafted device profiles, football-aware animation budgeting, and battery-aware scalability for sustained play. |
| Welcome to the AMD FSR SDK 2.2, now available on GPUOpenThe AMD FSR™ "Redstone" SDK 2.2 update delivers ML-powered FSR Upscaling 4.1 and FSR Ray Regeneration 1.1 optimized for AMD RDNA™ 4 graphics, enabling higher visual fidelity and performance with analytical fallbacks to scale across handhelds, consoles, and PCs. |
 | Enhancing DirectX Testing with AMD SmoldrSmoldr is an open-source command-line tool that runs DirectX 12 HLSL shaders from simple text scripts, letting you compile, create resources and pipelines, and dispatch compute or raytracing workloads without writing C++ code. |
 | AMD and Microsoft partner on DirectX ML, DirectStorage, and developer tools at GDC 2026Microsoft and AMD partnered at GDC to announce powerful new developer technologies for Windows, including DirectStorage 1.4, PIX tools updates, DirectX ML integration, Advanced Shader Delivery, and support for the latest Agility SDK update. |
 | Driving the future: frictionless automotive HMI development with Epic Games & AMD Ryzen AI Embedded P100 seriesAt CES 2026 Epic Games and AMD unveiled the Unreal Engine 5 Next‑Gen HMI Experience powered by AMD Ryzen AI Embedded P100 Series, unifying instrument clusters, maps, and apps into a single high‑performance UE5 instance with gaming‑class graphics, and a streamlined developer workflow to deliver customizable, 60 FPS in‑cockpit experiences. |
 | HIP Threads: GPU power for teams without GPU expertsHIP Threads lets C++ teams eliminate CPU hotspots by running familiar multithreaded code on AMD GPUs, no kernel rewrites or GPU expertise required, delivering real speedups in days. |
 | Dyson Sphere Program - new multithreading dev log & full AMD Ryzen Threadripper PRO breakdownYouthcat Games overhauled the Dyson Sphere Program game's multithreading system, boosting performance by up to 88% through custom core binding, dynamic task allocation, and enhanced thread synchronization. |
| AMD FSR™ Redstone expands with the latest AMD FSR™ SDK 2.1AMD FSR 'Redstone' SDK 2.1 enables developers to integrate FSR features into games with easy-to-use APIs and access to advanced neural rendering technologies. |

The AMD FSR SDK 2.1 is the launch vehicle for our ML-based neural rendering technologies. It includes AMD FSR Upscaling, our cutting-edge ML upscaler, plus AMD FSR Frame Generation for smoother gameplay, AMD FSR Ray Regeneration for noise-free ray tracing, and AMD FSR Radiance Caching for efficient real-time global illumination - all using hardware-accelerated features of AMD RDNA™ 4 architecture.
The original AMD FidelityFX SDK v1.1.4 contains our series of optimized, shader-based features aimed at improving rendering quality and performance.


Building something amazing on DirectX®12 or Vulkan®? How about Unreal® Engine?
Obviously you wouldn't dream of shipping without reading our performance and optimization guides for Radeon, Ryzen, or Unreal Engine first!

We aim to provide developer tools that solve your problems.
To achieve this, our tools are built around four key pillars: stability, performance, accuracy, and actionability.
