
Now available: AMD FidelityFX SDK 1.1.4 patch release (includes FSR 3.1.4)
This FidelityFX SDK update has FSR 3.1.4 fixes – including reduced upscaler ghosting in newly disoccluded pixels, plus updates to Brix GI and Breadcrumbs.




This FidelityFX SDK update has FSR 3.1.4 fixes – including reduced upscaler ghosting in newly disoccluded pixels, plus updates to Brix GI and Breadcrumbs.

AMD Schola lets you train RL-based AI NPCs with Unreal Engine.

We now support new Microsoft® DirectX® and video encoding features, with the latest release of the AgilitySDK Preview Release 1.716.0.
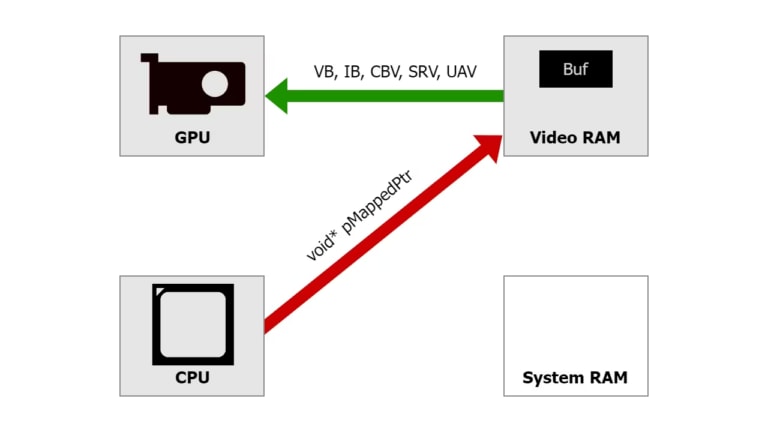
The D3D12_HEAP_TYPE_GPU_UPLOAD flag in Direct3D 12 provides a good alternative to other ways of uploading data from the CPU to the GPU. Check out our quick guide to effective use of this flag.

The AMD FidelityFX SDK is now available! The SDK is AMD FidelityFX graphics middleware helping you to integrate AMD FidelityFX features into your games without any hassle.

Compressonator v4.4 adds AVX-512, AVX2, and SSE4 variations of BC1 encoding in the Compressonator Core library, new CLI options, and more.

AMF v1.4.30 provides AMF wrappers for AVC/HEVC/AV1 FFmpeg software encoders, and frame in -> slice/tile output support for the same. Plus multi-monitor support for DVR + more!
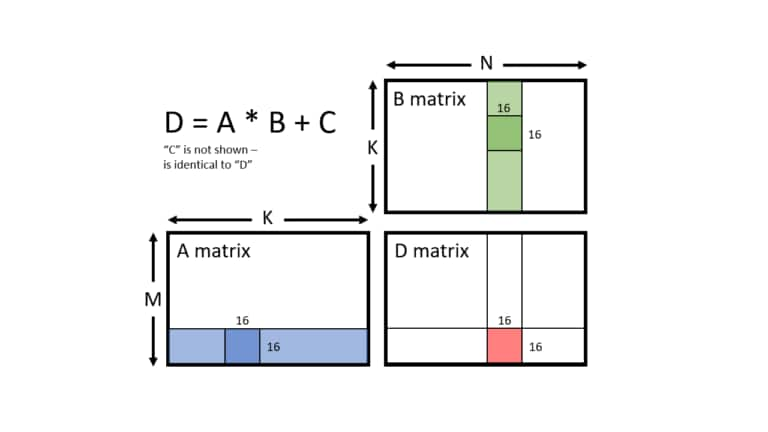
Read about how the new WMMA instructions added in HLSL SM 6.8 allow shader developers to accelerate GEMM matrix operations.
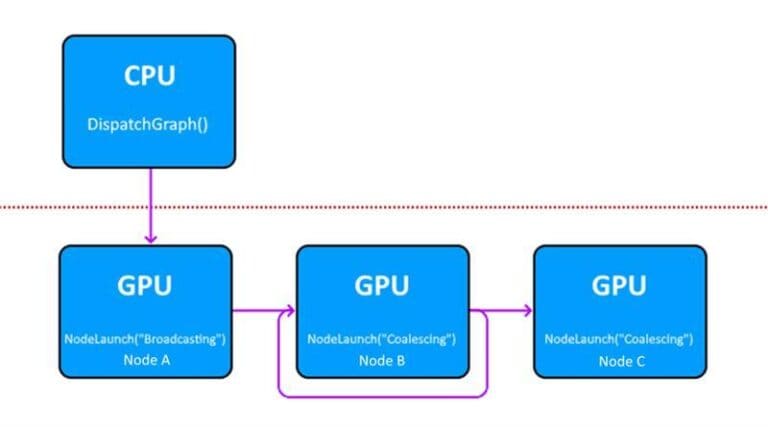
Our primer on GPU Work Graphs introduces this exciting new paradigm for graphics developers, which enable a live shader kernel to dispatch new workloads on-demand without needing to circle back around to the CPU first.

Read about our improvements to AMD FidelityFX Super Resolution 2 with the FSR 2.2.1 hotfix.

MPI is the de facto standard for inter-process communication in High-Performance Computing. This post will guide you through the process of setting up an MPI application that supports execution on GPU clusters.

Read about how the latest updates for our Radeon ProRender plug-ins introduce HIP, and how this can benefit artists.

AMD now has driver support for a metacommand implementation intended to improve performance and reduce the time it takes to generate output from the model.